
定期的なクロール実行は、サイト上で発生する想定通りの変化と予期しない変化の把握に非常に役立ちます。
一方で、「設定していたことを忘れて」しまうことが孕むリスクは、サイトを毎回同じ設定でクロールしてしまうということです。これはつまり、1つの観点からしかサイトを分析していないということであり、そのために他の様々なユーザーエージェントやユーザーにとって明らかに重大な問題に対しサイトを未対応のまま見逃してしまう可能性があるということです。
問題点を把握するために、サイトのパリティ監査の実施をおすすめします。この監査では連続してクロールを行い、その差異を比較することで実行中の(単発の)クロールでは検出されない問題を把握することができます。DeepCrawlのチームは、デスクトップとモバイル間およびJavaScriptのパリティを検出する2種類のパリティ監査を定期的に行なっています。
デスクトップ/モバイルユーザーエージェントのパリティクロールとは?
モバイルファーストインデックスが発表された際、モバイルファースト対応への変更時にサイトのパフォーマンスを妨げる可能性のあるサイト上の問題を検出するという点で、デスクトップ/モバイルのパリティ監査は注目を浴びました。
では、サイトがすでにモバイルファーストインデックス対応となっている場合は、なぜこれを考慮する必要があるのでしょうか?
それは、サイトをモバイルファーストインデックスに対応させたというだけでは、デスクトップ版ユーザーエージェントがサイトをクロールしないということにはならないからです。
Googleは依然としてデスクトップ版クローラーでクロールを実施しており、サイトのデスクトップ版とモバイル版コンテンツは一致させる必要があることを明確に示してきました。両バージョンのコンテンツが一致していないと問題になります。
モバイルファーストインデックスについての議論で混乱を生みやすい要因の1つは、レスポンシブサイトとユーザーエージェントの関係性です。
一部のサイトでは、画面のサイズに合わせてページの非視覚的要素や視覚的コンテンツを変更しています。これはこれで問題となる可能性がありますが(上記リンク参照)、これはパリティ監査の対象ではありません。パリティ監査で把握したいのは画面サイズによるコンテンツの違いではなく、ユーザーエージェントに応じたコンテンツの変化です。
ユーザーエージェントに対するパリティクロールの方法
ここまで、通常のGooglebotとスマートフォン用Googlebotのサイト解析方法の違いを理解することの重要性をご説明しましたが、実際どのようにこれらを比較すれば良いのでしょうか。
まずはじめに、ユーザーエージェントを除いて同じ設定が行われた2回クロールが必要です。DeepCrawlでは監査用の新規プロジェクトを設定し、実行するクロールの種類に合わせた名前(例:DeepCrawlデスクトップ/モバイルパリティクロール)を付けました。

DeepCrawlでは、通常初回はデスクトップ用ユーザーエージェントでサイトをクロールしていますが、どちらを先に実行するかは全く重要ではありません。デスクトップクロールが終了したらプロジェクト設定に移動し、スマートフォン用ユーザーエージェントに変更して再度クロールを行います。。2回目のクロールが終了したら、データ分析を行います。
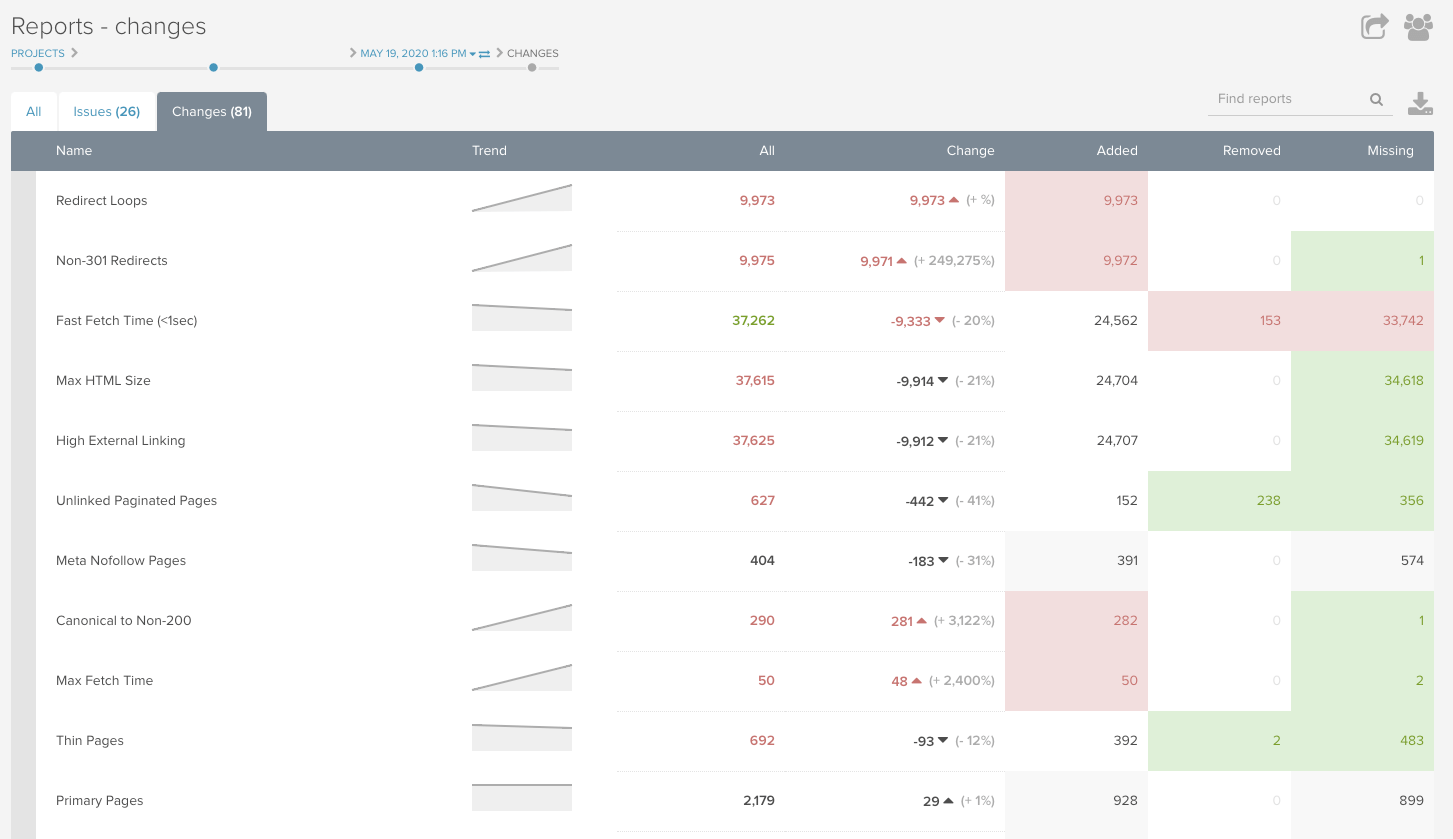
次に、両方のクロールの同じレポート項目を見比べて、差異を確認しましょう。DeepCrawlの前クロールからの変化を表すレポートは簡単に見分けられるように差異を表示してくれるため、非常に便利な機能です。
デスクトップ/モバイル間のパリティ監査でわかること
DeepCrawlでは、デスクトップとモバイル間のパリティ監査でざまざまな種類のエラーを検出し、修正してきました。以下では、クロール分析時に確認すべき項目をいくつかご紹介します。
文字数やヘッダータグの変化
サイトのデスクトップ版とモバイル版で文字数に差異があることが多々あります。モバイルでは画面サイズが小さいという点で、一部のコンテンツが削除される可能性があることも納得がいきます。しかし、バージョン間で削除されるコンテンツを把握することは重要です。モバイルユーザーエージェントがコンテンツにアクセスできない場合はそのコンテンツはランキング要素になりません。ヘッダータグについても同様です。
フェッチ時間やカスタム抽出
ページ表示速度は、特にモバイルユーザーにとって重要な要素です。DeepCrawlのツールにはフェッチ時間を高速、中速、低速と速度別に把握する能力があり、パリティクロールでの差異の把握に役立ちます。より詳細な指標に関しては、クロール実行前に詳細設定を行ってCore Web Vitalsをカスタム抽出することができます。
DeepCrawlのチームは、スキーマや特定のページ上コンテンツの取得のためにカスタムJavaScriptやカスタム抽出も頻繁に利用しています。
例えば、デスクトップとモバイル間のクロール結果を比較するために、カスタム抽出を活用してカテゴリページ上の商品数を取得することができます。在庫切れにもかかわらずインデックス可能な商品ページや、H1タグ内に”cats”という単語があるページを取得することもできます。
カスタム抽出とカスタムJavaScriptを駆使することで、無限に比較対象を広げていくことができます。
ウェブクロール深度の変化
デスクトップ版とモバイル版のユーザーエージェントは、ナビゲーションとフッターでリンクが違うなどの大きく異なるページテンプレートに何度もアクセスすることになります。
デスクトップ上ではホームページから数クリックで到達可能なページが、モバイル上ではさらに多くのクリックが必要である、またはその逆の状態などを把握できます。
DeepCrawlのダッシュボードの ”ウェブクロール深度” チャートを使用すると、2つのクロール間でのリンク構造の違いを検出できます。
次の例では、重要なページの大多数がモバイル版クロールでは8クリック目にあるのに対して、デスクトップ版クロールでは5クリック目にあります。ここではリンク構造に問題があるということになります。
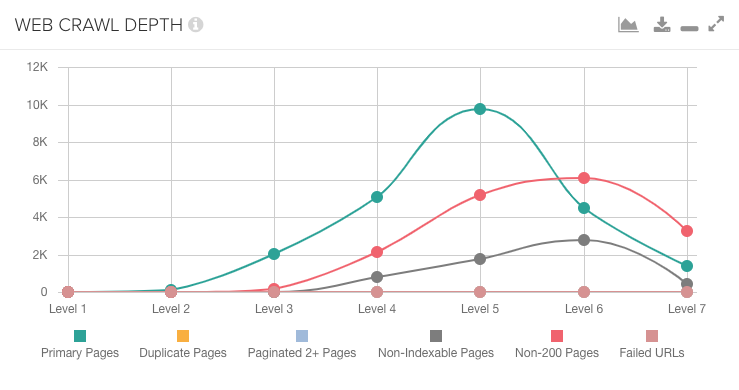
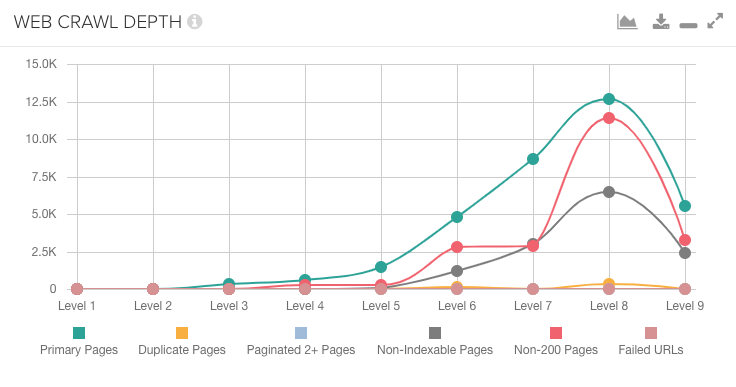
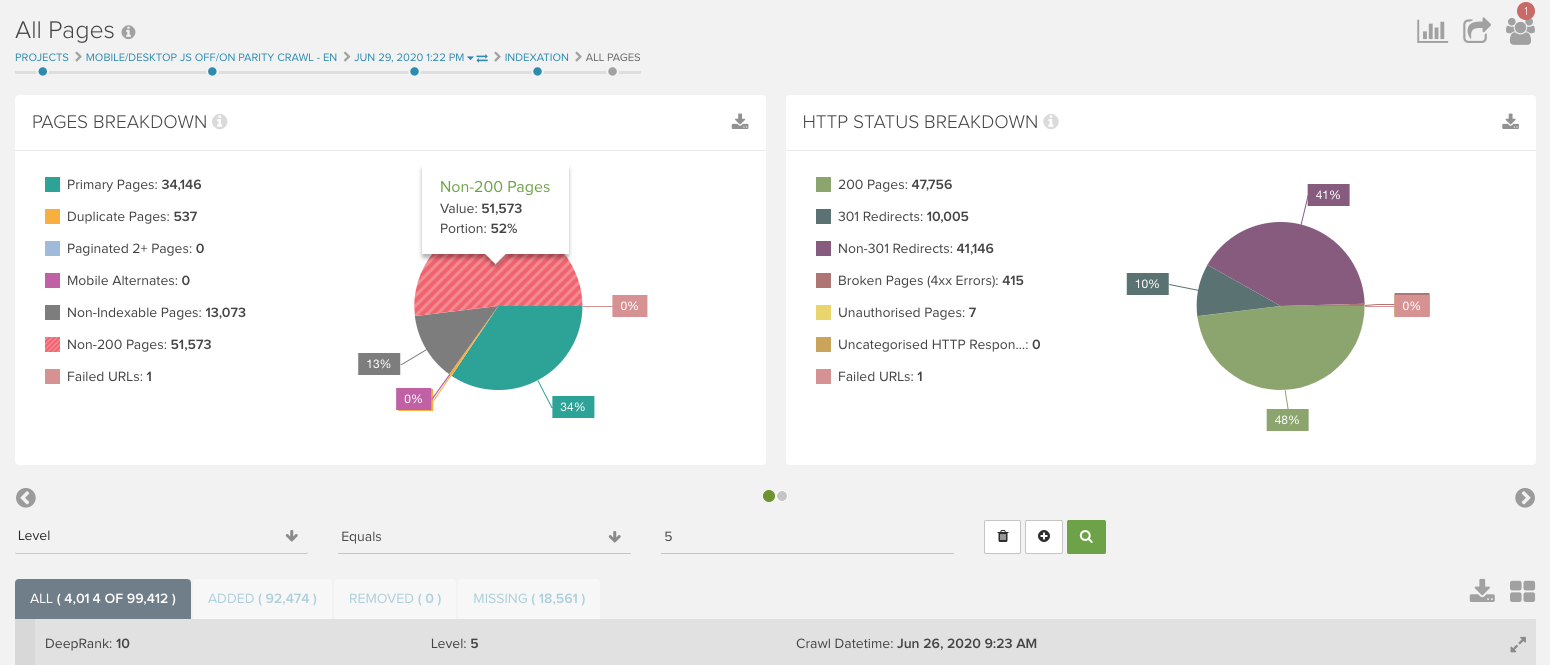
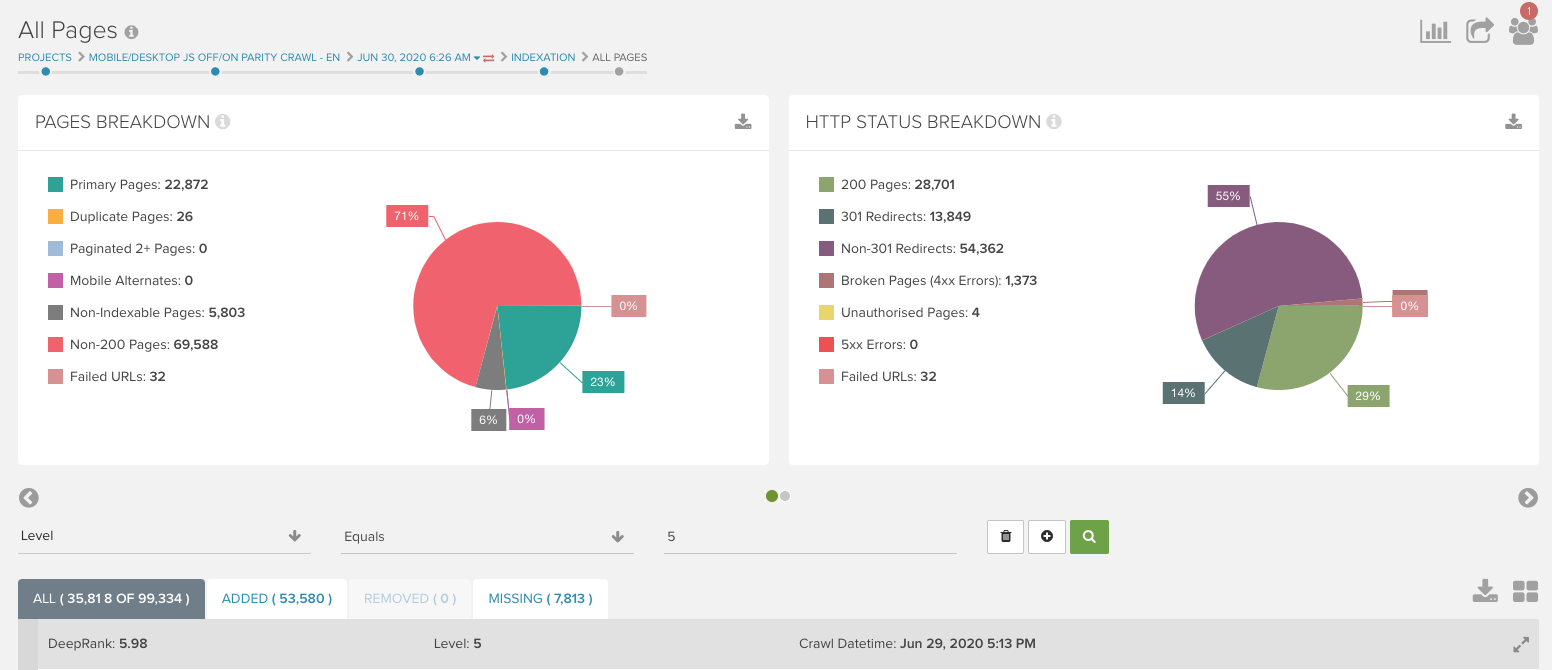
ウェブのクロール深度に大きな違いがあることが分かったら、各クロールのすべてのページに表示されるレポートに階層フィルターを適用して、どのページタイプに変更があったか確認してください。
URLのセグメントを使ってグルーピングしているプロジェクトの場合は、2つのクロール間で階層に変化があるセグメントを確認することができます。ここで変化した内容を精査し、修正方法を決定できます。
JavaScriptのパリティ監査
JavaScriptがサイトへ与える影響についてご存知でしょうか?
数年前は、検索エンジンがJavaScriptをレンダリングできなかったために、SEOではJavaScriptの使用を避けることが中心的に推奨されていましたが、現在ではこうした方法は適切とは言えません。
JavaScriptは多くの大手ブランドのサイトで欠かせないものとなり、GoogleはJavaScriptのレンダリングに対応しています。ただ、それでもJavaScriptがSEOにおける問題となり得る点がたくさんあります。サイト上でJavaScriptのパリティ監査をするべき3つの理由は次の通りです。
理由1:HTMLのプリレンダリングが未だに重要なため
数多くのサイトが、canonicalやhreflang、内部リンク、noindexタグなどの要素の読み込みにJavaScriptを使用しています。
GoogleはJavaScriptのレンダリングができるようになったため、プリレンダリングされたHTMLで要素の読み込みを行う場合に、なぜJavaScriptレンダリングが重要なのか多くのSEO担当者が疑問に感じています。Googleや他の検索エンジンがJavaScriptをレンダリングできる場合、なぜ問題なのでしょうか。
例えばレンダーバジェットが理由の1つです。Googleはコンテンツのクロールとレンダリングが ”できる” というだけであり、必ずしも実際に “実行する” とは限りません。
そのため、ページがクロールされていてJavaScriptレンダリングは行われていない状態であれば、canonicalやhreflang、リンク、noindexタグは、ページのレンダリング後の状態と一致させていくことが重要です。インデックスさせたい他の要素に対しても同様で、JavaScriptがなければ表示されないものは、検索エンジンが検出できない可能性があります。
理由2:アクセシビリティ
スクリーンリーダーなどのアクセシビリティ検証ツールの多くはJavaScriptをレンダリングしないため、そのようなツールを使用するユーザーはJavaScriptによって表示されるコンテンツへアクセスすることができません。
単純にこうしたユーザーがコンテンツを利用できるようにすることの他にも、近年ではアクセシビリティ検証に準拠しないサイトを対象とした訴訟が増えてきているということも考慮しましょう。
JavaScriptレンダリング前後で確実にコンテンツが表示されるようにすることで、ユーザーの離脱や訴訟の発生を未然に防ぎましょう。
理由3:古すぎるJavaScriptは想定外の動作をする、または全く機能しない可能性があるため
JavaScriptは非常に長い間、サイトには欠かせないパーツとなっています。
実際に、サイト上のJavaScriptはかなり昔から存在するため、古くて役に立たないコードがサイト上に隠れているかもしれません。
このような古いコードはせいぜいページの表示速度を遅らせる要因となるくらいであり(ページ上に存在すればリソースを浪費する)、最悪の場合には想定しない方法でページを妨害する可能性があります。JavaScriptの有無による差異を詳細に分析すると過去のJavaScriptが浮き彫りになり、古いコードの削除に役立ちます。
JavaScriptパリティクロールの実施方法
もちろん、ページの状態を正確に把握するためにレンダリング前後のサイトのページを手作業で確認することもできますが、JavaScriptパリティクロールを実施すれば、追加で分析が必要なサイトの箇所の把握に役立ちます。
JavaScriptパリティクロールの設定は非常に直感的で、まずJavaScriptを有効化してクロールを実施し、その後JavaScriptを無効化してクロールするだけです。
DeepCrawlでは、クロールの種類を表す命名規則を使って新規プロジェクトを設定しました(例:JS 有効/無効パリティクロール)。それぞれのクロール間唯一の違いは、設定ステップ1のチェックボックスにチェックを入れるかどうかだけです。

両方のクロールが終了したら分析を始めましょう。DeepCrawlのプラットフォーム内にある変更点レポートは、トレンドの確認を始めるポイントとして有効なレポートです。
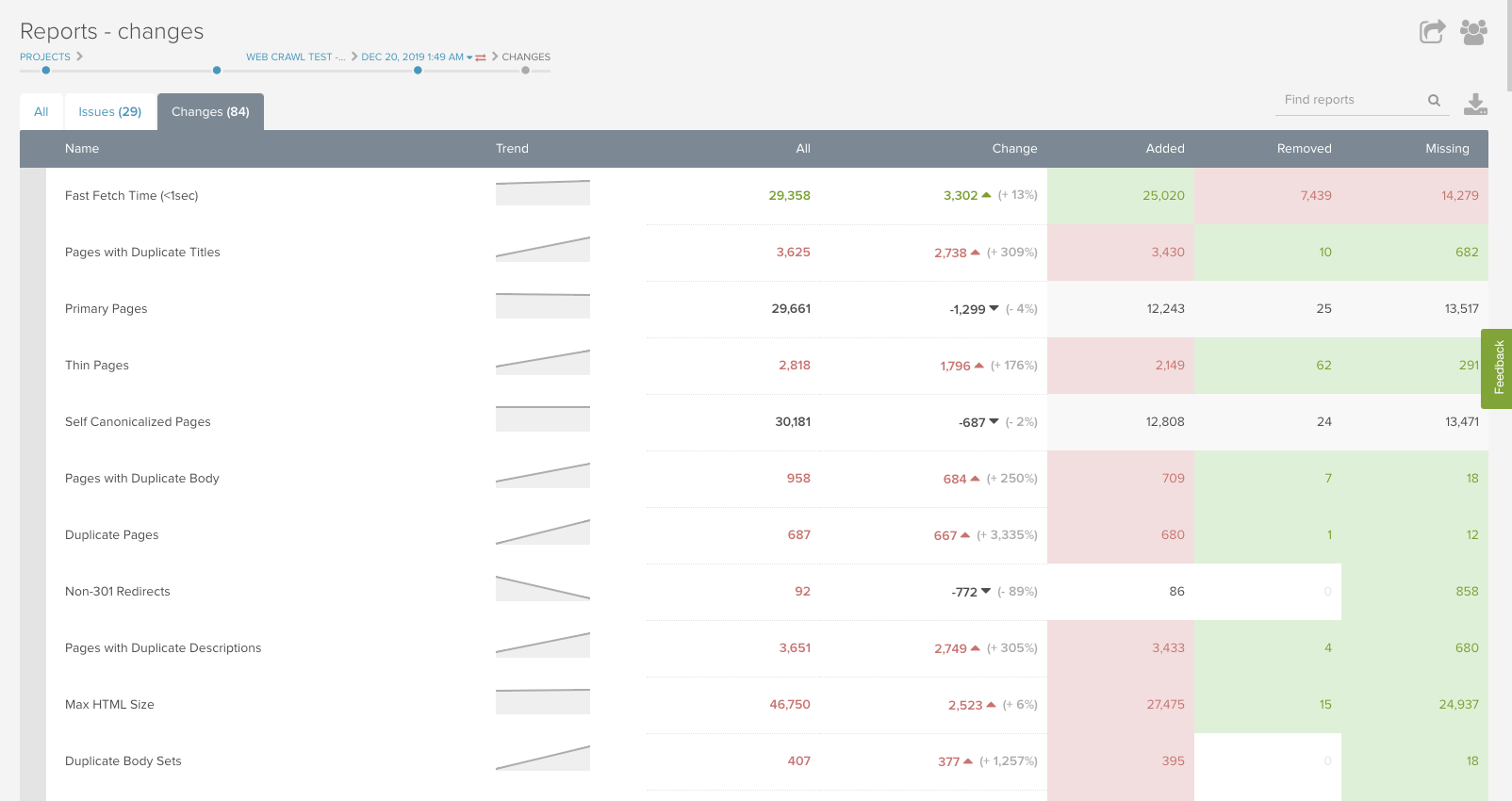
JavaScriptパリティ監査から検出できる問題点
DeepCrawlチームは、サイト分析のためにJavaScriptパリティ監査を頻繁に行っています。上記でデスクトップ/モバイルパリティ監査で言及した変化に加え、JavaScriptパリティ監査でチェックするべきいくつかの点を以下ではご紹介します。
正規化の変化
JavaScriptパリティ監査における最も一般的で注意が必要な問題は、正規化処理の変化です。自己参照を行うcanonicalタグやcanonicalタグの不足、正規化されたページなどの変化を調査しましょう。
DeepCrawlツールの ”レポート” セクション内または特定の正規化関連レポートを入力することでクロールトレンドを確認できます。
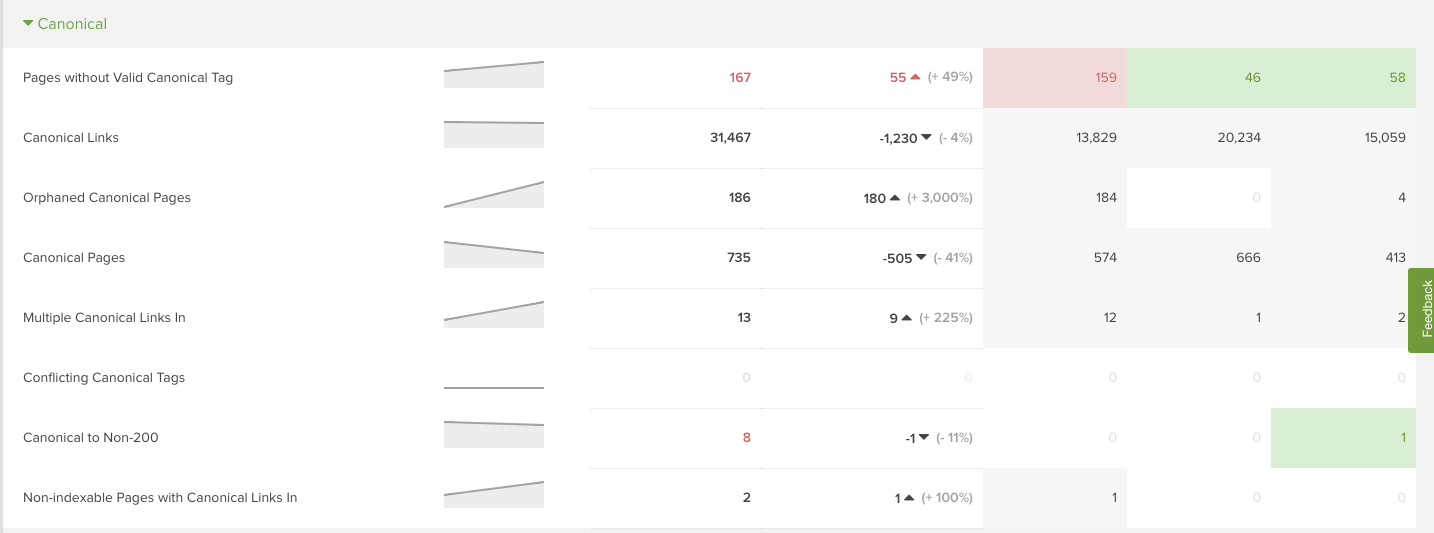
とある大手シューズブランドのサイトをJavaScriptオンでクロールすると、カテゴリページに正規化されたサブカテゴリページがありましたが、JavaScriptオフでそのサブカテゴリページにアクセスすると、JavaScriptオンでクロールした時のカテゴリページへ301リダイレクトされた事例があります。
つまり、JavaScriptが無効化された場合、ユーザーやクローラーはメインのカテゴリページしか見ることができないということになります。これは大問題です。
また別の事例では、とあるECサイトの一部のテンプレート上にレンダリング後だけ存在するcanonicalタグがあり、JavaScriptレンダリングを行わなければcanonicalタグが欠落した状態になるという場合もありました。
DeepCrawlチームは、”レポート” ページでこの問題を発見した後、”有効なCanonicalタグがないページ” 内の ”追加箇所” タブを使用してJavaScriptレンダリングなしでクロールされた場合にcanonicalタグが欠落したページを確認しました。
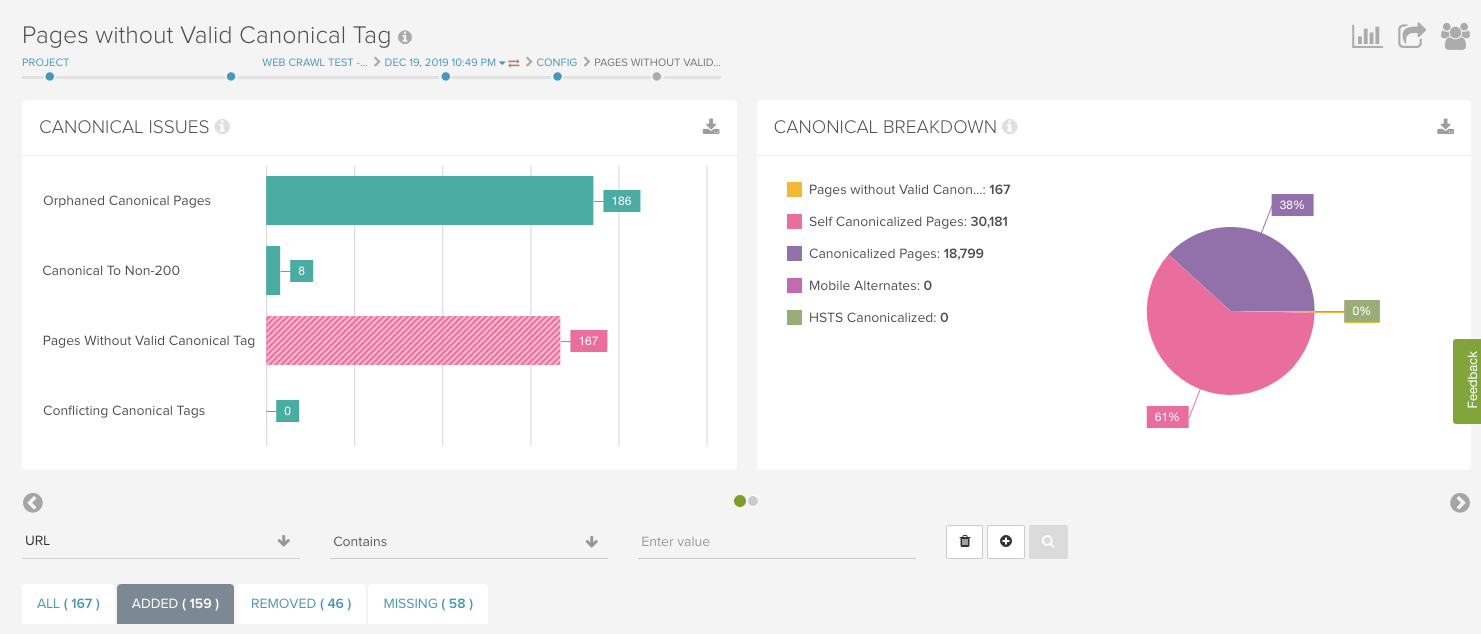
Noindexタグの不足
よくある問題としてもう1つは、動作をJavaScriptに依存するnoindexタグがある場合、またはnoindexを削除するJavaScriptを含むプリレンダリング済のページ上にnoindexタグがある場合です。これらの問題は”Noindex設定ページ”レポートで簡単に把握することができます。
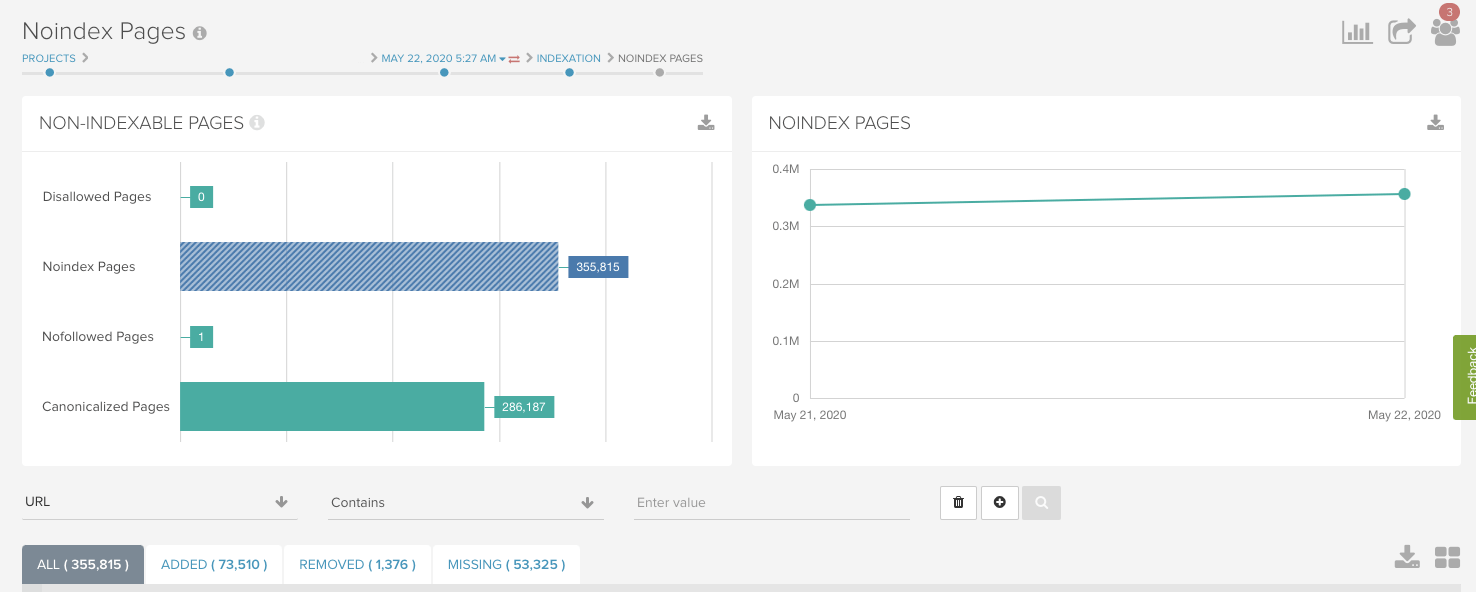
前述のシューズブランドのサイトには、JavaScriptレンダリングに依存するnoindexタグがありました。そのため、JavaScriptレンダリングが行われればページにnoindexタグが存在し、JavaScriptレンダリングが行われなければインデックス可能な状態になっていました。
コンテンツの変化
文字数やヘッダー、タイトル、メタディスクリプションなどのコンテンツ変更はJavaScriptのパリティクロールでよく検出される問題です。タイトルがない、ディスクリプションがない、空のページといった、コンテンツの不足に関するレポートを確認することをおすすめします。
次に、重複の問題を確認しましょう。
JavaScriptレンダリングが無効な場合、あらゆるテンプレートで ”フォールバック” が発生するため、タイトルやディスクリプションの重複が急増することが多々あります。例えば、JavaScriptがレンダリングされると全プロダクトページに個別のページタイトルがあることになる一方、JavaScriptがレンダリングされないとページタイトルがブランド名だけにフォールバックしてしまう、ということです。
この状態は、DeepCrawlでは重複タイトルとしてフラグ付けされます。
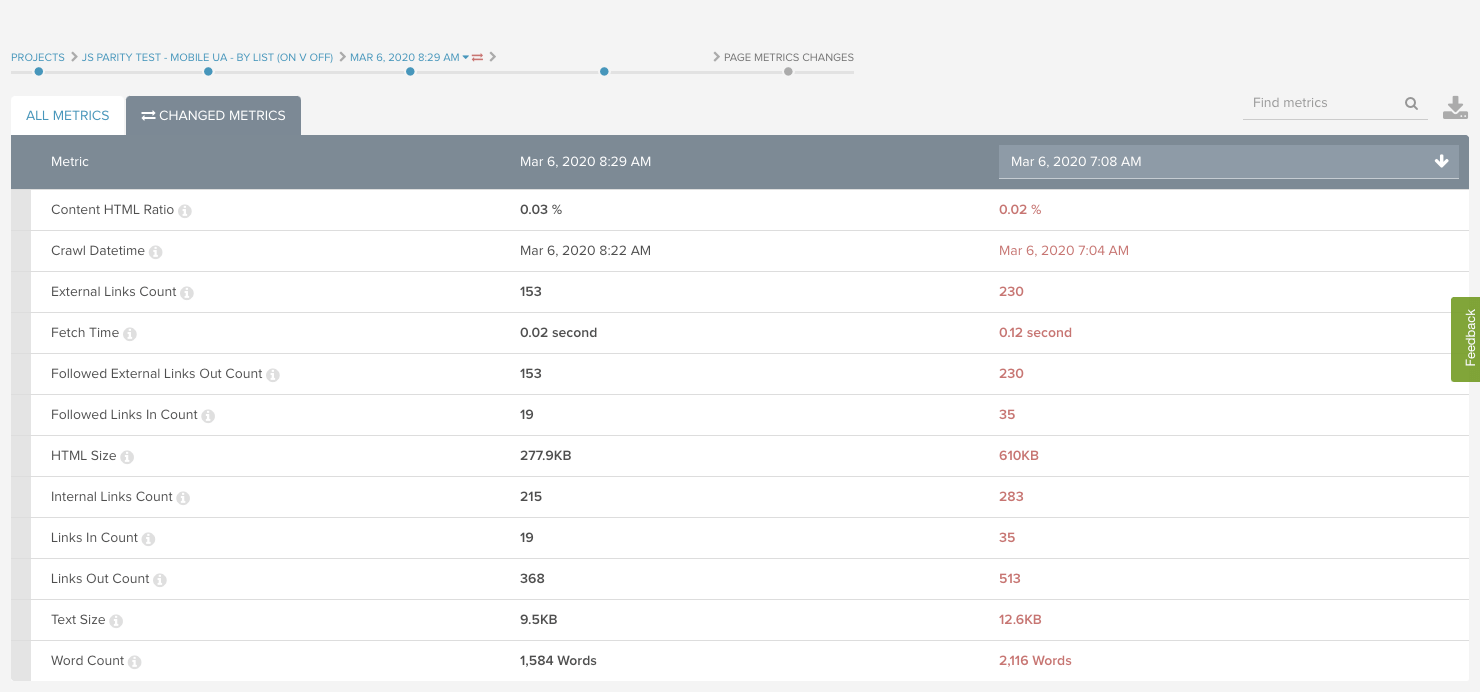
単語・文字数の変化は分析の難易度が少し上がります。1つのやり方は、各テンプレートからサンプルページを1つ抽出して、ページ差分機能を使用してクロール間での個々のURLを比較する方法です。この機能を利用するには、個別URLレポートをクリックして ”すべての変更を表示” を選択してください。
これは、あるフォーラムサイトでJavaScriptレンダリングが行われない場合にページ上の文字数にかなり大きな差異があった事例です。そのページはページ上の文字の実に25%をJavaScriptに依存していたということです。
同じテンプレートを使用するページで同様の文字数の変化がある場合は、ブラウザでその同テンプレートのページを分析しましょう。ChromeのWeb DeveloperやView Rendered Source のような拡張機能は、このように詳細な分析を行う際に便利なツールです。
リンクの変化
内部リンクと外部リンクの数も、レンダリング前後で劇的に変わることがあります。前述の単語数の分析を行う際には、リンクの変化も合わせて確認するようにしてください。
フォーラムサイトの例では、JavaScriptなしの状態と比較して、JavaScriptありの場合に発リンク数が29%増加することがわかりました。このことから、一部のリンクがクロール可能なリンクのベストプラクティスに準拠していないことがわかりました。
<head> 内のiframe
JavaScriptパリティクロールをしていて見つけた珍しい事例をご紹介します。
- JavaScriptを無効化してサイトをクロールした結果、canonicalタグやタイトル、メタディスクリプションを検出。
- JavaScriptを有効化してサイトをクロールした結果、canonicalタグやタイトル、メタディスクリプションが欠落していると判明。
- その後JavaScriptを有効化および無効化した状態でページのレビューを手作業で行うと、canonicalタグやタイトル、メタディスクリプションがすべて存在。
さて、何が起こっているのでしょうか?
問題は、<head>内にiframeが存在することにあります。
iframeはGoogleから<body>要素として認識されるため、iframeが<head>内で検出されるとGoogleは<head>が終了したと考え、以降すべてを<body>内の要素だと認識してしまいます。
canonicalタグやタイトル、メタディスクリプションはすべて<head>内に属する要素であり、<body>内では正しく機能しません。DeepCrawlは<head> 内のiframeを同様に解釈するため、iframe以後のすべての<head>要素が無視されてしまいます。
この問題の解決策は、<head>からiframeを削除することです。クローリングのための機能として、DeepCrawlにも、<head> 内の全要素をiframeの前に再配置するJavaScriptスニペットがあります。
もちろんこのスニペットは技術的な問題を解決するものではありませんが、コード修正が行われるまでの間、適切なクロールを行ってその他の問題をデータ分析することができます。
その他のパリティ分析
詳細なパリティクロール
大規模サイト(50,000URL以上)をクロールする際、完璧なサイト監査としては追加でいくつかクロールが必要な場合があります。
最初のクロールでは影響力の大きい問題を検出できますが、時としてこうした大量のデータを解析する初回クロールでは完全な検出が難しい問題点があります。
このような場合、何が発生しているかを正確に突き止めるために、DeepCrawlチームはURLのサブセットに対して新規プロジェクトを設定し、追加でパリティクロールを実施しています。URLのサブセットには、ページタイプ(カテゴリ/プロダクト/ブログ)や、あるパリティクロールで欠落していたページ、すべての重複レポートから抽出したサンプルページなどが含まれます。
例えば、シューズブランドのサイトをクロールしている際、JavaScriptパリティクロールで一部のカテゴリページやカスタムページに不可解な事象が発生しました。DeepCrawlではこれらのURLから400URLを抽出し、新規プロジェクトを作成して、以下のように4回にわたり追加的なクロールを実行しました。
- ”モバイルユーザーエージェント Javascriptオフ”
- ”デスクトップユーザーエージェント Javascriptオフ”
- ”モバイルユーザーエージェント Javascriptオン”
- ”デスクトップユーザーエージェント Javascriptオン”
クロールが完了した後の分析の手順は同じですが、分析対象の規模が小さいので初回のクロールでは捉えられなかった変化の原因を把握しやすくなります。
このシューズブランドの場合、JavaScriptのパリティクロールではすぐに判明しなかったいくつかの問題を検出することができました。
- 前述のiframeの問題が一部のパリティ変化の原因として検出された。そのiframeはJavaScriptレンダリングが有効なクロール時のみ<head>内に存在したことが分かり、この問題は今回の小規模なクロールを行ったことで判明した。
- 重要なページの1つがセキュアでないバージョンに正規化されていた。700,000ものページに対してたった1ページの変化は目立たないため、大規模なクロールでは発見が困難だった。
- 一部のカテゴリページにJavaScriptレンダリングによって変化するファセットナビゲーションがあった。これはカテゴリページの小規模サブセットにのみ適用されるものであり、小規模のクロールでこそ簡単に検出できる性質のものだった。
サイト規模や問題の種類によって、追加でパリティクロールを行う必要はないかもしれませんが、何かに問題があるように思われても正確にそれが何かを特定するのが難しい場合にこのようなクロールを行うと、非常に役立ちます。
ExcelやPythonでのパリティ分析
大量のURLに対してコンテンツやリンクの変化を分析する必要がある場合、フィルタをかけたURLのリストをエクスポートして、Excelでさらなる差異分析を実施することもできます。
これを実施するには、両クロール(デスクトップ/モバイルまたはJavaScriptのオン/オフ)のレポートまたはその一部をダウンロードして、EXCELのシートに追加し、URL上で各指標にVLOOKUPを適用してください。
”すべての変更点を表示” レポートと同じように、クロールでの差異を確認でき、さらに大量のURLを一度に比較できるというメリットもあります。さらに大規模なクロールの場合は、同様の分析をPythonで実施することができます。しかし、ほとんどの場合は追加分析のためのデータエクスポートを行わずに、DeepCrawlツール内でトレンドを把握することができます。
監査を実施してみましょう
DeepCrawlを活用したデスクトップ/モバイルのパリティ監査およびJavaScriptのパリティ監査は設定や実施が簡単です。実際、サイトのクロールの差異分析を行っている場合、すでにパリティ分析の手法には馴染みがあることでしょう。すぐに新規プロジェクトでパリティクロールを実行し、分析のための時間を節約しましょう。
整合性の監査を行うことでサイトが大きく変化させるような差異が常に見つかるというわけではありませんが、検索エンジンのページの評価方法の違いが検索結果におけるサイトのパフォーマンス成果を妨害していないことを確認すると、SEO業務の安心感を高めることができます。

