
Schema.orgのMicrodataとは
Microdataとは、メタデータを既存のページコンテンツに追加する構造化マークアップの1つであり、これを利用することで検索エンジンにコンテンツの目的を理解させ、ユーザーにより豊富な検索結果を提供することができます。
構造化メタデータ活用のメリットの詳細やさまざまなマークアップ言語の種類については、DeepCrawlの テクニカルSEOライブラリの記事をご覧ください。
Googleがサポートする構造化データ
Googleは以下を含むさまざまな種類の構造化マークアップをサポートしています。
企業情報: 会社概要、ロゴ、コンタクト情報、ソーシャルメディアが表示されます。
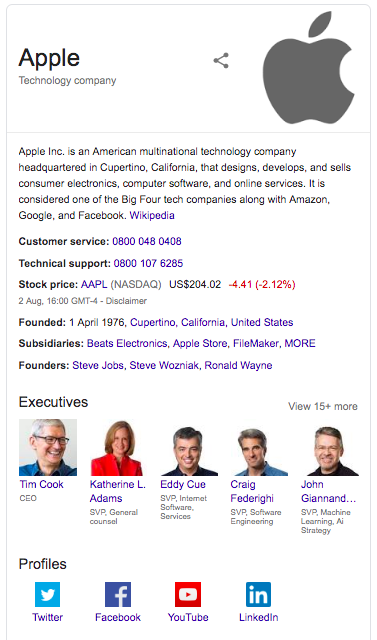
イベント: 登壇者や演者、イベント会場、そしてチケット販売サイトでイベントに関する日付、時間、場所、その他関連情報を表示する場合に役立ちます。設定すると、この情報をGoogleのイベント検索機能で表示させることができます。

リッチスニペット:商品情報、レシピ、レビュー、イベント詳細(通常の検索結果上)、動画のサムネイルやニュース記事の情報を表示することができます。
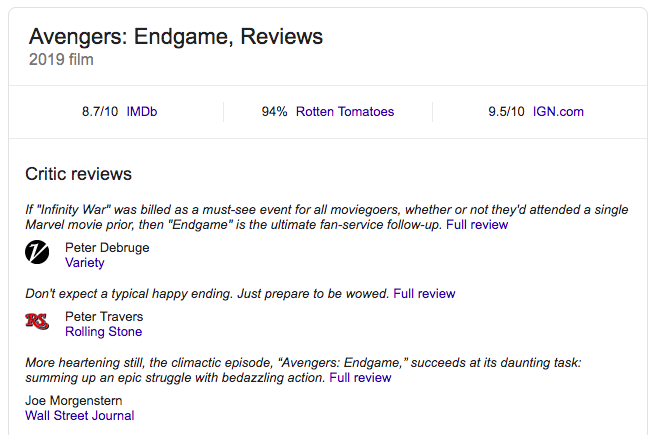
パンくずリストとサイト検索ボックス: ユーザーが求める情報に直接アクセスできるようになります。
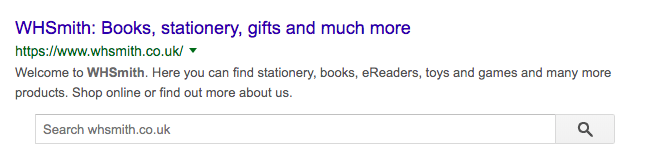
こちら(英語)で、構造化マークアップで追加できる全ての記述のリストを確認することができます。
BingとYandexがサポートする構造化データ
Bingでは現在パンくずリスト、企業組織情報、イベント、人物、商品オファー、レシピレビューに対するマークアップをサポートしています。詳細については、 Bingのマークアップ概要(英語) をお読みください。
Yandexでは住所と組織情報、動画、FAQ、ソフトウェアや映画に対するマークアップをサポートしています。商品と価格、レシピとブログ記事やオーディオ作品を含むクリエイティブコンテンツも同様にサポートしています。詳細については、Yandexのschema.orgガイド(英語)をご覧ください。
構造化マークアップの実装方法
ページ内マークアップを使用して、対象の情報をもつページのHTMLに構造化データを追加してください。一般的にはページのhead部分にコードを実装しますが、body部分に追加することもできます。
構造化マークアップの使用における実装とガイドラインの詳細については、Googleの構造化データに関するガイドをご覧ください。
さまざまなマークアップ方法
Schema.orgのマークアップはmicrodata, RFDa, JSONの3つの方法で実装することができます。
Microdata
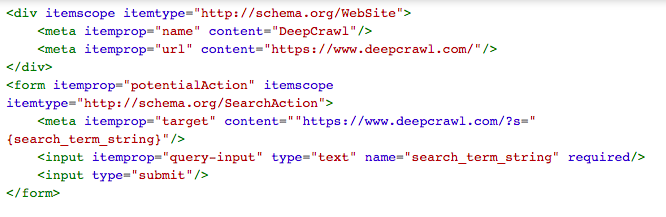
Microdataは既存のHTMLコンテンツにタグ属性を追加する場合に使用されるオープンコミュニティ仕様です。
MicrodataのWebsite(サイト)タイプの構造化マークアップ例は以下のようになります。
RDFa
RDFa (Resource Description Framework in Attributes)とは、埋め込みマークアップシンタックスを使用するHTML5の拡張機能であり、これを使うことでリンクされたデータがユーザーが実際に目にする形で検索エンジンに伝達できます。
RDFaのPostal Address(住所)タイプの構造化マークアップ例は以下のようになります。

JSON-LD
JSON-LD(JavaScript Object Notation for Linked Data)はページの構造化マークアップ実装にあたりGoogleが推奨している形式です。これは、新しい種類の構造化データのほとんどがまずこの形式で出力されるためです。JSON-LDはblockcodeとして提供されるので、ページのコンテンツと簡単に分割することができます。
JSON-LDのOrganization(組織)タイプの構造化マークアップ例は以下のようになります。
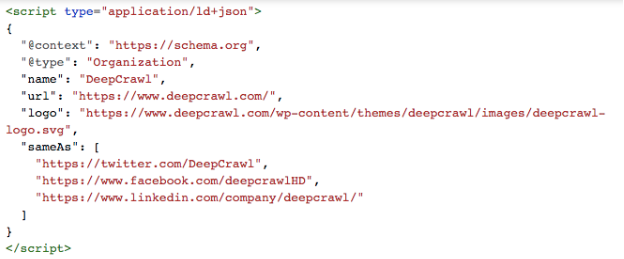
DeepCrawlを使用したスキーマタグの監査とモニタリング
DeepCrawlのカスタム抽出機能を使うことで、Microdata, RDFa, JSONを含む複数のの構造化タグの確認と抽出を行うことができます。構造化タグがあるページに加えて最後のクロールにて追加または削除された構造化タグを表示するので、サイト監査にかかる時間の削減に役立ちます。
カスタム抽出での構造化タグの抽出
カスタム抽出の設定は、クロール設定の詳細設定内で行うことができます。
The Custom Extraction settings are found in the fourth step of the crawl setup under Advanced Settings.
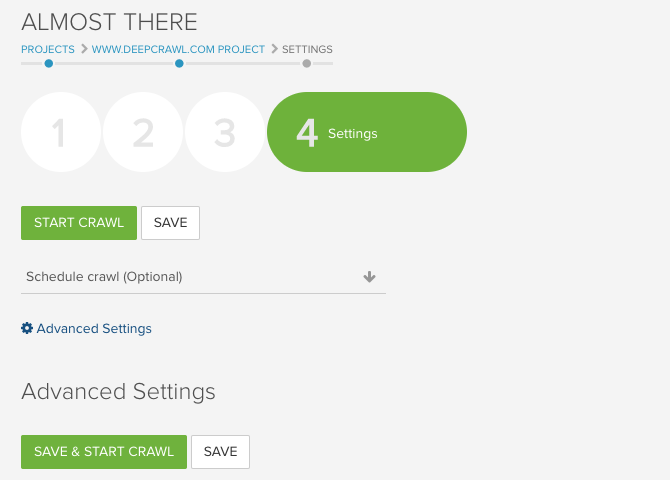
構造化タグの確認と抽出を行うには、詳細設定>カスタム抽出>新しい抽出ルール、で表示される正規表現抽出ボックスに、対応する正規表現のルールを入力してください。
構造化タグをカスタム抽出するための正規表現
DeepCrawlでの構造化タグの抽出にそのままお使いいただけるよう、タグの形式ごとに正規表現を作成しました。
Microdata のみ:
microdata:
(itemtype=["']http://schema.org)
microdata-itemtype:
itemtypes?=['"s]?http://schema.org/([^"s']*)
RDFA のみ:
rdfa:
(vocab=['"]http://schema.org/['"])
rdfa-typeof:
typeof=['"]([^"']*)"
JSON のみ:
json-ld:
(<script type=['"]application/ld+json['"]>)
json-ld-type:
['"]@type['"]s?:s?['"]([^"']*)
例としてツール上ではJSON-LDタイプのカスタム抽出が以下のように表示されます。
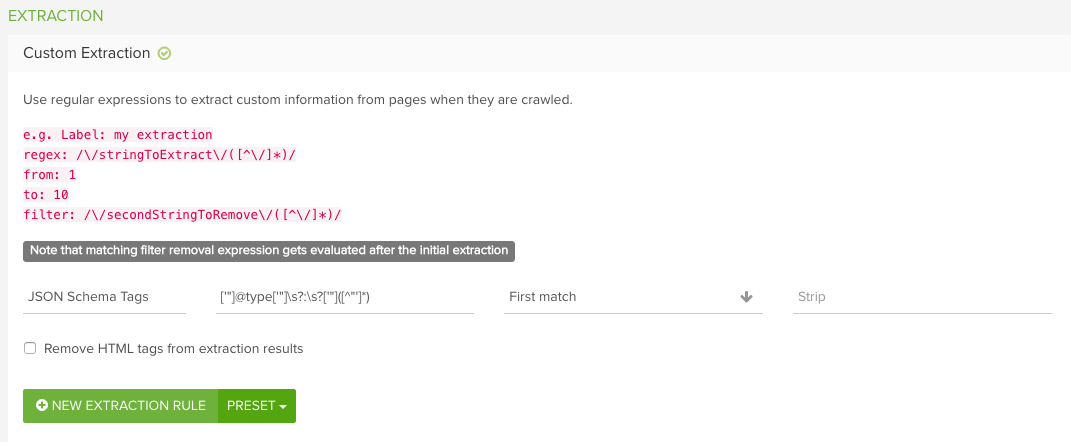
正規表現のルールを使用する詳細については、DeepCrawlの正規表現入門ガイドをご覧ください。
混在した構造化フォーマットの検出
1つのページにMicrodataとJSON-LD両タイプが使用されていると、管理が煩雑になり実装や保守を複雑化する可能性があるという理由から、Googleはこれを避けるよう推奨しています。
Mixed_Schema_Formats:
itemtype="http://schema.org/.*?conte(x)t"s?:s?"http://schema.org"|conte(x)t"s?:s?" http://schema.org".*?itemtype="http://schema.org/
カスタム抽出レポート
クロールが終了したら、ツール左側のナビゲーションにカスタム抽出レポートが表示されます。
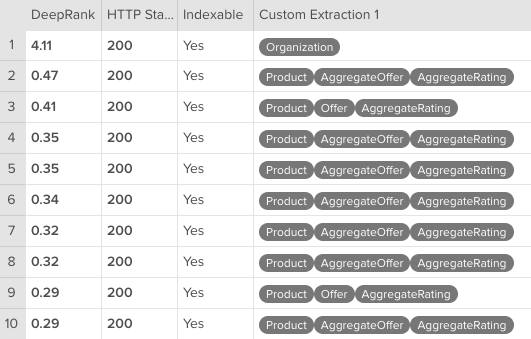
このレポートを使うことで、各ページで検出された構造化マークアップの種類を主要な指標とともに一画面で確認することができます。
構造化タグのテストと有効化
構造化タグの抽出はサイト上のタグの位置を把握するのに便利ですが、そのタグが有効でなければ意味がありません。以下のツールを使うと、構造化データの設定と実装時に発生するであろう問題の特定に役立ちます。
構造化マークアップのモニタリングの重要性
検索エンジンにおいて多くの検索結果が表示されている画面で自社サイトが埋もれないようにするためには、構造化データが正しく実装されているかしっかりと確認することが重要です。これは特に、現在の掲載順位が競合他社より高くない場合は有効な施策です。場合によっては、リッチリザルトがサイトへのより有益なクリックに繋がる(英語)場合もあります。そのため、実装したタグのモニタリングと分析を継続して行うことで、検索結果にユーザーが求めるサイトのコンテンツを表示し、関連性のあるユーザーをサイトへ導くことが大変重要となります。
カスタム抽出について詳しく学ぶ
カスタム抽出とは、アナリティクス、ソーシャルタグ、バックリンク、商品情報やその他の様々な要素を確認する場合に便利な強力なツールです。
また、こちらのガイドで詳細を説明しているChromeのページ速度に関するパフォーマンス指標を収集する際に役立ちます。

