サーバーログファイルは、検索エンジンボットがサイトをどのようにクロールするかという貴重な情報を提供しますが、多くの場合見落とされ十分に活用されていません。
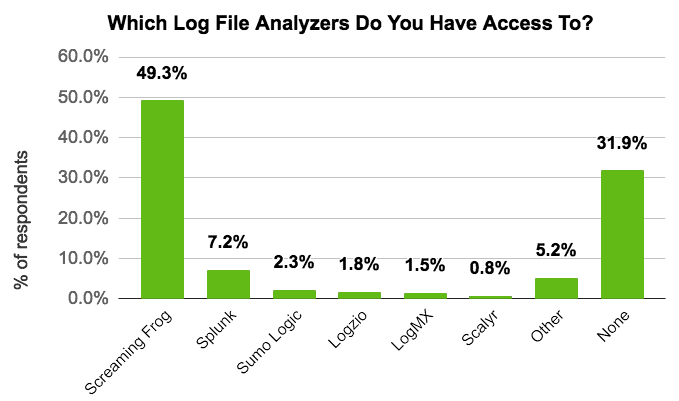
サーバーログファイルは、検索エンジンボットがサイトをどのようにクロールするかという貴重な情報を提供しますが、多くの場合見落とされ十分に活用されていません。現在、さまざまな予算に応じた多様なログファイル解析ツールが利用可能であり、DeepCrawlのユーザー調査では、666人の回答者中68%が既にログファイルデータへアクセスしていることが明らかになりました。
サーチマーケティング担当者がログファイルを最大限に活用できるように、DeepCrawlでは柔軟なログファイル連携機能を備えています。
DeepCrawlでは、ログファイル解析ツールのサマリデータをアップロードして、追加費用無しでクロールソースとして追加することができます。
クロールにログファイルデータを追加
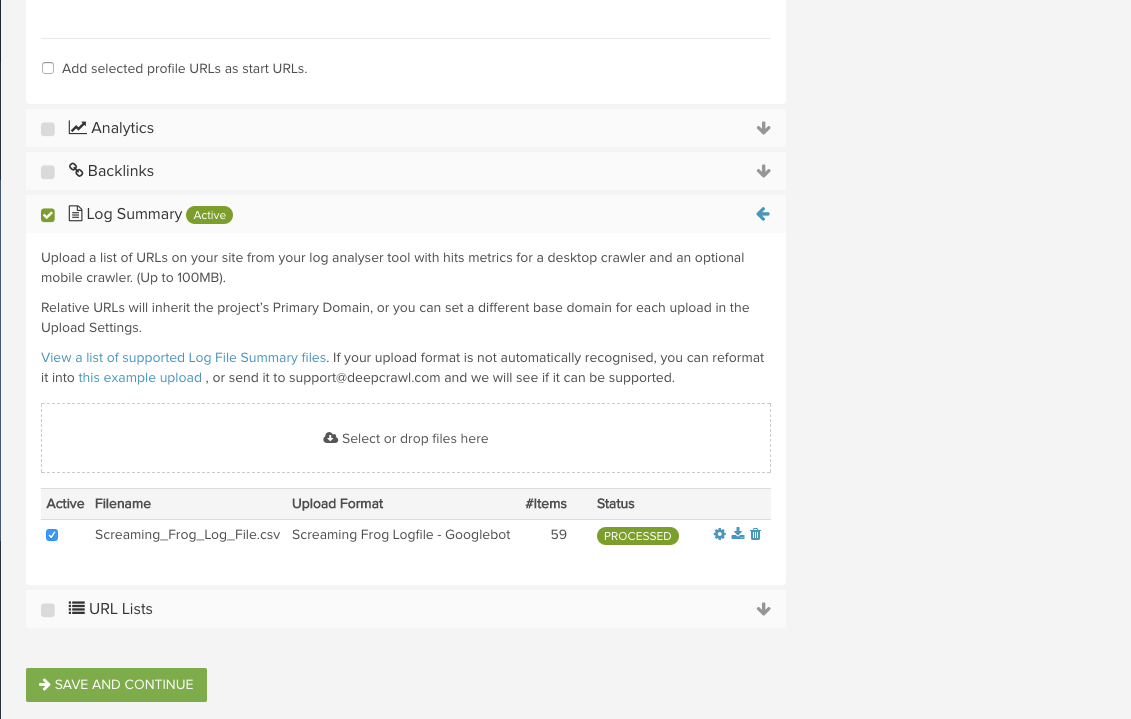
DeepCrawlとログファイルデータの連携方法はとても簡単です。サポート対象ソースのアップロード方法のガイドをご覧いただき、Screaming FrogやSplunkなどの主要なログファイル解析ツールのサマリデータのアップロード方法をご確認ください。
まず始めに、使用しているログファイル解析ツールにアクセスして、指定した日付範囲のサマリデータをエクスポートしてください。DeepCrawlのウェビナー(英語)で、Stone Temple社のEric Enge氏は、標準として1ヶ月分のサーバーログファイルデータを、もしサイトに大量のトラフィックとボットからのリクエストがある場合には1週間分を処理することを推奨しています。
サマリデータをエクスポートしたら、DeepCrawlを開き、クロール設定のステップ2でデータを追加して、新しいクロールを設定します。ログファイルツールが出力したファイル形式をDeepCrawlがサポートしていない場合は、support@deepcrawl.jpまでお問い合わせください。
DeepCrawlではクロールのソース設定にGoogleサーチコンソールやAnalyticsなどのデータを追加することを推奨しています。これにより、DeepCrawlを最大に活用することができます。クロールのセットアップが完了したらクロールを起動し、結果を確認してください。
DeepCrawlとログファイルデータの連携で可能になること
DeepCrawlとログファイルデータを連携することで、どのようなことが可能になるのでしょうか。詳しくご説明します。
クロールが終了すると、数多くの新たなログファイル関連のレポート、指標、グラフが使用可能になります。以下では、使用例をいくつかご紹介します。
検索エンジンボットからリクエストを受けているページと受けていないページの特定
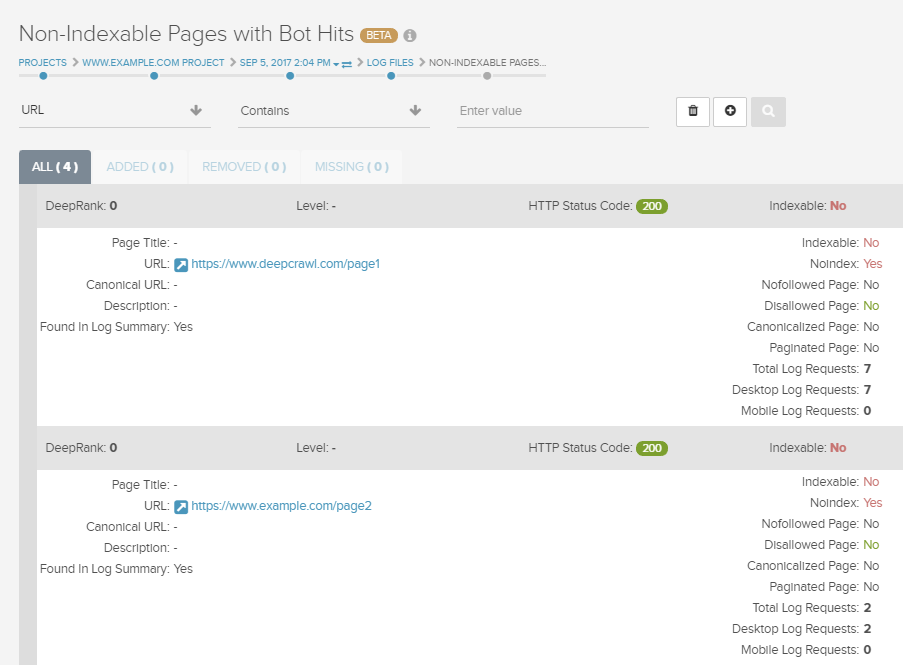
クロールソースとしてログファイルを追加すると、検索エンジンボットからリクエストを受けているページとそうでないページを確認できます。
以下の2つのレポートでは、サイトの検索エンジンにおけるビジビリティを把握することができます。
- ボットのリクエストがないインデックス可能ページ:検索エンジンがインデックス可能と識別しているが検索エンジンボットからリクエストを受け取っていないページを表示します。
- ボットのリクエストがあるインデックス不可ページ:検索エンジンがインデックス不可と識別しているが検索エンジンボットからリクエストを受け取っているページを表示します。
これらのレポートに表示されたページを調査して問題の修正を行うことで、検索エンジンにサイト上のページを表示させてクロールバジェットが効率的に使用されるようにしましょう。
サイト上のページが検索エンジンのボットからリクエストを受ける頻度の把握
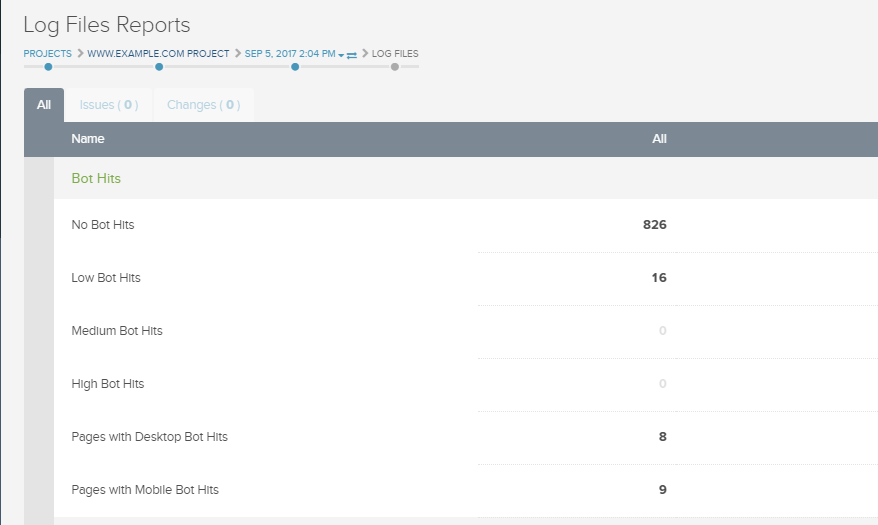
DeepCrawlの4つのレポート(高、中、低、リクエストなし)では、検索エンジンのボットがサイト上のページにリクエストする頻度についての洞察を提供します。
これらのレポートを使うことで、最も重要で頻繁に更新されるページが定期的にボットにクロールされているか確認できます。それらのページが定期的にクロールされていない場合は、インデックスさせたいページが検索エンジンにとって見つけやすいようにサイト構造を見直したり、meta robotsタグの使用を再検討してみると良いでしょう。
さらに、クロール頻度グラフでは異なる4つのクロール頻度カテゴリにおけるページ割合を見やすく可視化します。
サイトマップのクロール頻度の把握
サイトマップがクロールされる頻度を確認すると、検索エンジンがサイトの最新コンテンツをどのくらいの頻度で確認するのか知ることができ、また検索エンジンから見たサイトの質を把握できます。
クロール頻度が低いサイトマップの場合、インデックス不可のページが含まれていないことを確認したり、新しいページのみを含む個別サイトマップに分割したりすると良いでしょう。
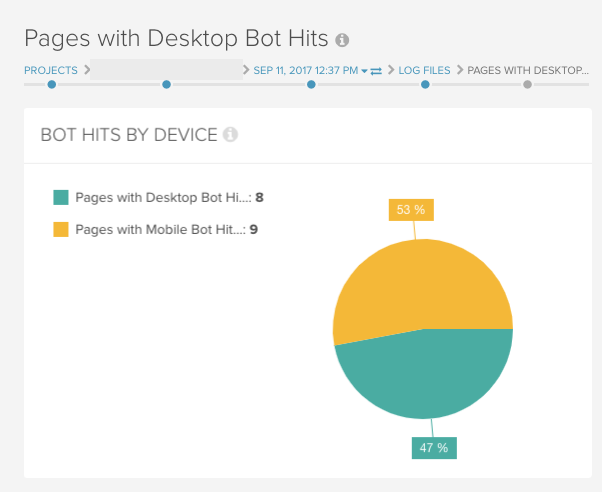
各ユーザーエージェントがどのようにデスクトップサイトとモバイルサイトをクロールするか把握する
DeepCrawlのログファイル連携を使うことでサイトへのモバイルとデスクトップボットからのリクエストを分けることができます。
このようにログファイルデータを分けると、適切なユーザーエージェントがサイトの特定のバージョンをクロールしているかどうか確認することができ、モバイル設定を有効化することに繋がります。このようにログファイルデータを分けると、適切なユーザーエージェントがサイトの特定のバージョンをクロールしているかどうか確認することができ、モバイル設定を有効化することに繋がります。
クロールバジェットが浪費されていませんか?
最後に、ログファイル連携を使うことで、クロールバジェットが浪費されている部分を見つけ出すことができます。ログファイルデータを追加すると、リダイレクトチェーン、ステータスコードが3xx/4xxのページ、インデックスできないページなどのリクエストを受けるべきではないページがボットからのリクエストを受けている状況にあるURLを発見できます。
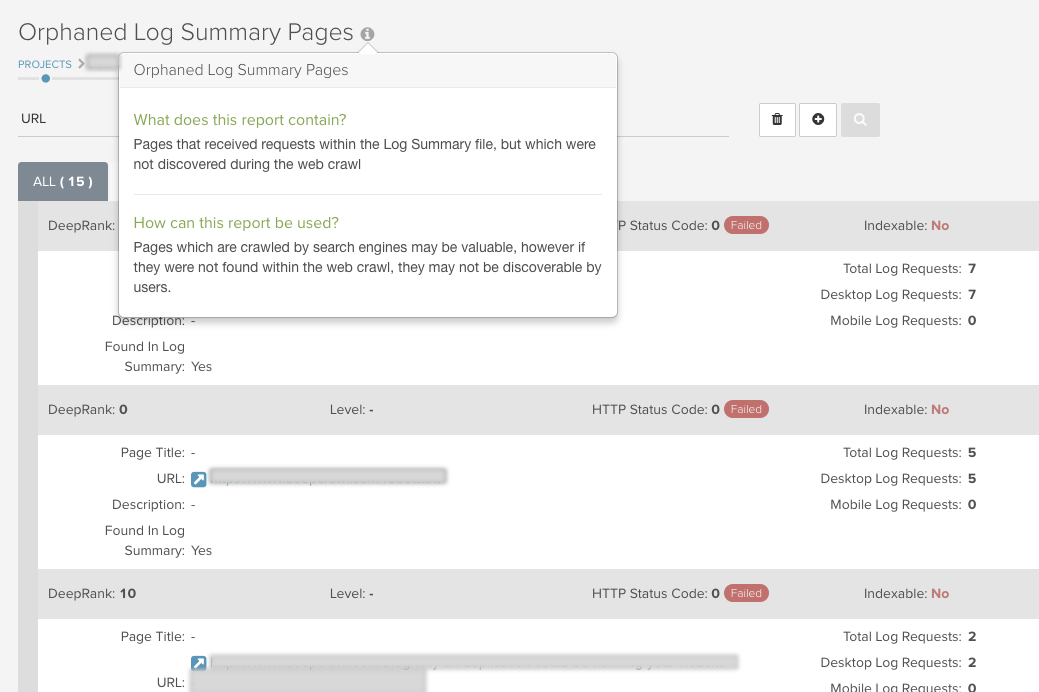
孤立ログサマリーページのレポートはボットからのリクエストを受けている孤立したページ(ウェブクロールにリンクされていないもの)を検出します。これらのページの価値を再考し、これらをインデックスさせるかどうか、させるのであればこれらのページに内部リンクを追加する必要があるかを判断することができます。
ログファイル連携でより良いクロールを
DeepCrawlのログファイル連携にはさまざまな用途があるので、早速試してみてください。DeepCrawlを初めて使用する場合、ぜひクロールソースにログファイルを追加してみてください。使い慣れている方も、次のクロールにはログファイルサマリを追加してみてください!
ログファイルデータがない場合には、deepcrawl-support@gmotech.jpまでお問い合わせいただければ専門のコンサルタントが、アドバイスや質問にお答えします。
トレーニングウェビナーを観て、ログファイル連携を最大に活用しましょう(英語