
robots.txtファイル は熟練のSEO担当者であっても注意を要するものです。たった1つの文字の間違いが、サイトパフォーマンスへの甚大な影響を及したり、サイト全体をクラッシュさせたりすることさえあり得るからです。記述と変更
そしてこれはその担当者の間違いのせいでないことも多々あります。同じサイトに対してたくさんの人々が作業をしている場合、メンバー間で通知なく変更された1点がエラーとなってしまうことは珍しいことではないからです。
何か問題が発生した際にサーチコンソールは非常に役立ちますが、問題が起こらないように自社サイトを適切に保護したい場合には、しっかりとしたシステムを用意しておく必要があります。この記事ではrobots.txtファイルを比較的容易に記述、編集、管理する方法に関して説明していきます。
変更の前にすること:検証の繰り返し
1.許可しないURLの決定
まずはじめにすべきことはrobots.txtファイルの中でどのURLを許可しないか決めることです。DeepCrawlのようなクローラーを使って全てのURLのリストをダウンロードし、検索エンジンにクロールさせたくない価値の低いページを探してください。
以下の点を忘れずに対応してください。
- 追加のルールを作成し、既存のrobots.txtファイルに追加する
- 矛盾するルールがないか確認する
- きるだけ最小のルールで、できる限り細かく指定できるように簡易化する
GoogleサーチコンソールやBing Webマスターツールには、robots.txtを記述するにあたって膨大な情報があります。
2.Robots.txtファイルが正しくdisallowできているかの確認
サーチコンソール > Robotsツールを使用して、修正したrobots.txtでURLの一覧をテストしましょう。このツールでは実際のGooglebotとは少し異なるAllowルールが適用されることを覚えておくようにしてください。Googlebotの動作では定義されていないようなエッジケースがいくつかあります。
3.本番環境に移行する前に新しいrobots.txtファイルでの検証
DeepCrawl詳細設定のRobots.txt上書き機能を使って本番用ファイルをカスタムしたものに置き換えましょう。
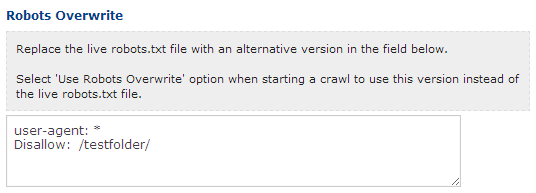
次回クロールを始めるときには、このrobots.txtファイルを本番用の代わりに選択することができます。
新規追加/削除された許可されていないURLのレポートにより、変更されたrobots.txtによりどのURLが影響を受けたか正確に把握し、とても簡単に評価することができます。
4.ステージング環境の検証(任意)
すべてのURLをdisallowしてインデックスを防いでいるrobots.txtファイルをもつステージング環境をクロールしたいという場合は、robots.txtファイルをAllowで上書きしてください。例えば、以下のようになります。
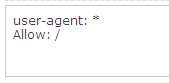
5. “隠れた”許可されているページを検証(発展編)
DeepCrawlやその他クローラーのデフォルト設定は、許可されていないページのクロールを実行しない設定となっています。そのため、許可されていないページに隠れている新しい許可されたページが検出されない可能性があります。
最初の階層にある許可されていないページをクロールしてその下位層にあるページを検出するには、[詳細設定 > クロール制限]で詳細な設定を行ってください。

この方法を行なったとしても全ての許可されていないURLを完全に把握することはできません。これを実行するには、まず、robots.txt上書き機能を使って上記で述べた全てのURLを許可するrobots.txtファイルを使用し、クロールするしかありません。これにより、制限なしですべてのURLを検出した上で、本番のrobots.txtファイルを使って再度クロールすることができます。
こうすれば、クロールには含まれないURLを全て検出することができます。
変更後にすること
1.robots.txtファイルの変更をトラックしておく
Robotto のようなツールを使って、robots.txtファイルが変更された際には常にアラートを出すようにしておきましょう。これにより変更時にはいつでもその変更点とそれがサイトにもたらす影響を把握することができます。
2.許可されていないURLを確認する
Googleサーチコンソール[インデックス > インデックスステータスレポート] でrobots.txtにおける変更点がサイト上の許可された、または許可されていないURLへ大きく影響を及ぼしたかどうか確認してください。
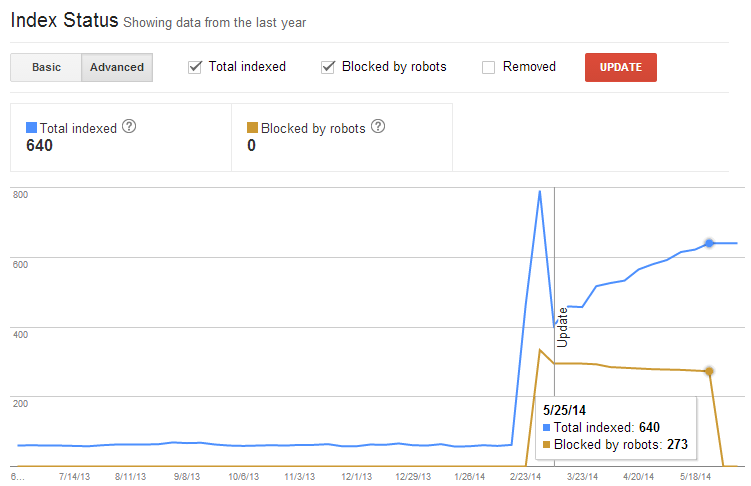
一方で、この方法では許可されていないURLの特定の情報を取得することはできません。これを行うには、DeepCrawlの許可されていないURLのレポートを活用してください。許可されていないURLはクロールされないがゆえに、膨大な量のURLがあったとしてもクロールクレジットを消費しません。
3.キャッシュの問題を検証する
Robots.txtのサーバーキャッシュに関する問題が発生している場合、Googleが実際に見えているものとは異なるrobots.txtファイルを検出している可能性があります。Googleサーチコンソールの[クロール > Robots.txtテスター]で現在Googleのどのバージョンが利用されているか、どれに対してどのようなURLが指定されているか、また将来的に発生する変更などを確認してください。
問題が発生するようであれば、問題につながる行がハイライトされます。
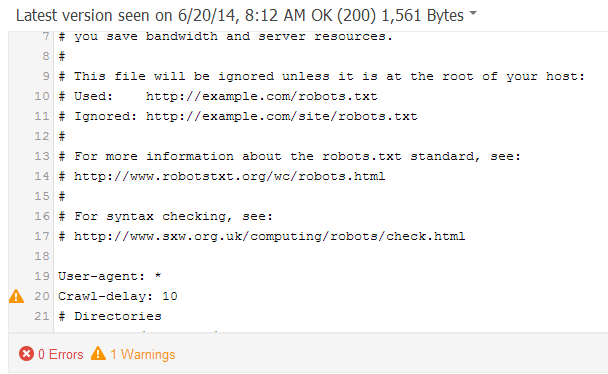
画面右側で[公開済みのrobotx.txtを表示する]をクリックし、これのキャッシュ済/編集済のバージョンと本番用のものを比較してください。.
4.robots.txtのサイズを確認する
robots.txtファイルのサイズが500KBを超える場合、Googleがそれを全て処理しない可能性があります。しかし、意識して対処すればこれよりファイルサイズが大きくなるようなことはあまりないでしょう。ファイルサイズがこの制限を超えているかどうか確認し、もしその場合には他に大きな問題が発生していないか確認しましょう。
5.ユーザーエージェント専用のrobots.txtファイルを確認する
robots.txtファイルはGoogle, Bing, またはその他向けにカスタマイズされていることがあり、この場合は検証が非常に難しく、何か問題が発生するリスクが生じています。
robots.txtファイルをURL 検査ツール(旧名称:Fetch as Google)ツールを使って、Googleの目線ではなにが見えているのかを正確に把握するようにしましょう。
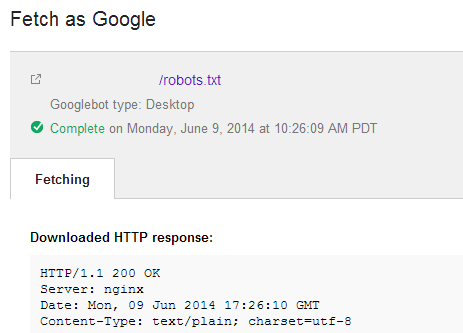
同じファイルを、BingウェブマスターツールにあるBingボットとしてフェッチするツールを使って確認することもできます。
最後に、DeepCrawlとしてフェッチするツールを活用して、様々なユーザーエージェントでrobots.txtファイルの変更点を検証できます。
まだDeepCrawlのアカウントをお持ちでなければ、ぜひ無料ライアルでお試しください。か、今すぐログインしてみてください。

