
ページネーションはテクニカルSEOで最も地味なトピックの1つであり、ページネーションを管理および最適化して検索に適したサイトを構築する方法を深く理解するには、さらなる研究が必要となります。
ページネーションの検索最適化において陥りやすい問題を把握するために、DeepCrawlチームでは、Alexaのウェブ上の上位500サイトから150のサイトを抽出して小規模なクロール実験を行い、それぞれのウェブデザインの監査を行いました。
ページネーション のポストrel=next/prevを管理する方法の詳細については、ページネーションに関するSEOベストプラクティスガイドをお読みいただき、BrightonSEOのAdamによる本トピックに関する講演の動画をご覧ください。(英語)
ウェブの上位500サイト
DeepCrawlチームはAlexaの上位500サイトの中から、以下の各カテゴリーから50サイトずつを使用して150のサイトを分析しました。
- ECサイト
- ニュースサイト
- フォーラムサイト
これらのカテゴリを選択した理由は、Googleのページネーションに関する記事(英語)においてこれらのカテゴリがページネーションをサイトデザインに取り入れる最も一般的なカテゴリであると述べられていたためです。DeepCrawlはそれぞれのサイトに対して、カテゴリーまたはフォーラムディスカッションをランダムに設定しました。唯一の判断基準は各サイトのカテゴリーに何らかのページネーションの形式が存在しているという点でした。
Alexa上位500サイトのクロール
調査対象の150サイトとカテゴリを決定した後、DeepCrawlを使用して各サイトをクロールしました。ページネーションのある特定のカテゴリーとページネーションのみを含むURLに絞ってクロールを実施しました。これにより、ページネーションデザインの状況をすばやく把握することができました。
各サイトをクロールする際には、DeepCrawlの詳細設定の以下の機能を使用しました。
- ユーザーエージェント: Googlebot Smartphone
- IP: アメリカ
- JavaScriptレンダリング: 無効
サイトをクロールすると、Alexaの上位500サイトは別々のモバイルURLを使用していたことがすぐに判りました。これに対応するためにDeepCrawlの詳細設定を変更してモバイルサイト設定を使用することで、モバイル版のURLの検出とモバイルサイトが適切に設定されているかどうかの確認に役立ちました(モバイルとページネーションに関して得た知見については、別の記事でご紹介します)。
サイトのクロール完了後、DeepCrawlでデータ分析を行い、各サイトのページネーションの状態を検索に適しているとされる条件と比較しました。
検索に適したページネーションの基準
DeepCrawlは、Google公式の無限スクロールを検索に適したものにするための推奨事項(英語)とインデックス登録について の記事で述べられている技術的条件をもとに、検索に適したページネーションの基準を作成しました。
検索に適しているとされるページネーションの条件は以下の通りです。
- ページ分割されたコンポーネントに固有のURLがある (例: /category-page?page=2)
- ページ分割されたコンポーネントがページ分割されたページのクロール可能なリンクから到達可能
- 一連のページのうちページ分割されたページはインデックス可能である
- インデックス可能ページなページ分割されたページにDeepCrawlの基準で重複コンテンツが存在しない
この基準を定める際にDeepCrawlチームはこれらが基本的すぎるのではないかと懸念し、より詳細な基準にしようと試みましたが、テストを行うと数多くのサイトが実際の基本的な基準でさえ満たしていないことが分かりました。
また、検索に適しているとされる本来の基準にrel=“next”とrel=“prev”が含まれていましたが、Googleは今後それらをインデックスの対象として見なさないことを発表しました。この点は、GoogleウェブマスタートレンドアナリストであるJohn Mueller氏により後日Twitterで再度明確化されています。
We don’t use link-rel-next/prev at all.
— John (@JohnMu) March 21, 2019
SEOにおいてどのような意味があるのか、詳細はDeepCrawlのページネーションに関するテクニカルSEOガイドの記事をご覧ください。
DeepCrawlで作成した基準に関して言うと、特にデータに影響はありませんでした。検索に適するページネーションの基準から、単純にrel=next/prevの点を削除し、その他の変更はありませんでした。
ページネーションの検証結果
データ分析を行うと、特定のページネーションデザインの結果と現状に驚くべき点がありました。以下では、調査結果をまとめて、テクニカルSEOの担当者やサイト管理者が結果を基に行動に移せる洞察を得られるよう、課題を細分化しています。
結果の概要
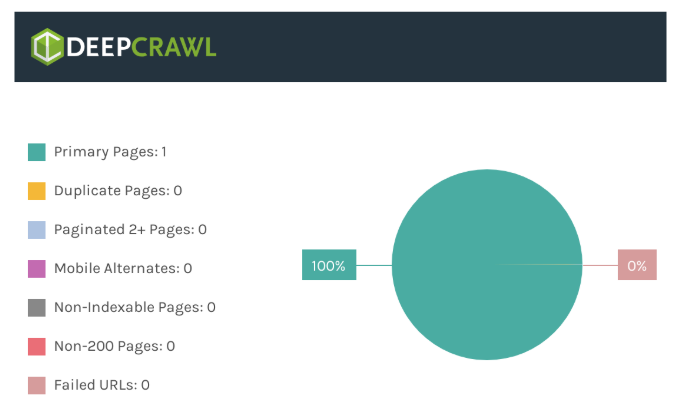
DeepCrawlで定めた基準によると、検証対象となったサイトの実に65%のページネーションが検索に適していないということが分かりました。
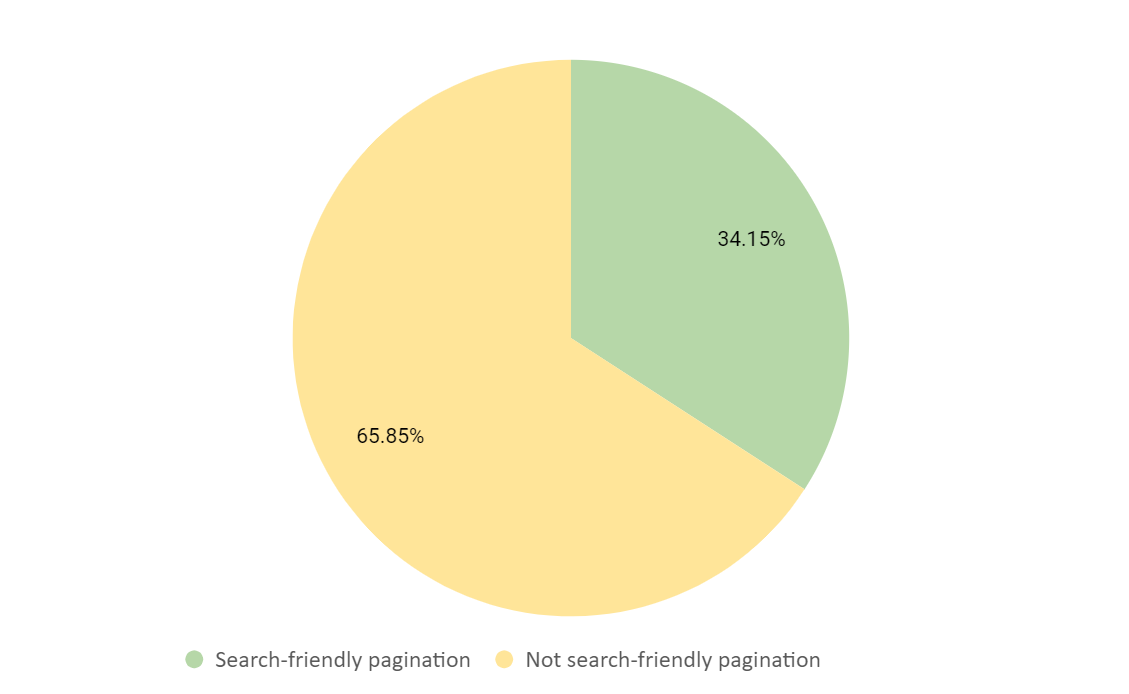
技術的な基準は初歩的なSEO施策をベースにしたものだったので、検索への最適化基準に満たないサイトがこれほどあることに驚きました。
各サイトのページネーションが検索に最適化されているかどうかを確認すると同時に、それぞれのウェブデザインの種類も記録しました。DeepCrawlの分析によると、主要なデザインが3種類あることが分かりました。
- ページネーション
- 無限スクロール
- さらに読み込む+遅延読み込み
これらはすべてコンテンツを複数のページにわたって分割しているため、ページネーションに分類されると思われます。デザインの種類を記録していると、3つのサイトカテゴリーのうち、ある特定のデザインが突出して多く利用されていることに気づきました。
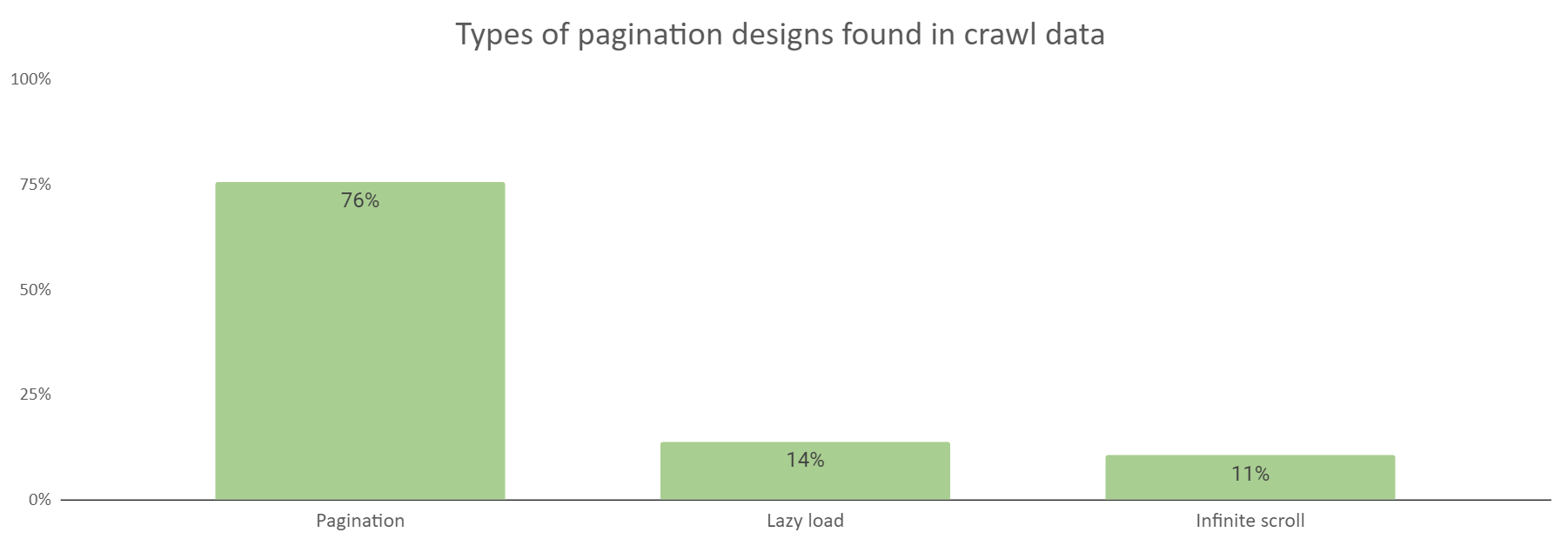
上記のグラフから分かるように、分析の結果、記事または商品の一覧を複数ページに分割する際に最もよく使用される手法はページネーションと言えます。さらに読み込む+遅延読み込みの併用と無限スクロール(単一ページのウェブデザインの1つ)もまた、複数ページにまたがったコンテンツ表示の目的で使用されていました。
ウェブデザインの種類別に検索最適化の程度を調べると、ページネーションが3種類の中で最も検索に適している事が分かりました。
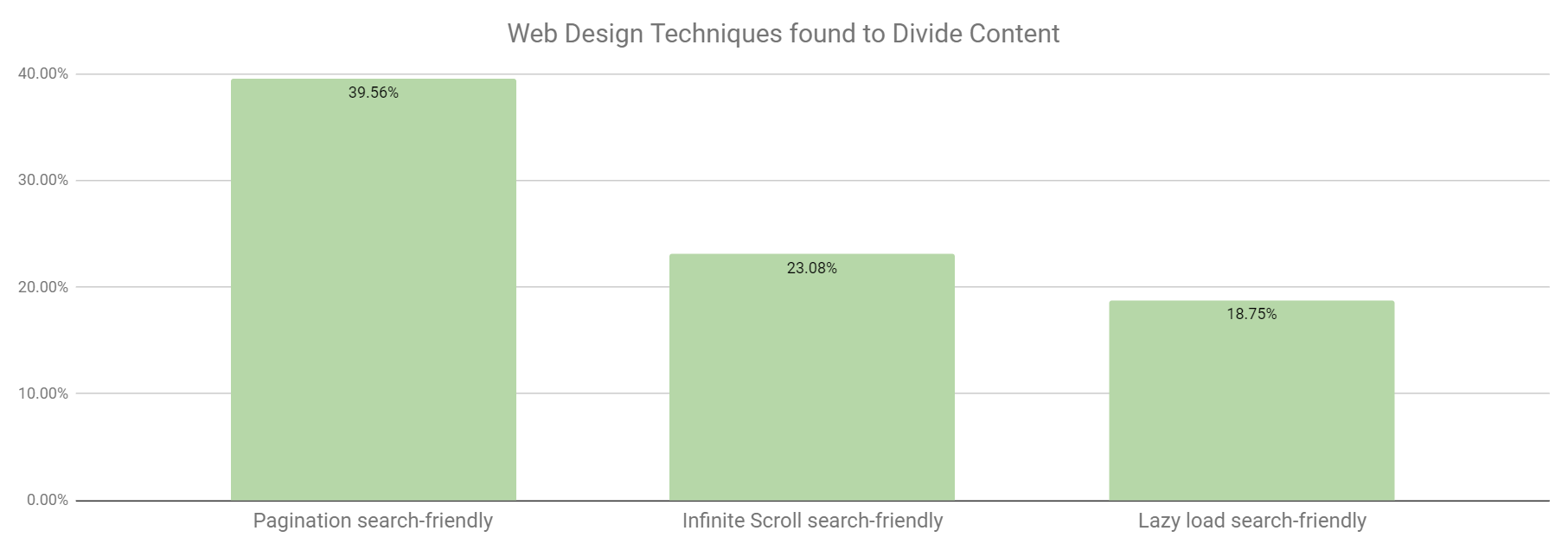
しかし、以下のグラフを見ると、単一ページウェブデザインである2種類は最も検索に適していないことが分かります。
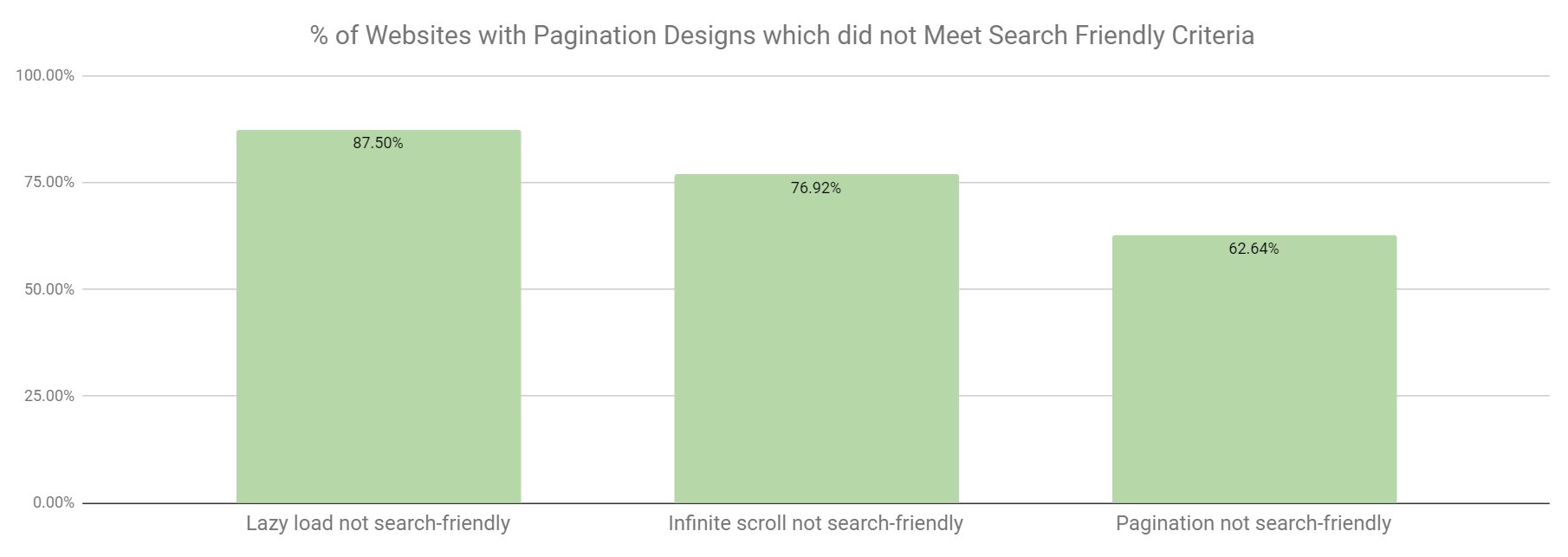
これらの結果によると、さまざまな種類のウェブデザインについてクロールデータを深堀りして、特定のデザインが検索に適さない理由を把握することが重要ということがわかります。これは、ページネーションや無限スクロールにおける一般的なSEO上の失敗*1の理解に役立つだけでなく、ウェブデザイン設計者が陥りやすいSEO上の落とし穴を回避する方法の理解にも役立てることができます。
**1.すべてがSEO上の問題ではありませんが、DeepCrawlチームがデータから見つけた最も一般的な問題です。
ページネーション
ページネーションは、記事または商品の一覧を複数のページ要素に分割する際に使用されます。これは、記事や商品の一覧を閲覧しやすいフォーマットに分割する目的で広く一般的に使われている手法です。
以下では、それぞれの検索最適化基準を說明した上で、多くのサイトがその基準を満たせない原因である一般的なSEO上の失敗に焦点をあてます。
固有のURLをもつページ分割されたコンポーネント
Googleによると、コンテンツのクロールとインデックスのためには、ページにURLが割り当てられていることが必要です。ページ分割されたコンポーネントに紐づけられたコンテンツやリンクは、URLがなければクローラーによって発見されず、クロールもインデックスもされません。
ページ分割に関してサイトを分析すると、固有ののURLがないページ分割されたコンポーネントは5%だけであることが分かりました。
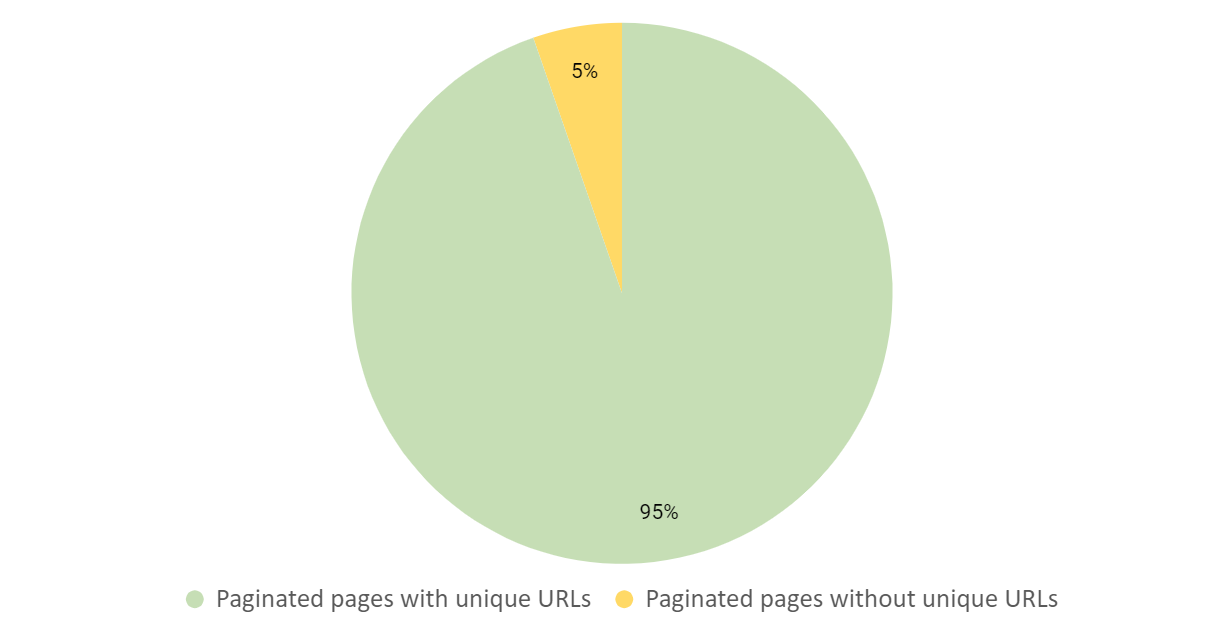
基準を満たさなかった少数のサイトでは、ページ分割されたページコンテンツにフラグメント識別子(#)が割り当てられているという問題が見られました。
Googleは、フラグメント識別子(#)の後のコンテンツはクロールもインデックスもされないと発表しました。したがって、ページ分割したコンポーネントにURLを割り当てる際には、ページ分割したコンテンツを読み込むために、フラグメント識別子を使用するのではなく絶対URLを使用するようにしてください。
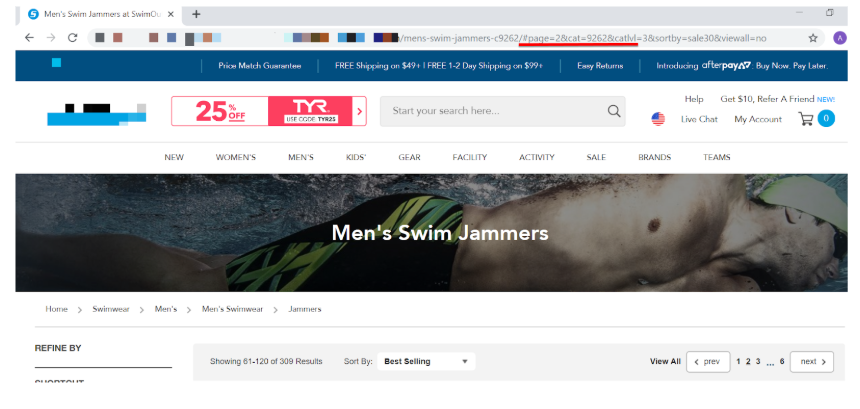
- 絶対URLの例 : https://www.example.com/product-category/page=2
- フラグメント識別子(#)の例 : https://www.example.com/product-category#page=2
対策:
- ページ分割されたコンポーネントに固有のURL(静的もしくは動的)が割り当てられていることを確認する
- ページ分割されたURLにフラグメント識別子(#)が含まれていないかブラウザから確認する
動的URLと静的URL
150のサイトを分析すると、多くのサイトがページネーションに異なるタイプのURLを使用していることが分かりました。
- 静的URLの例 : https://www.example.com/product-category/page2//
- 動的 (パラメータ) URLの例 : https://www.example.com/product-category?page=2
調査の結果、掲載順位やクロールの目的で動的URLと静的URLとの一方のみを利用するメリットはないことが分かりましたが、Googlebotはデスクトップリサーチ(今後テストされる予定)に基づいた動的URLをベースにURLパターンを推測してクロールするようです。そのため、テクニカルSEOの担当者がこのGooglebotの推測を通してページネーションパターンを発見させたい場合は、動的URL(パラメータ)を使用することをお勧めします。
しかし、動的URLの使用はクロールの落とし穴にもなり得ることも分かりました。サンプルサイトでページ分割されたURLのパターンを推測している際に、現在のページ分割されたページの一部ではない重複した動的ページが存在することが分かったのです。

上記ページネーションでページ分割されたコンポーネントに割り当てられた固有のURLの例を以下に示します。
/clothing/dresses/ – URLの1ページ目
/clothing/dresses/?page=2 – 2ページ目
/clothing/dresses/?page=3 – 3ページ目
/clothing/dresses/?page=4 – 4ページ目
URLパターンに基づいてパラメーターを手入力すると、CMSは空のページを読み込み続けます。
/clothing/dresses/ ?page=5 – 5ページ目
/clothing/dresses/ ?page=6 – 6ページ目
/clothing/dresses/?page=7 – 7ページ目
GooglebotがこのURLパターンをクロールすると判断した場合、ボットはページ分割されたページを無限にクロールすることになり、クロールバジェットが浪費されてしまいます。
動的URLを使用している場合、現行の一部ではない動的URLのページ分割ページに対して、200 HTTPステータスコードを生成されるようなサイト構造・設定になっていないことを確認してください。このようなページが本番環境に残されてしまうと、Googleは重複しているか空のページ分割ページをクロールしてインデックスすることになってしまいます。
対策:
- サイトのページ分割URLのパターンに関する情報をGoogleに伝えたい場合、動的URLを使用して、GoogleがパラメーターURLのパターンを取得できるようにしましょう。
- 動的URLを使用する場合は、意図しないページ分割URLがクロールバジェットを浪費しないように、サイトがステータスコード4xxに設定されていることを確認してください。
クロール可能なリンクとは
Googleにページ分割されたページを効率的にクロールさせるには、Googleがhref属性を持ったアンカーリンクを検出する必要があります。特に、Googleによる検索エンジンのインデックスの判断要素としてrel=”next”とrel=”prev”をサポートしないという発表があったことを考えると、これらのページがクロールされてインデックスされるということが非常に重要です。
クロール可能な内部リンクが非常に重要になっていることを勘案すると、DeepCrawlチームによるAlexa上位サイトの分析結果として、ページネーションのあるサイトの56%がアンカーリンクを適切に使用していないことが判明したのは驚きでした。
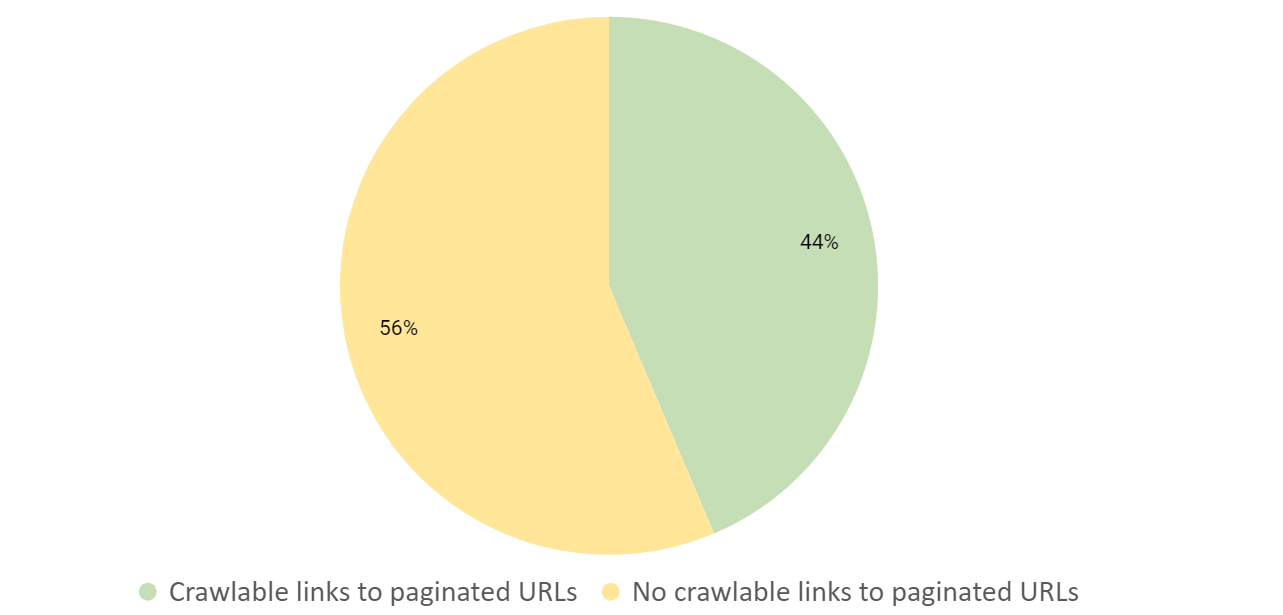
特にGoogleや他の検索エンジンがクロールやインデックス品質のチェックにおいて内部リンクを重視していることを考えると、この結果は懸念すべき結果といえます。多くのサイトがこの基準を満たせなかった理由と、その他一般的に見られた課題については、ページネーションのクロールデータで掘り下げています。
アンカーリンクがないページ
最も多く見られた課題のうちの一つは、サイトデザイン上のページネーションページへのリンクがソースコードやドキュメントオブジェクトモデル(DOM)上で<a href=””>を使っていないという点でした。
サイト上のページネーションページへのリンクを調べていると、アンカーリンクが使われていないことが分かりました。その代わりに、サイトがページ分割されたコンポーネント上のコンテンツをJavaScriptで読み込むようにサイトが構築されていました。
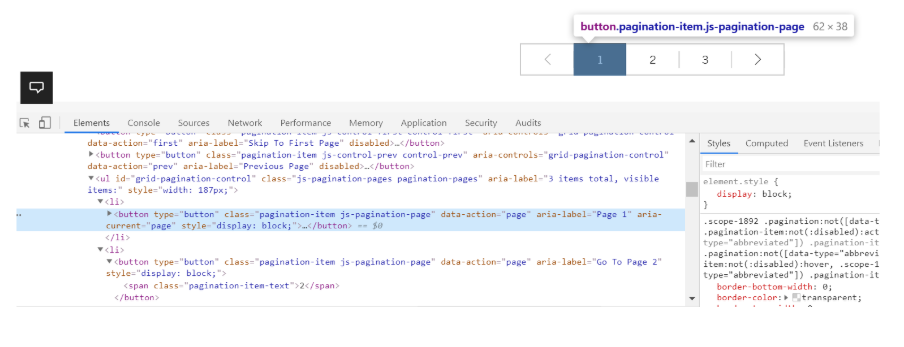
DeepCrawlでJavaScriptを使ったページネーションの1ページ目をクロールしたところ、サイトからリンクされたページは検出されませんでした。
これは、JavaScriptのレンダリングが有効化されている場合であっても、DeepCrawlとGoogleの両方がページを検出してクロールできるように、href属性のあるアンカーリンクが必要になるためです。
対策:
- ページ分割されたページにリンクする際は、ソースコード内のリンク要素にhref属性のアンカーリンクを使うようにしてください。
- DeepCrawlのような、href属性のアンカーリンクをクロールするよう構築されたサードパーティのクローラーを使用して、ページ分割されたページにhref属性のアンカーリンクが含まれているか検証してください。
- GoogleがJavaScriptなしの状態でリンクを検出できるか素早く確認するには、ページ上で右クリックしてページのソースコードを開き(Ctrl + U)、元のHTML上でページ分割されたURLが検索できるか試してください(Ctrl + F)。
URLではなくスクリプトを使用するhref属性
アンカーリンクがない問題と同様に、多くのサイトでhref属性の中に絶対URLや相対URLではなくイベントスクリプト (javascript:)が使用されていることが分かりました。
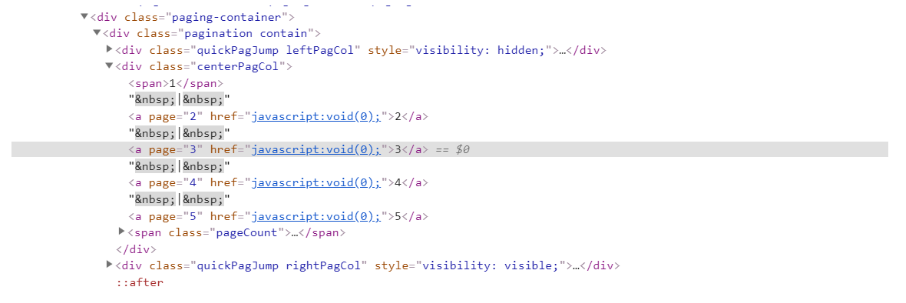

これは通常、開発チームがページ上にリンクを設置する時や、アンカーリンクのように見せたいがURLを載せたくないという場合に発生します。その代わりに、彼らはリンクがクリックされた時にトリガーされるイベントスクリプトを使用して、ユーザーにページ分割コンテンツが読み込まれるようにしています。
Tこれがクロール可能なリンクの問題である理由は、検索エンジンがページをクロールするにあたりhref属性内に絶対URLか相対URLが必要なためです。
繰り返しになりますが、アンカーリンク欠落の問題と同様に、この問題を抱える多くのサイトがJavaScriptを使用してユーザーにコンテンツを読み込みしているようです。
対策:
- 開発チームがどのようにページ分割されたページへリンクしているか特定するため、Google Chromeの[Inspect Element]タブを使用してページ分割されたリンクを再確認する。
- 検索エンジンがページ分割されたページへのリンクを検出できるよう、href属性に相対URLか絶対URLを指定したアンカーリンクを使用する。
ページ分割されたURLがrobots.txtでブロックされている
最後に、調査で分かった一般的なクローラビリティのもう一つの問題として、robots.txtファイル内でページ分割されたURLがブロックされていたという問題があります。
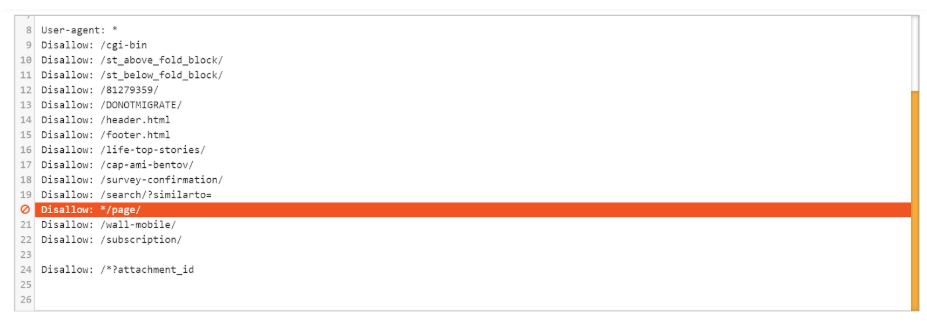
あるURLがrobots.txt内でブロックされている場合、検索エンジンはそのページをクロールすることも、そのページからコンテンツや外部リンクを検出することもできません。多くのサイトが重要でないページ分割ページのブロックを検討しているかもしれませんが、もしページ分割ページがトラフィックや収益を生み出すようなページへつながる唯一のアクセス地点だった場合、そのページはサイト構造において重要なページであると言えるでしょう。
サイトの保有者は、サイトの動的もしくは静的URLをブロックする際に誤って重要なページネーションURLをブロックしないようにしましょう。
対策:
- ページ分割URLがGooglebotによってクロールされるかどうかテストするため、Googleサーチコンソールのrobots.txtテスターを使用しましょう。
- robots.txtを使用して新しいパラメータを許可する際に、ページ分割URLが誤ってブロックされていないかどうか常に確認するようにしましょう。
インデックス可能なページ分割ページ
ページ分割ページは、検索エンジンにとっては深い階層のページを検出してクロールするための重要なアクセスポイントとなります。ページ分割ページをインデックスする理由は、Googleのインデックス作成システムの仕様と、ページがインデックスから除外された際の(潜在的な)動きに対処するためです。
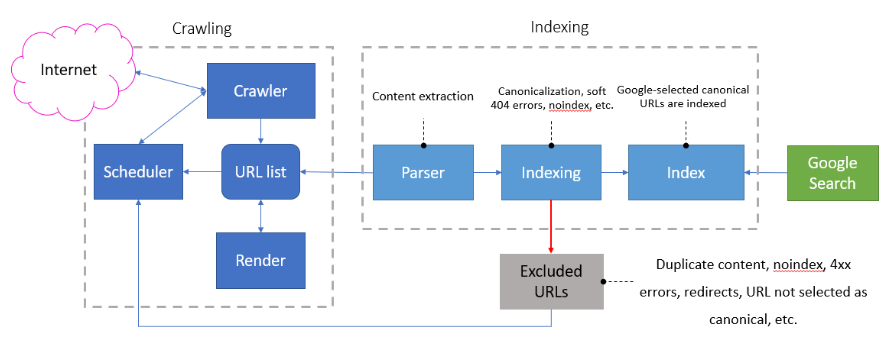
上記の図は、Google I/O 2018のスライドとミュンヘンで行なわれたSMXミュンヘンでのJohnとの会話内容を踏まえてDeepCrawlが作成したものです。
Googleがクロールしたウェブ上の全てのURLは、ページのインデックス前に同様の選定プロセスを経ることになります(上記図を参照)。この選定プロセスは正規化と呼ばれているインデックス処理の一部で、サイト管理者が正規化ページを指定していなくても必ず発生します。この選定プロセスを通ったページは、Googleに選ばれた正規化URLと呼ばれています。これらの正規化ページは以下の目的で使用されます。
- ページのコンテンツを評価する主要なソース
- ページの質を評価する主要なソース
- 検索結果に掲載されるページ
インデックスから除外されたページに関して、GoogleのウェブマスタートレンドアナリストのJohn Mueller氏は、Googleはそれを使用しないし、ページ上のリンクを辿ることもしないということをかねてより指摘していました。
「noindexがGoogleの基準よりも長く存在する場合、検索結果にそのページを表示したくないものとみなし、検索結果から完全に削除することにしました。リンクも辿りません。そのため、noindexとfollowは、本質的にはnoindexとnofollowと同じ意味になります。」ーGoogleウェブマスタートレンドアナリスト John Mueller氏、Googleウェブマスターハングアウト(2017年12月15日)
John氏は、Googleのインデックスで除外されたページからいずれすべてのシグナルを外すという発表の後、Twitterにおけるディスカッションでも以下のような言及をしています。
「私の知る限りでは、しばらくの間何も変わっておらず、もしGoogleがインデックスからあるページを削除することになった場合、インデックスからすべてを削除します。Noindexページは時に404エラーのようなソフト404エラーなのです。」ーGoogleウェブマスタートレンドアナリスト John Muller氏、Twitter(2017年12月28日)
これらのコメントは、ページ分割ページが手段に関わらずGoogleのインデックスから長期間除外された場合、結果的に、除外されたページ分割ページにあるすべての外向きシグナル(内部リンクやページ上のコンテンツ)をGoogleが削除することになることを示唆しています。
すでに述べたように、サイト上のページネーションで最も重要な役割は検索エンジンのクローラーがより深い階層のページ(商品、記事など)を検出できるようなアクセスポイントを作成することです。
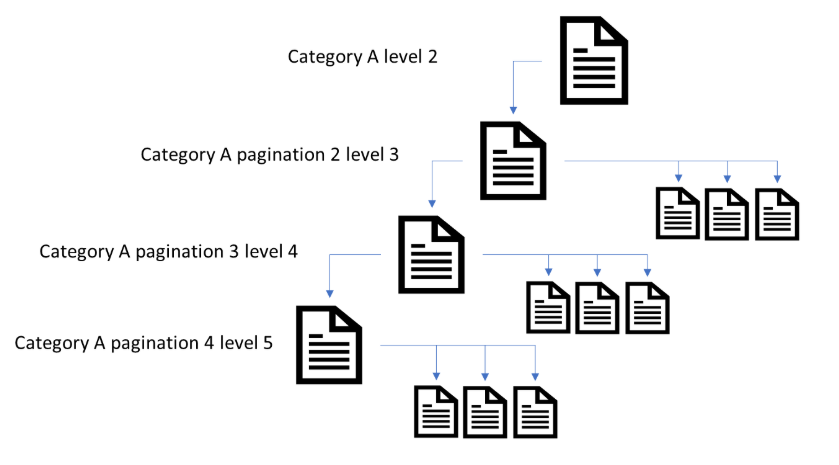
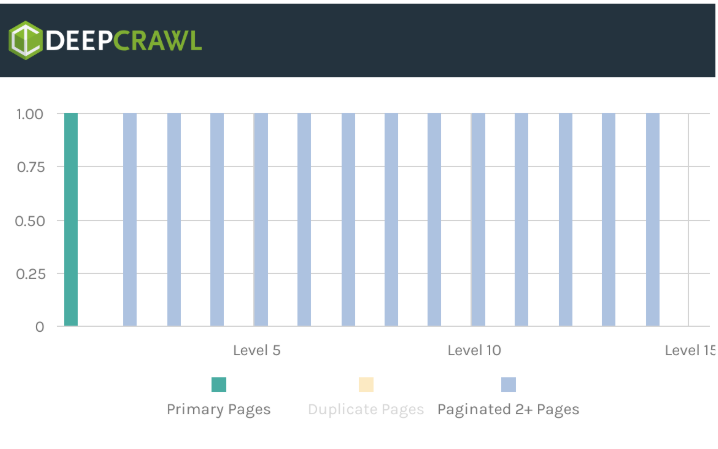
Alexaのサイトにおいてクロールからページ分割URLを除外するテストでは、あるサイトの30〜50%ものページが内部リンクを通してクローラーに検出されるページネーションに依存していることが分かりました。こうしたサイトの一例を以下で説明します。
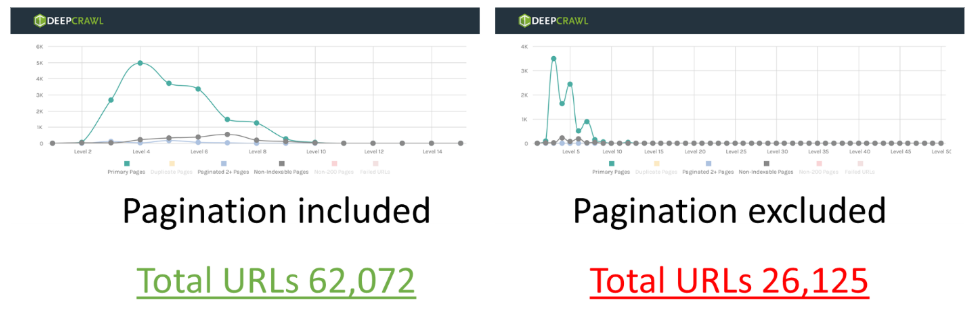
サイト管理者がページ分割URLをGoogleのインデックスから除外している(rel=canonicalかnoindexを使用している)場合、ページネーション からの内部リンクに依存している深い階層のページへの外部要因(内部リンク)をGoogleが削除することになる可能性があります。
加えて、Googleが正規化されインデックスされたページをベースにコンテンツを評価する場合、リンクグラフのような重要なシグナルもGoogleにより選択された正規化URLに基づく可能性があります。もしこの仮説が正しいのであれば、除外されたページ分割ページからリンクされた深い階層のページは孤立したページになり、検索結果に表示されなくなってしまいます。/p>
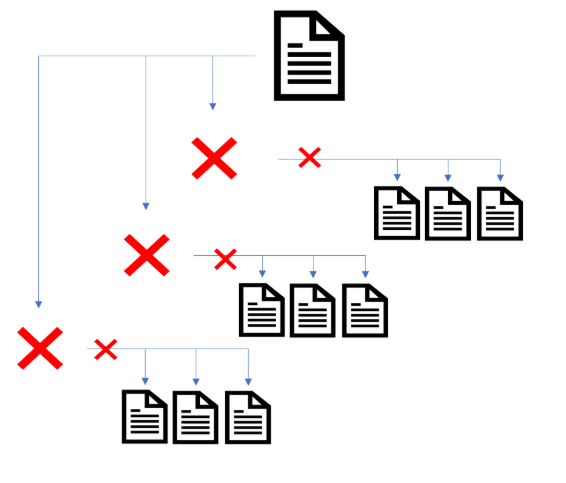
ページ分割ページ上の内部リンクをたどることができるか確認するには、Googleがインデックスしているか確認することが重要です。
ページネーションのあるサイトをのうち20%のページ分割ページがインデックス不可になっていることがテストで分かったからです。
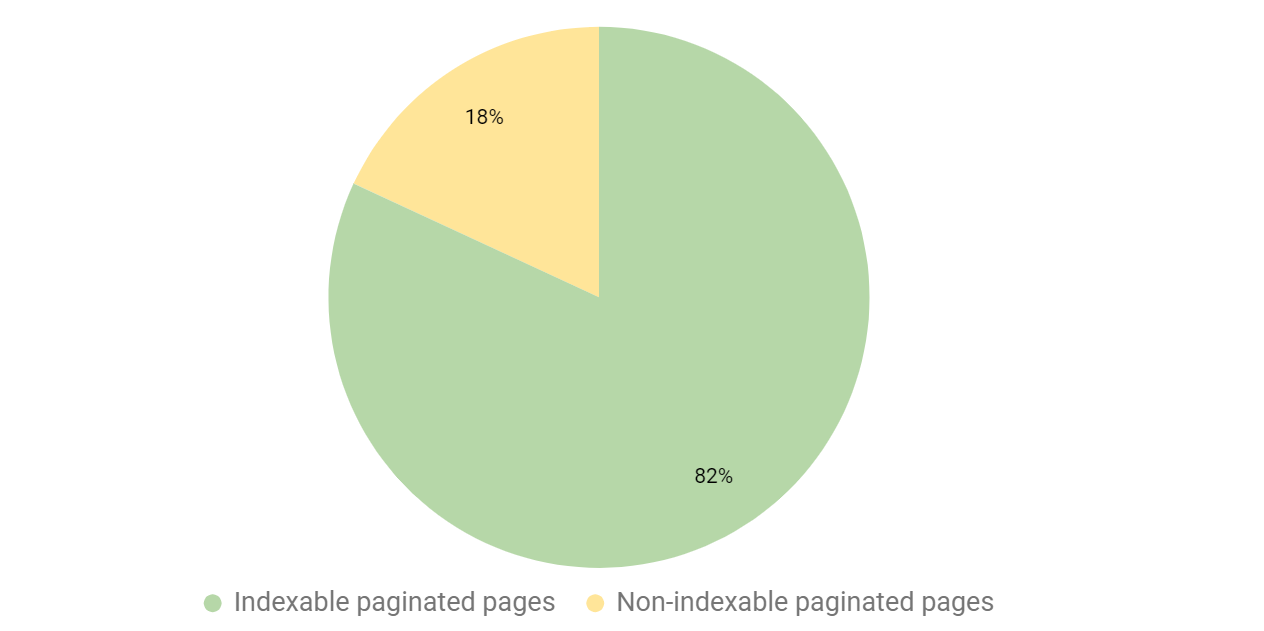
また、サイト管理者がページ分割ページをインデックス不可にしてしまう原因を把握するため、データを詳細に調査しました。
正規化されたページ
ページ分割ページがインデックス不可になってしまう一般的な要因は、ページ番号がつけられたページ分割ページに最初のページを指定したrel=canonicalタグを実装してしまうことです。
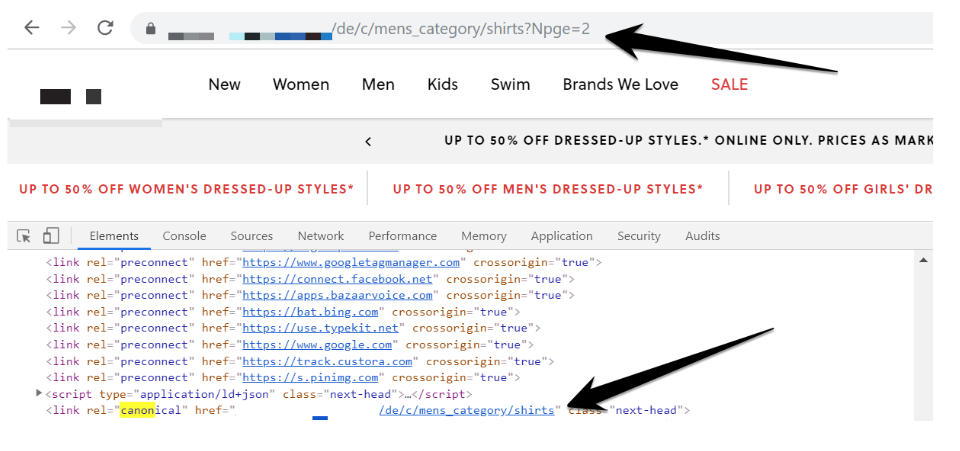
既に述べた通り、こうすることでGoogleはページ分割ページの2ページ目以降をインデックスから除外し、深い階層までページの内部リンクを辿ることもカウントすることもしません。
対策:
- サードパーティのクローラーを使用してサイト上でNoindexもしくは正規化されたページ分割ページを検出する
- URL検査ツールを使用して、Googleのインデックス上でのページ分割ページURLの状況を調べる
- インデックスカバレッジレポートを使用して、ページ分割ページのインデクサビリティをモニタリングする。
重複したコンテンツ
最後のトピックは、サイト管理者がインデックスさせたいページ分割ページには固有のコンテンツを含めるべきであることです。ページネーションを使用する目的は、ユーザーが利用しやすいように記事や商品を一覧にするためです。ページ分割ページの内容が一意であるためには、一覧にされたアイテムがその他のリストのアイテムと重複しないようにする必要があります。
ページネーションに関するテストを行うと、3%のページ分割ページが重複していることがわかりました(重複コンテンツの検出にはDeepCrawlを使用)。
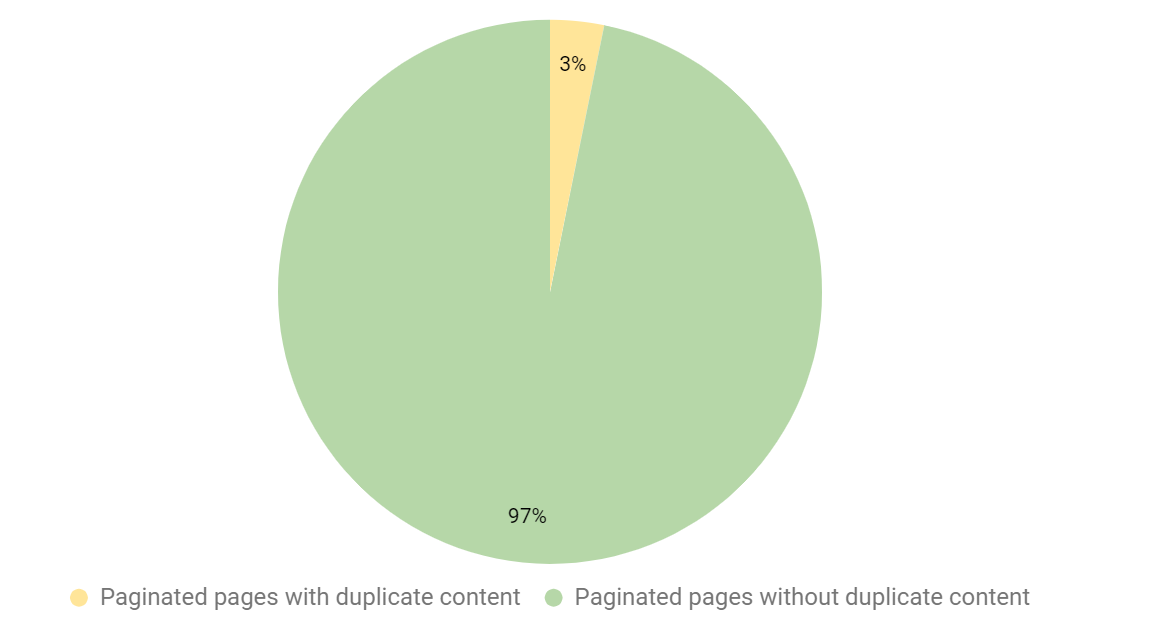
データを深掘りすると、コンテンツ重複の基準は多くのサイトが満たしていることがわかりました。これはページ分割ページがコンテンツ重複のためにGoogleのインデックスから予期せず外されてしまうことがないことを示す素晴らしい結果です。
重複コンテンツがあったページ分割ページについて、CMSが、主要なページ分割URLを複製してしまっていたことが分かりました。
サイト管理者がサイトのパラメーターを管理していなかったこと、rel=canonicalタグで正規化URLが指定されていなかったことが問題だと思われます。これは現在のページネーションのファセットとフィルターを管理するSEOベストプラクティスの適用が必要な例です。対応をしないとGooglebotのクロールバジェットが重複コンテンツに消費され、優先したいURLよりも重複コンテンツを選択してインデックスしてしまう可能性もあります。
対応:
- DeepCrawlのようなサードパーティツールを使用してサイト上の重複コンテンツを検出する
- 重複もしくはファセットナビゲーションを使用してGoogleが正規化URLとして使用するページ分割ページを指定する
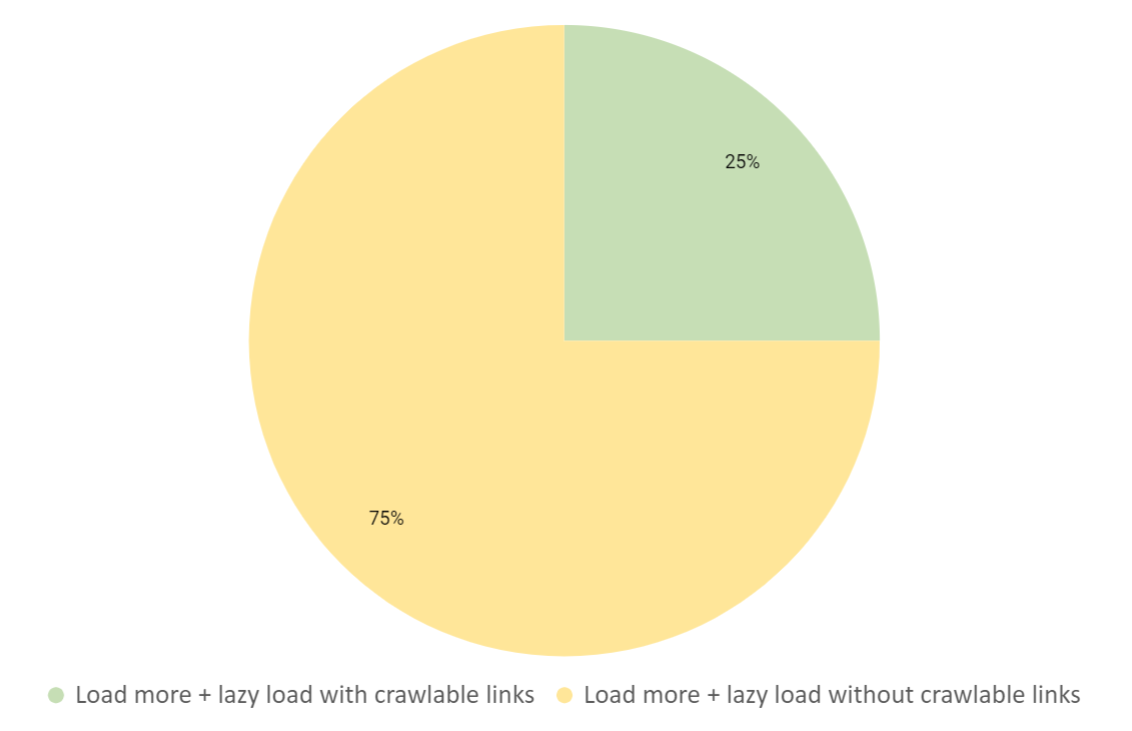
さらに読み込む+遅延読み込み
遅延読み込みと「さらに読み込む」は複数のコンポーネント関して記事や商品の一覧を分割するウェブデザイン手法ですが、ユーザーがクリックイベントを使用して読み込むまでページ分割されたコンポーネントの読み込みが先送りになります。
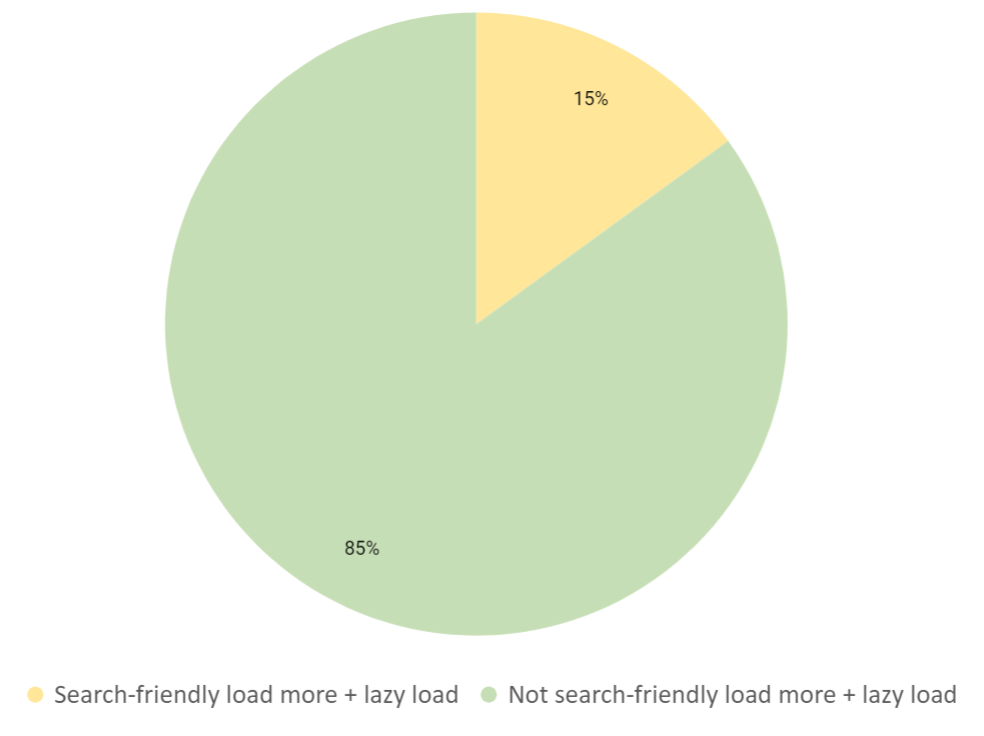
コンテンツを複数ページに分割するこのウェブデザイン手法は、DeepCrawlのクロールデータ上では2番目に多く見られました。それぞれのサイトを基準と照らし合わせるると、遅延読み込みと「さらに読み込む」を採用しているサイトの85%が基本の評価基準を満たしていないことが分かりました。
クロールデータ分析の結果として、この数字は驚くべきものでした。各基準と照らし合わせてみると、「さらに読み込む」デザインを採用しているサイトの多くにページ分割されたページを検出可能にするための基本的な要素が足りていないことが明らかになりました。
固有のURLのあるページ分割されたコンポーネント
遅延読み込みのデザインの根本的な問題は、クリックイベント経由で読み込みされたコンポーネントに固有のURLが割り当てられていないことです。すでに述べたように、Googleのような検索エンジンがページをインデックスするためには、ページにURLが必要です。
残念ながら、さらに読み込む+遅延読み込みのウェブデザインを検索に適したものにする方法関するGoogle公式の文書はありません。しかし、どちらも複数のコンポーネントの読み込みにイベントスクリプトが必要という点で、無限スクロールに関する文書(英語)の推奨事項を活用することができます。
この文書によると、スクリプトの使用により読み込まれる各コンポーネントには、検索エンジンがコンポーネント上のコンテンツをクロールしてインデックスできるように一意のURLが割り当てられている必要があります。
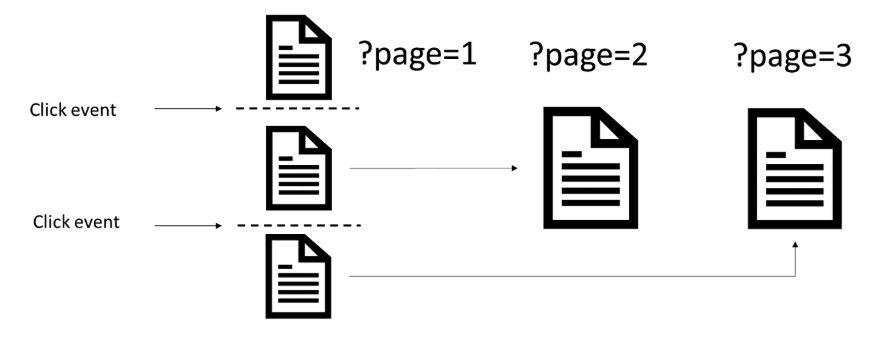
このベストプラクティスを実施しているサイトは多くありませんでしたが、適切に実装していたサイトはほんのわずかしかありませんでした。
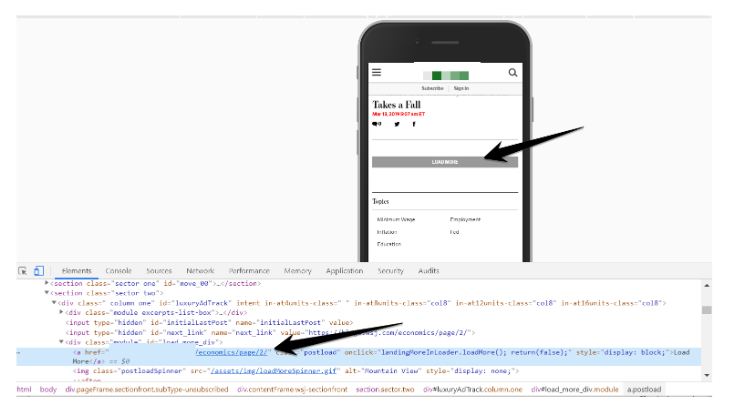
一部のサイトはページ分割したページにURLを割り当てていましたが、新たに一連のコンポーネントの読み込みを行なっていたので、ブラウザでURLを変更するためにHistoryAPIのpushStateメソッドを使用していませんでした。これは、クロールやインデックスに重要なものではないものの、無限スクロールにおいて使用が推奨されています。
さらに読み込む+遅延読み込みのデザインを採用しているサイトに関しては、ページ分割したコンポーネントに一意のURLが割り当てられていることをCMSやウェブアプリ上で確認してください。
対策:
- さらに読み込む+遅延読み込みのデザインでページネーションを実装する際は、一連のコンポーネントに静的もしくは動的な一意のURLが割り当てられていることを確認する
- クリックイベントでユーザーが新しいコンポーネントを読み込む際、ブラウザ上のURLを更新するためにHistory APIのpushState メソッドを使用する
クロール可能なリンクとは
すでに述べた通り、Googleがページへのリンクを発見してクロールするには、ページ分割したコンポーネント上にクロール可能なリンクが存在する必要があります。内部リンクの設置も検索エンジンがサイトの深い階層のページを検出するために重要な施策です。
そのため、これらのデザインタイプを採用しているサイトの多くに一連のページ分割ページへのクロール可能なリンクが無いというのは残念な結果でした。
一方で、このデザインでクロール可能なリンクを実装していたサイトから学ぶことができます。そのサイトでは、「さらに読み込む」の
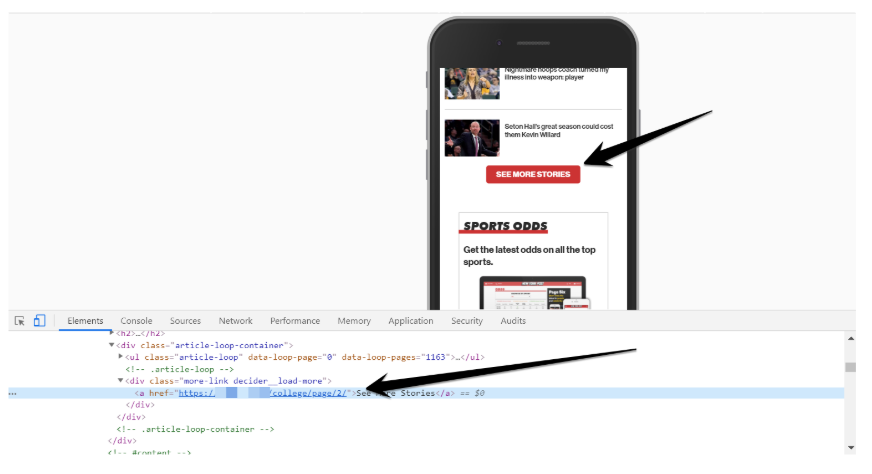
これは、さらに読み込む+遅延読み込みのデザインをクロールする際に、こうした実装を行なっておけば、一連のページ分割されたページとページ分割コンポーネント上の内部リンクをすべて検出することができるということです。
対策:
- 検索エンジンがページ分割されたページを発見してクロールできるよう、「さらに読み込む」要素の読み込みにhref属性のあるアンカーリンクを追加する
- 検索エンジンのクローラーがページ分割されたページを発見できるよう、アンカーリンクがhref属性で相対URLか絶対URLを指定していることを確認する
ページ分割されたインデックス可能ページ
このタイプのデザインの多くはページ分割されたページに一意のURLを持ってさえいなかったため、インデックス不可ページに関する問題点を検出することは困難です。
ページネーションと同様に、「さらに読み込む」ウェブデザイン上の一意のページ分割されたコンポーネントはインデックスされるようにする必要があります。ページ分割されたページがインデックスから除外されると、Googleがコンポーネントページのコンテンツを使用せず、内部リンクも辿らないことになるからです。
さらに読み込む+遅延読み込みのページ分割ページを検索エンジンがクロールし、インデックスできるようにしてください。
対策:
- サードパーティのクローラーを使用してサイト上でNoindexもしくは正規化されたページ分割ページを検出する
- URL検査ツールを使用して、Googleのインデックス上でのページ分割ページのURLに関するインデックス状況を調べる
- インデックスカバレッジレポートを使用して、ページ分割されたページのインデクサビリティをモニタリングする。
重複したページ分割ページ
インデクサビリティの問題と同様に、ページ分割URLを使用しないウェブデザインゆえにクロールデータが存在しないため、コンテンツ重複での間違いを見つけることは困難です。
したがって、ページ分割されたページのように、さらに読み込むの一連のコンポーネントは一意である必要があります。類似もしくは重複したコンテンツがあると、Googleがそれぞれの正規化URLをインデックスするのではなく正規URLを1つだけインデックスしてしまいます。
対策:
- DeepCrawlのようなサードパーティツールを使用してサイト上の重複コンテンツを検出する
- 重複もしくはファセットナビゲーションのSEOベストプラクティスを使用してGoogleが正規URLとして使用するページ分割ページを指定する
無限スクロール
無限スクロールとは、コンテンツを複数のコンポーネントに分割する単一ページのウェブデザインであり、ユーザーはページ分割されたリンクをクリックして別のページに移動することなくコンテンツ全体を継続的にスクロールすることができます。
無限スクロールのウェブデザインを実装しているサイトの多くが検索最適化に関する基本的な基準を満たしませんでした。
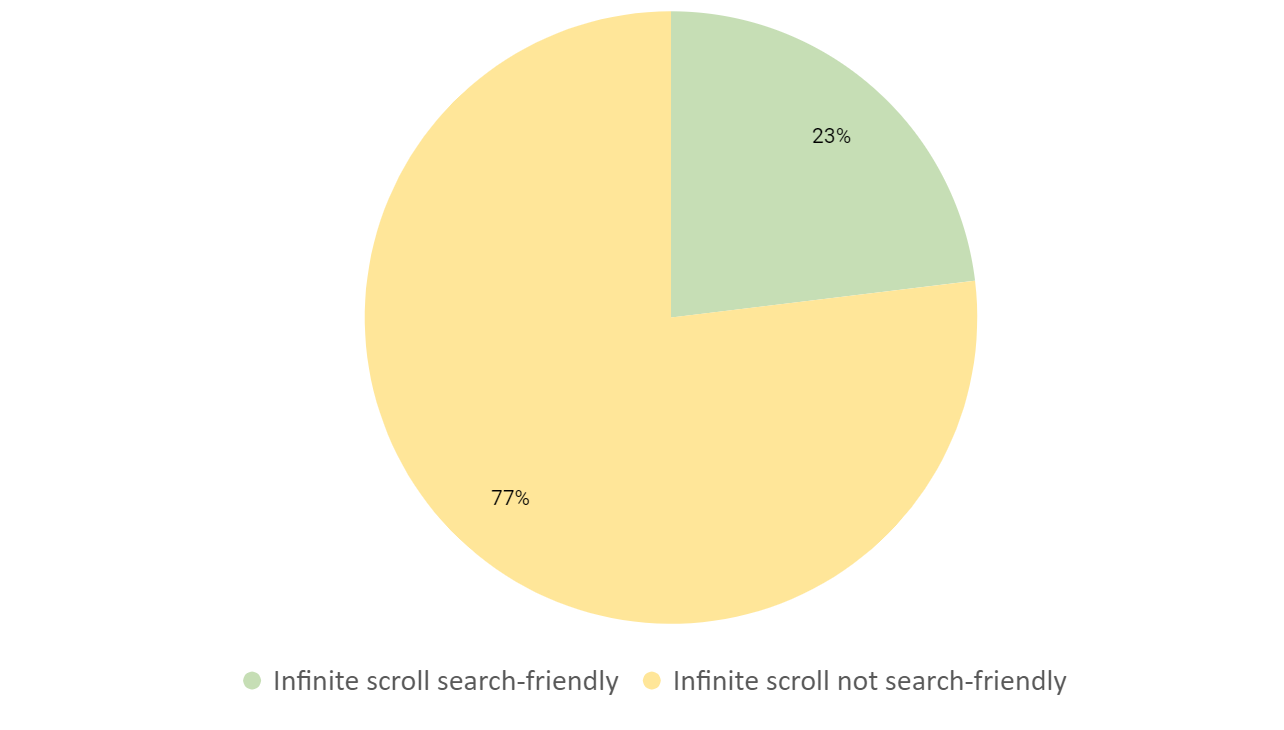
繰り返しとなりますが、さらに読み込む+遅延読み込みの単一ページデザインと同様、このデータを分析すると基本的な最適化手法が不足していることが分かりました。
一意のURLのあるページ分割されたコンポーネント
コンテンツをGoogleにクロールおよびインデックスさせるためには、ページにURLが割り当てられていることが必要です。Googleにクロールやインデックス、コンテンツの掲載順位を決定させるにあたりURLが必要です。無限スクロールのデザインのサイトコンテンツがインデックスされるようにするためには、各ページ分割コンポーネントにURLを割り当てることが最も効果的です。
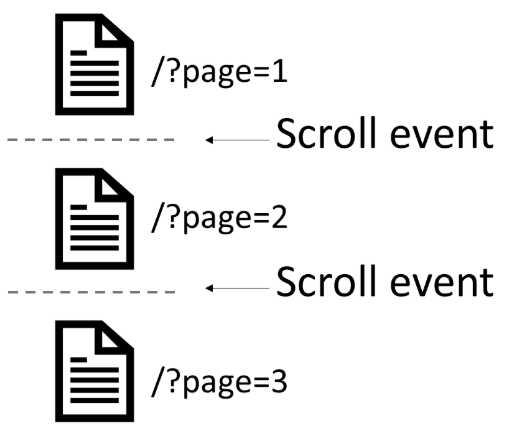
検索エンジンにとって無限スクロールはページ分割されたページと類似していますが、ユーザーはページ分割された各ページをスクロールするように閲覧していきます。このコンセプトは実装しやすいものだと思われますが、残念ながらDeepCrawlが検証した無限スクロールを採用したサイトの多くがページ分割されたコンポーネントにURLを割り当てていませんでした(クロールデータを使用して手動で確認しました)。
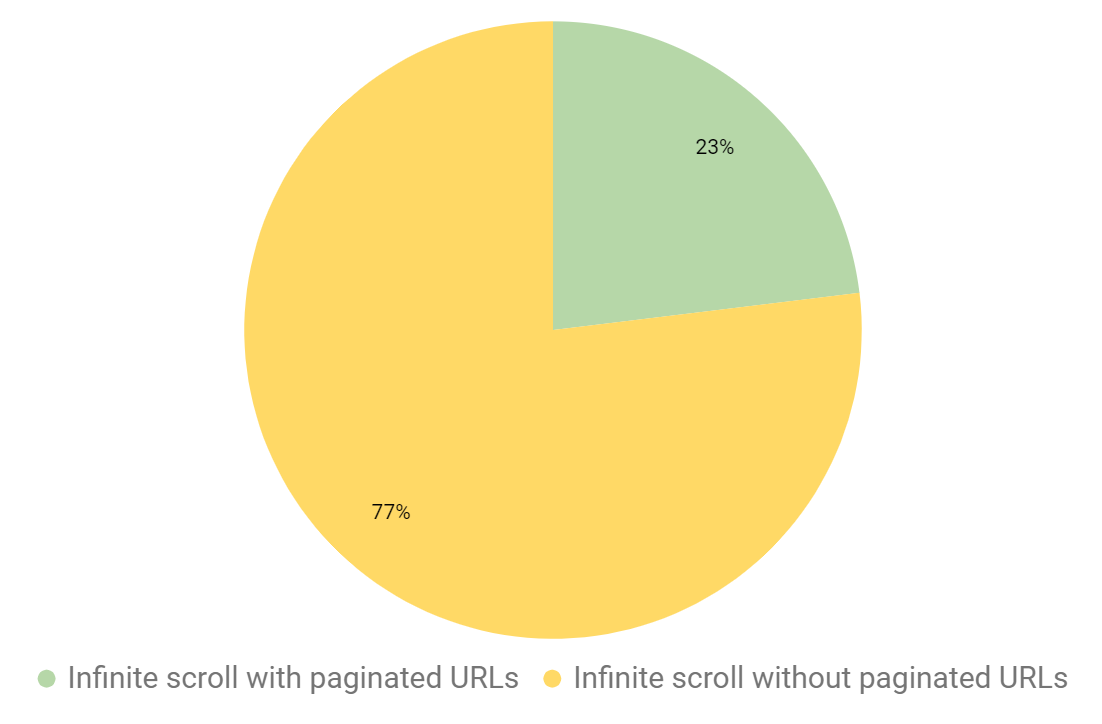
固有のURLがない(かつクロール可能なリンクがない)無限スクロールデザインのサイトの場合、DeepCrawlではURLが1件のみ表示されます。
固有のURLがあるサイトをテストする場合、ユーザーがスクロールに従ってこれらがブラウザ上に表示されていきます。
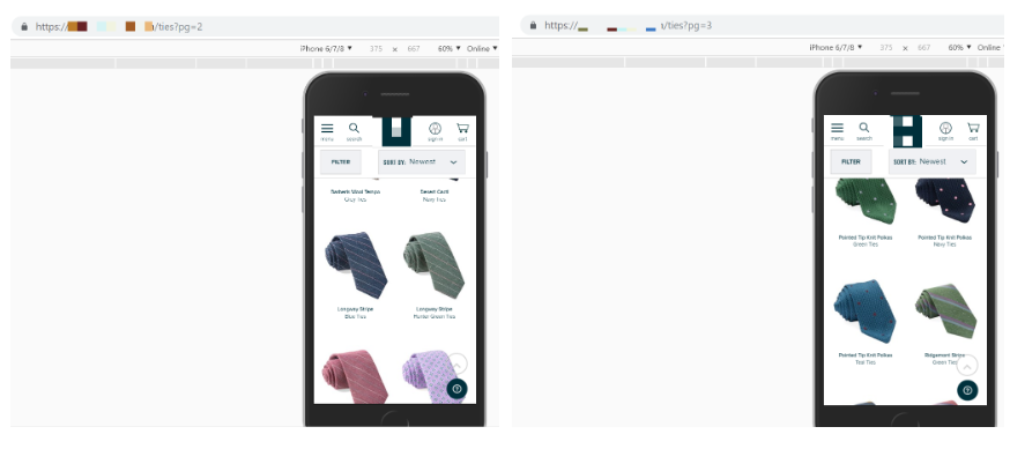
ページ分割されたURLを無限スクロールに割り当てた多くのサイトでは、ユーザーが現在位置を認識できるよう、ブラウザのURLの更新にHistory APIのpushStateメソッドを使用しています。これはクロールやインデックスに必要な手法というものというよりは、ユーザーがサイト上でどこにいるのかを理解するのに役立ちます。
対策:
- CMSやウェブアプリ上で無限スクロールを採用しているコンテンツのコンポーネントに一意のURL(動的もしくは静的)がマップされていることを確認する
- History APIを使用できる場合、ブラウザのURLを更新してユーザーが商品や記事のページのどこにいるのか分かりやすくする
クロール可能なリンク
内部リンクの実装は、Googleがサイト上のページ分割されたページの発見およびクロールを行うために重要です。無限スクロールを採用した単一ページデザインにクロール可能なリンクを追加するのには少し注意が必要です。
Iページネーションとさらに読み込む+遅延読み込みのデザインは、いずれもユーザーがクリックして先に進めることものといえます。これに対して、無限スクロールのデザインでは、ユーザーはクリックすることなく分割されたコンテンツ全体をスクロールしてシームレスにコンテンツを閲覧できます。
つまり、ユーザーがより多くのコンテンツを表示し続けるために何らかの要素をクリックする必要がないため、サイトデザインの一部として内部リンクを追加することが難しいと言えます。John Mueller氏は無限スクロールのベストプラクティスを例示するためのサイトを作成していますが、これを参考にして適切に内部リンクの追加を行なったサイトはほとんどありませんでした。
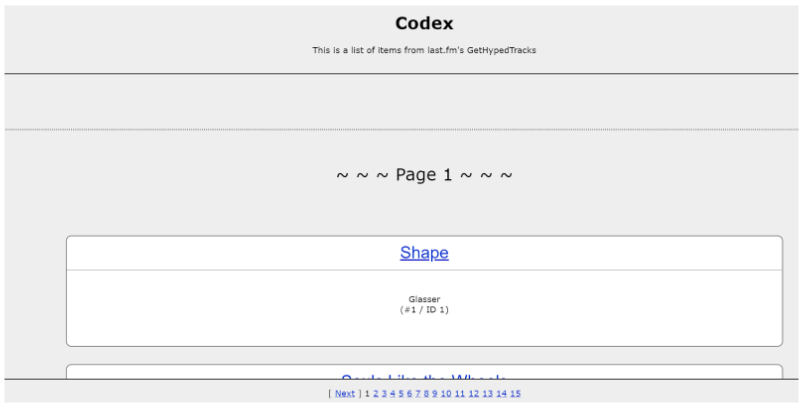
画像23 – John Mueller氏による無限スクロールの模範サイト
モバイル端末上でこのサイトをテストしていると、ユーザーがそのリンクを見えないほどに内部リンクのコンポーネントが縮小されていました。
画像24 – モバイル端末上のJohn Mueller氏による無限スクロールの模範サイト
これではモバイルユーザーが至適なユーザー体験を行う事ができませんし、ページ分割コンポーネントに移動することはほぼ不可能です。これがより良い方法で実装されているか調査するため、我々は検索最適化基準を満たしたサイトの無限スクロールをテストしました。
簡単に分析を行うと、クロール可能なリンクのある無限スクロールデザインでは、ページのソースコード上でアンカーリンクのhref属性にページ分割したコンポーネントを指定していることが分かりました。

すべての無限スクロールデザインにおいて隠された(つまりページ上では非表示の)クロール可能リンクを使用していたということは注目に値するでしょう。サイトのページ分割されたコンテンツがインデックスされているか確認したところ、Googleの検索結果にそれらのコンテンツが表示されていました。
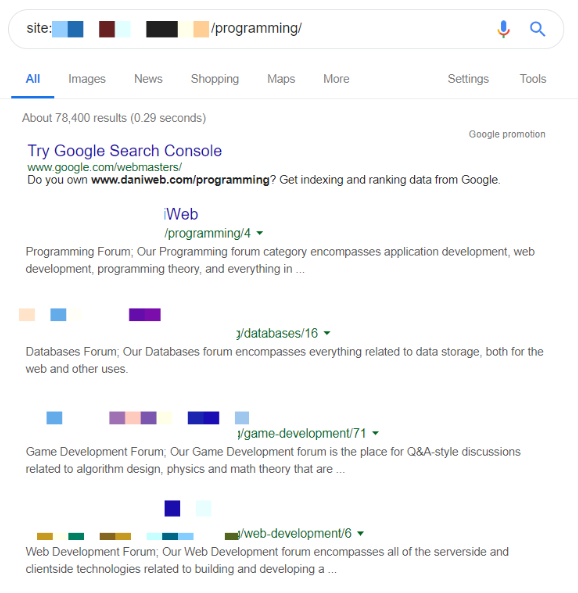
Googleサーチコンソールを使用せずにこれらのページ分割されたページが正規URLであることを完全に実証する方法はありませんが、これらのページがサイト運用者にに表示されているということは、Googleによって発見およびクロールされたということを意味します。
注意:サイト管理者は、無限スクロールのデザインに非表示のクロール可能リンクを追加する際には最新の注意を払わなければなりません。隠しリンクは、一部のサイトでは機能しているように見えますが、アルゴリズムからは不正であり、Googleのウェブマスターポリシーに違反していると判断される可能性があります。しかしこれは少し曖昧な部分であり、ユーザーと検索エンジンのボットが見ているのは同じコンテンツであり、隠しリンクはボットに対してコンテンツをクロールしやすくしているのです。
Google検索で簡単に調べてみたところ、無限スクロールのデザインにクロール可能なアンカーリンクを追加することに関して役立つ解決策は無いようでした。Googleディベロッパーやヘルプドキュメントでも答えは見つかりませんでした。残念ながら、このブログ記事を書いている現時点ではサイトの無限スクロールデザインにクロール可能なリンクを追加するための明快な解答が無いようです。そのため、テクニカルSEO担当者が開発チーム、プロダクトマネージャそしてデザイナーと連携して業務を行うことで無限スクロールにアンカーリンクを追加する最も良い方法を探っていくことが重要です。
対策:
- 無限スクロールのページ分割されたページ要素にhref属性をもつアンカーリンクを追加して、他のページ分割されたページにリンクさせる(実際の実装難易度は低くない)
- 開発チーム、プロダクトマネージャ、デザイナーと連携して業務を行い、無限スクロールデザインにクロール可能なリンクを追加する
- 新しいデザインで最小限の実行可能なテストサイトを作成し、実行環境に移す前に、検索エンジンがページ分割ページにアクセスできるかどうか確認するためにテストクロールを実施することを強く推奨する
rel=“next” と rel=“prev” への依存
無限スクロールのデザインにおいてよくあるパターンとして、多くのサイト管理者がページ分割されたページへのリンクを行う場合に rel=“next” と rel=“prev” に大きく依存している場合があります。これらは、このタイプのデザインでページ分割されたページへ内部リンクする際にアンカーリンクを使用しません。
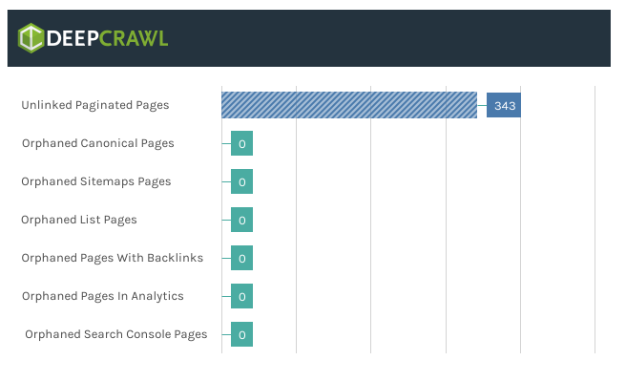
前述の通り、Googleはインデックスの際にリンク要素の rel=“next” と rel=“prev” のサポートを終了したことを発表しました。しかし、簡単なテストを行ったところ、検索エンジンはこれらのリンク要素をページ分割ページの検出にも使用しないことが判明しました
1/3 **TEST IN MUNICH**
Q: Does Google crawl URLs in rel=next and rel=repv?
H: I thought Gbot would treat similar to <a href> element.
R: 1 week and 3 days checking log files Googlebot still hasn’t crawled URLs found in rel=“next” and rel=“prev” <link> elements. pic.twitter.com/VVcjwTQEPB
— Adam Gent (@Adoubleagent) 1 April 2019
これはサイト管理者が rel=“next” と rel=“prev” をクロール可能なリンクの代わりとして使用しようとしていた一方で、もしこれらが内部リンクやXMLサイトマップで見つからない場合、Googleはページ分割されたページをクロールしないことを意味しています。
対策:
- Googleのコンテンツ検出のためにリンク要素 rel=“next” と rel=“prev” に依存しないこと。テストではアンカーリンクにページを含めることが重要であることが判明した。
インデックス可能なページ分割されたページ
前述の通り、検索エンジンがリンクを辿りコンテンツの評価に使用するために、ページ分割されたページが検索エンジンによりインデックスされ、正規URLとして選択されることが重要となります。
少数の無限スクロールデザインのサイトにはページ分割URLがあり、DeepCrawlのクローラーに検出されましたが、一連の最初のページに正規化されてしまいました。
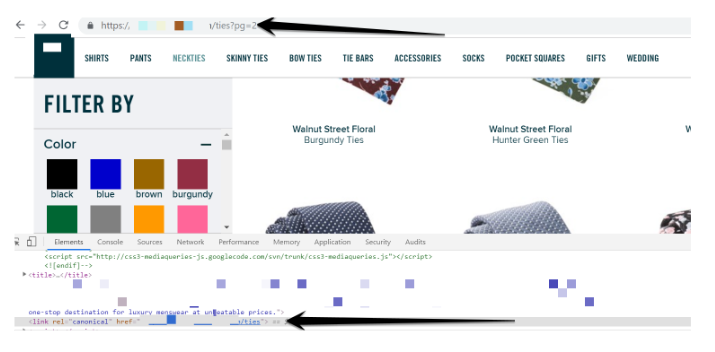
rel=canonicalリンクタグを使用して最初のページに戻すようにすることは、Googleや他の検索エンジンに1ページ目の後のページ分割されたページをインデックスしないように伝える上で、強力なシグナルとなります。これにより、ページ分割されたページがインデックスから除外されるため、2ページ目以降のページ上にある内部リンクはGoogleによって巡回されなくなります。
深い階層のページへ繋がる唯一のアクセスポイントである重要なページ分割ページが、Googleのインデックスから除外されないように注意しましょう。
対策:
- サードパーティのクローラーを使用して無限スクロールサイトデザイン上のNoindexもしくは正規化されたページ分割ページを検出する
- URL検査ツールを使用して、Googleのインデックス上でのページ分割ページURLの状況を調べる
- インデックスカバレッジレポートを使用して、ページ分割ページのインデクサビリティをモニタリングする
重複したページ分割ページ
DeepCrawlのクロールデータでは、無限スクロールのサイトデザイン上でのコンテンツ重複は検出されませんでした。しかし他のサイトデザインと同様に、すべての重要なページ分割ページには一意のコンテンツが含まれていることが必要です。コンテンツが重複もしくは類似している場合、Googleが正規URLを選択するためインデックスからページを除外してしまう可能性があります。
対策:
- DeepCrawlのようなサードパーティツールを使用してサイト上の重複したページ分割ページを検出する
- SEOベストプラクティスである重複もしくはファセットナビゲーションを使用してGoogleが正規化URLとして使用するページ分割ページを指定する
まとめ最後に
この記事でご紹介した、ウェブ上のページネーションデザインをクロールする調査および検証の結果が、一般的な技術的落とし穴の特定の役に立ちましたら幸いです。小規模なクロールでの検証を通じて、SEO担当者にサイト上のページネーションの最適化方法を知っていただくことがねらいでした。
本記事では言及していませんが、ページネーションを管理および最適化する際に考慮が必要なことを数多く発見したので、今後数ヶ月でさらに検証を行なっていきたいと考えています。
ページネーションの最適化および管理の詳細なSEO手法については、DeepCrawlのページネーションに関するテクニカルSEOガイド(rel=“next” and rel=“prev”の代替)をご覧ください。
DeepCrawlでサイトのページネーションの管理と最適化を始めましょう
ぜひDeepCrawlのご利用をご検討ください。サイトのページネーションデザインにおける技術的な問題を見つけましょう。

