
テクニカルSEOの見地からのサイト監査は、SEOのプロと、初心者や偽の専門家を区別するスキルといえます。一般的なサイトの”ページタイトルの長さ”や”wwwリダイレクト”などのよくある不一致を検出できる手軽なツールがあふれている一方、それらのツールでは膨大なページを抱える大規模サイトで発生している問題を調査することはできません。.
これは、時間とともにサイトの規模が大きくなり、比例して修正点も増えてくるにつれて、どんなサイトでも複雑性を増していくということが原因です。サイト全体でページ追加や削除、修正が随時されており、開発チームやサイト管理者でさえ数ヶ月後には変更箇所がどこか把握するのが困難となるページもあります。
サイトのリンクジュースの流れを把握するには、まずボットのクロール方法を理解する必要があり、それがテクニカルSEOのすべてと言えます。Googlebotは必ずしもサイトのトップページから入って、最下層の商品ページから出て行くとは限らず、Googlebotは最も人気の高いページを経由し入ってきて同じページを繰り返しクロールする可能性があります。
これがクロールジュースとそのフローを解析する、すなわちボットがサイトとそのコンテンツをどのように巡回していくかを把握することが、極めて重要である理由です。
サイト隅々までのフローを知るためには、以下が必要になります。
- サイトの各部分を理解して、どのようにインデックスされているか調べる
- クロールバジェットを分析する
- サイトマップを監査する
- クロールエラーを修正する
- GoogleがJavaScriptをクロールする方法を分析する
各ステップを詳しくご説明します。この記事ではそれぞれの用語の意味の詳細な説明は避けて簡潔な説明を行い、SEOの中級から上級者向けの記事として要点に絞った説明をしていくことにします。
1.インデックス状況の確認
ステップ1:サイトを構成するページ種別やページテンプレートをすべて一覧にする。含まれる情報の例:
- ページのフッターに表示され続ける”プライバシーポリシー”や”利用規約”などのリンク
- 2001年に作成した(古い)HTMLサイトマップ
- クライアントのログインやデモ用のサブドメインや、一時的なキャンペーンのために制作した個別のマイクロサイト
ステップ2:会社にとって最も重要なページを決定する。商品ページやカテゴリーページ、ランディングページ、またはユーザーが興味を持ちやすい社員のプロフィールページなどが適していると思われる。
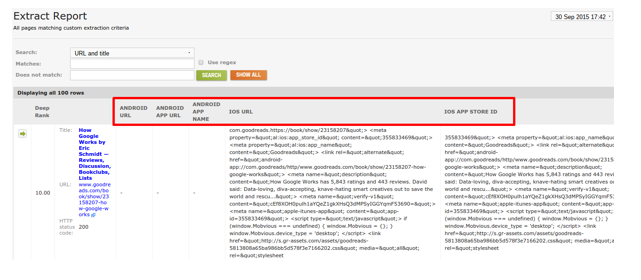
ステップ3:インデックスされたページ数をGoogleサーチコンソールで確認する。
その後、[site:]コマンドを実行し、Googleがインデックスしているページ種別やページテンプレートが何ページあるか確認しましょう。ステップ2で優先度が高かったページから始めると良いでしょう。例:
自社で管理しているページ数とGoogleがインデックスしているページ数に違いはあったでしょうか。これは改善することができます。差異を分析して動的URLが生成されているか、Googleがページネーションを適切に検出しているかを調べましょう
2.クロールバジェットの分析
Googlebotがあなたのサイトに割り当てる1日あたりのページ数がクロールバジェットです。サーチコンソールを使用すると、ページやサイズ、時間に関してクロールバジェットの内訳を知ることができます。
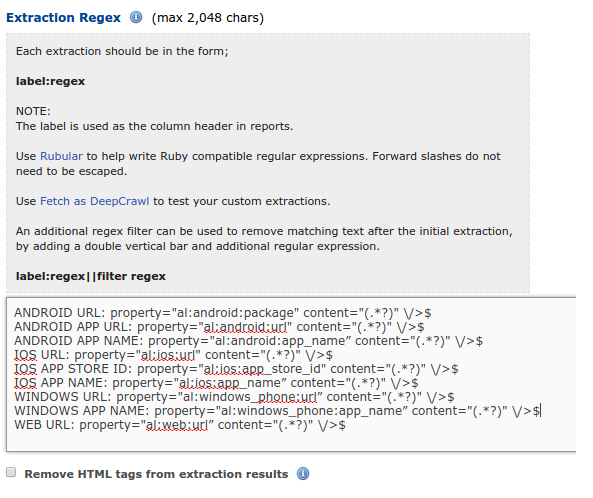
DeepCrawlを使用すると、次のようなより詳細な情報を得ることができます。
- クロールされたURL、クロールされていないURL
- 200以外のステータスコード
- インデックス不可のページ
- 無効なタグ
確認が必要な内容は以下の通りです。
- 収益を生むページがボットにとって到達しやすく、クロールしやすくなっているか。
- 次のクロール先など、これらの収益を生むページにボットが到達した後の行動を正確に把握しているか。
- ボットは何階層までクロール可能か。
- ページのアクセシビリティ、クローラビリティを改善するために実施できることは何か。
Googlebotのサイトクロール方法について詳しく知りたい場合、2016年4月のBrighton SEOでDawn Anderson氏が行なったプレゼンテーションSEO Crawl Rank and Crawl Tank(英語)をご覧ください。
3.サイトマップの監査
サイトマップを使うことでGoogleにクロールさせたいページを指示することができます。
サイトマップの内容の見直しを考えたことはおそらく無いのではないでしょうか。小中規模サイトのYoastプラグインから大規模サイトのスケジュール起動スクリプトに至るまで、ほとんどのサイトには自動生成されたサイトマップがあります。大量のURLをくまなく調べて、それらが返すHTTPコードや優先順位などを確認する時間はないかと思います。
Googleサーチコンソールで、サイトマップの状態の簡単なスナップショットを得ることができます。

サイトの規模にかかわらず、サイトマップのインデックスとなるファイルを作成して、サイトマップをページ種別で分割すると良いでしょう。これにより、各ページの種類毎に重要なページがインデックスされているかどうかの確認が容易になります。
4.クロールエラーの修正
検索順位の上昇を目指しているほとんどのサイトにとって、クロールエラーは悩みの種です。ユーザーに表示されるサイトのエラーはユーザー体験を阻害すると同時に、これらの厄介なエラーは、徐々にドメインのビジビリティを蝕んでいき、結果としてSERPにおけるサイトのビジビリティをも緩やかに侵食していくことになります。
Googleサーチコンソールを使用して、デスクトップ、モバイル端末両方でサーバーの接続性に関するエラーやソフト404エラー、404エラーを除去しましょう。
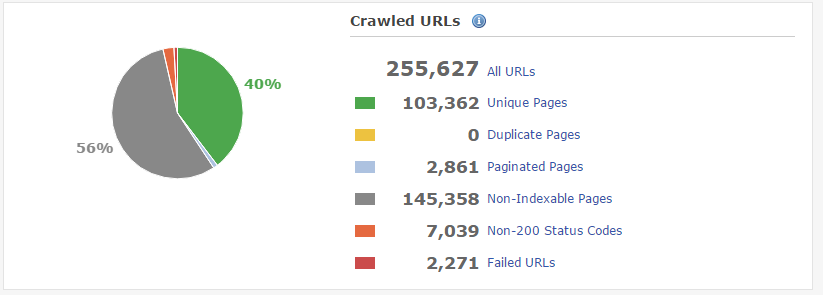
エラーをクリックすると、各エラーの詳細を見ることができます。基本的に役立つ情報ですが、そうでない場合も中にはあります。元のリンクが存在しない場合には、“解決済としてマーク”をクリックしてください。再度そのリンクが表示された場合、DeepCrawlを使用してリンクされたURLを選択してクロールし、問題をすぐに把握するようにしてください。
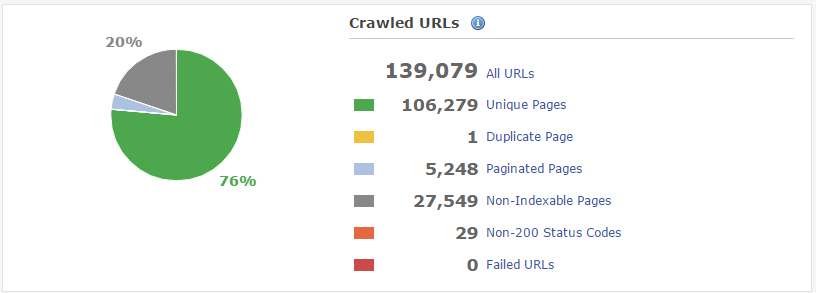
最後に、Googlebotがページを正しくフェッチしてユーザーに表示する内容と同様にレンダリングしているか確認してください。
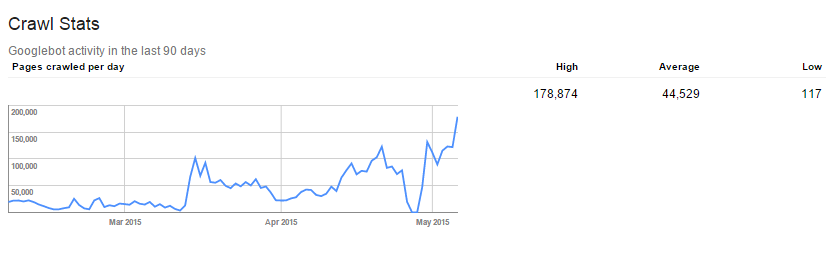
クロールバジェット分析の部分で述べた通り、DeepCrawlもまた、サーチコンソールでは検出できないような様々な種類のクロールエラーの検出に役立ちます。クロールエラーを除去するために両方のツールを併用して、Googlebotにとってスムーズな導線を用意しましょう。
5.JavaScriptの分析
ここ数年間で、GoogleはJavaScriptのクロールとレンダリング能力を飛躍的に改善してきています。Googleはウェブ管理者に対して、robots.txtを使用してJavaScriptのクロールからGooglebotをブロックしないよう具体的に指示してきましたが、現在”少ない知識では問題を及ぼす可能性がある”としています。
その結果、Angular JSやEmber JSのようなJavaScriptやフレームワークをふんだんに使用した多くの新しいサイトが、特に”crawl creepers”と呼ばれる、様々な問題に直面しています。これらは、ポップアップなど特定のURLに自身を追加してGoogleのインデックスを重複コンテンツで埋めてしまいます。そのため、現時点でのGooglebotのためのJavaScript最適化ベストプラクティスは次のようになります。
- JavaScriptもクロールされるようにする
- URLを除外する際はフルパスを使用する。
- crawl creepersが発生しているURLには “rel=nofollow”属性を使用する。
- 実行されているスクリプトとそうでないものをモニタリングする。
結論
この記事で、一般的にテクニカルSEOといえば連想されるH1やAltタグでの最適化に留まらないテクニカルSEOの知識をお伝えできたでしょうか?Googlebotのサイトクロール方法と範囲がオンページSEOの基礎となることを心に留めておいてください。サイト上のすべての改善施策に、この重要な要素が織り込まれているようにしてください。この記事では、以下の方法の説明を行いました。
- サイトをページ種別に分割した中でインデックスされている部分を把握する
- クロールバジェットを分析して向上させる
- サイトマップを監査して不一致を特定する
- 多種多様なクロールエラーを分析して修正する
- ボットのJavaScriptクロール方法をモニタリングしてそれぞれに適したコード修正を行う
Sears社のウェブ&SEOマネージャであるJacqueline Urick氏の言葉を引用してこの記事を締めくくりたいと思います。
”恒久的なクロールは、ビジビリティ(を確保する上で)の代価である。”

