サイト
サイト(またはサイトのセクション)でクロールを実行しているときに、URLの最初のレベルを超えてクロールが進行していない場合があります。これが発生すると、ベースドメイン、つまり開始URLのみしかクロールされていないことになります。
この問題には、いくつかの原因と、問題を修正できるさまざまな方法があります。これらは、基本的なソリューションとともにまとめられています:
| 内容 | 解決法 | |
| 1 許可されていないURL | Robots.txtファイルを確認する | |
| 1 接続エラーのあるURL | JavascriptまたはiFrameリンクの問題を確認 *最初のURLにはリンクがありません |
|
| 1 接続エラーのあるURL | ブロックされたユーザーエージェントまたはIPアドレス | |
| 0 URLs Returned | 不正なベースドメインのプロジェクト設定を確認する | |
| 1 ステータスコード200を返す インデックス可能なURL |
詳細設定を確認:含まれているURLの制限Robots.txt File |
これは、たいていの場合norobots.txtファイルに問題があります。このファイルの内容により、サイト自体がクローラーのアクセスをブロックする場合があります。
ほとんどのクローラーは、検索エンジンボットのスパイダーと同じルールに従うことを目指しており、これにはrobots.txtファイルの指示に従うことも含まれます。
したがって、サイトが次のように設定されている場合、最初のページ以降はクロールされません:

これは、ステージング環境が稼働前にクロールする場合によく発生します。
クロールを許可されていないことが、許可されていないURLレポートに表示されます。
Lumarの問題の修正
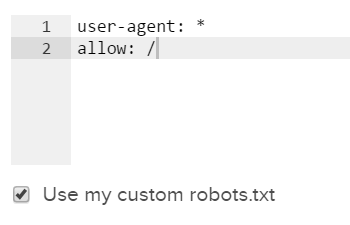
クロール設定のステップ4の下部にある詳細設定を使用して、robots.txtファイルを上書きし、ブロックされたURLへのLumarアクセスを許可することができます。
次の設定を追加することにより、Lumarはライブファイルではなく、このセクションで設定されたルールに従います:
JavascriptまたはiFrameリンク
Webサイトのページをクロールするとき、クローラーはベースドメインまたは開始URL設定に入力されたURLからクロールを開始します。到達した最初のページでリンクが検出されない場合、クロールは続行できません。
開始URLがJavascriptを使用して動的に生成される場合、クローラーがたどることができるHTMLに検出可能なリンクがない場合があります。これは、開始URLのリンクがiFrame内にある場合にも該当します。
Lumarの問題の修正
これらがプロジェクト内のすべての開始URLに当てはまる場合、クローラーはサイトをクロールできません。
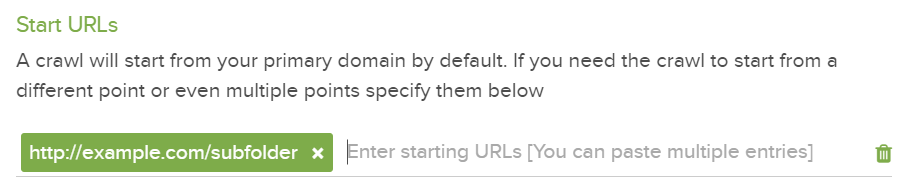
ただし、これが最初のURLだけに起きている問題なのであれば修正することができます。詳細設定の開始URLセクションを使用すると、リンクがiFrameまたはJavaScriptで生成されたURLのどちらにもないページでクロールを開始することができます。
もう一度「開始URL設定」を使用して、制限されているサイトのセクションからクロールを開始できます。
つまり、これらのリンクを検出して追跡することができ、クロールが正常に完了します。
クローラーがJavascriptで生成された追加ページを見つけた場合、続行できないことに注意してください。そのため、クローラがサイトのセクションを見逃す可能性があります。
最初のURLにリンクが存在しない
時々、最初のページにリンクが上がらないことがあります。これは、このページの訪問者に対する何らかの制限がある場合に発生します。(例:アルコール飲料に対する年齢制限):

クローラーは、ステータスコード200のインデックスが可能なURLを返します。また、固有のページである可能性もあります。
Lumarの問題の修正
ここでも、 URLの開始設定を使用して、制限されているサイトのセクションからクロールを開始することができます:
ユーザーエージェントまたはIPアドレスがブロックされる
クロールで検出されたURLが1つのみで、そのURLから接続エラーが発生する場合は、クローラーがブロックされている可能性があります。これは通常、ユーザーエージェントまたはIPアドレスのいずれかがブロックされることで発生します。
たとえば、Google以外のユーザーエージェントを自動的にブロックするようにサイトを設定したり(他の検索エンジンでも検索できます)、クロールの発信元のIPアドレスをブロックするように調整されたファイアウォールをサイトに実装することなどが可能です。
Lumarの問題の修正
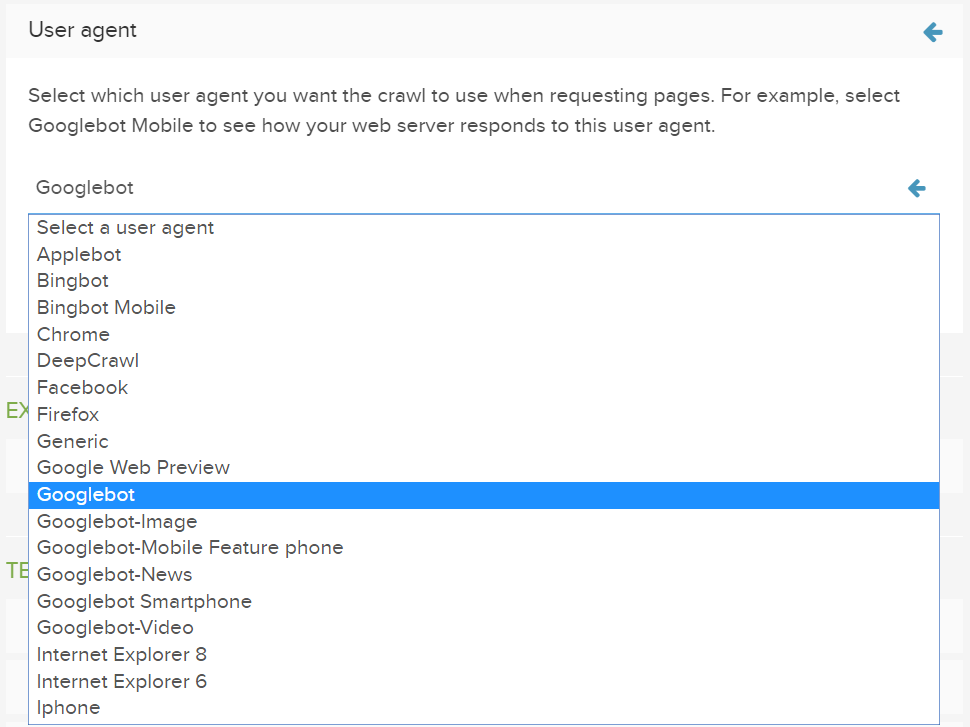
ユーザーエージェント経由でブロックが発生した場合は、下記以下画像のように利用可能なリストから別のユーザーエージェントを選択するか、独自のカスタムユーザーエージェントを使用することができます:
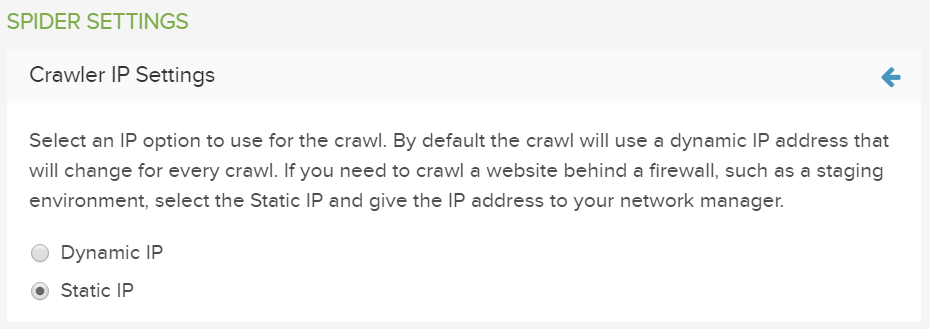
ブロックされているのがIPアドレスの場合は、 スパイダーIP設定で指定されている スタティックor 静的IP アドレスを使用し、このアドレスへのアクセスを許可することができます。
クロール設定
クロールの設定によって、1つのURLのみが返還される可能性があります。
不正なベースドメイン
クロールのセットアップ中にベースドメインを プロジェクトの設定に入力すると、Lumarによって自動的にドメインがチェックされ、(ドメインが)リダイレクトされている場合は警告が表示されるようになります。
場合によっては、ベースドメインのリダイレクト先のバージョンをクロールしないことを選択できます。この場合、クロールでは、301または302のステータスコードを持つURLが返還されることがあります。
これは、Lumarがベースドメインに一致するURLのみをクロールするためです。サイトは、httpではなくhttpsまたは、別のTLDか別のドメインである可能性があります。
同様に、サイトがIPに基づいてリダイレクトされるように設定されている場合もございます。つまり、サイトは再びクロールの範囲外になってしまいます。
プロジェクトの設定の ベースドメインセクションにURLを入力すると、Lumarはその特定のドメインのURLのみをクロールし、リダイレクトされたURLのリンクはたどりません。
コンテンツが実際にサブドメインでホストされている場合もあれば、ベースドメインにホームページしかないサブドメインがいくつかある場合もあります。この場合、これらのサブドメインは、特に要求されない限りはクロールされません。
Lumarの問題の修正
プロジェクト設定で、入力したベースドメインが正しいかどうかを確認できます。下記の確認が重要です。
- 正しいプロトコルが選択されている(httpまたはhttps)
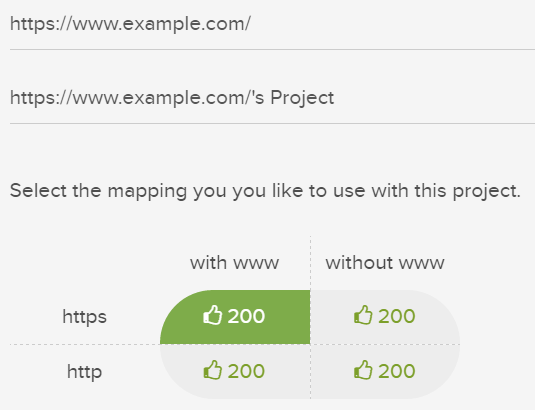
コンテンツがサブドメイン上にある場合は、それらのページへのリンクをたどることができるように、 サブドメインのクロール チェックボックスがオンになっていることも確認する必要があります。
含まれるURL
クロールするサイトを1つ以上の特定のセクションに制限している場合は、これらの制限が原因でクロールを実行できない可能性があります。
Lumarの”Included Only” 設定を使用すると、サイトの特定のセクションのみをクロールし、他のすべての領域を無視することができます。この一環として、ベースドメインからリンクされていない限りは、そのセクション内に ”開始URL”を指定する必要があります。
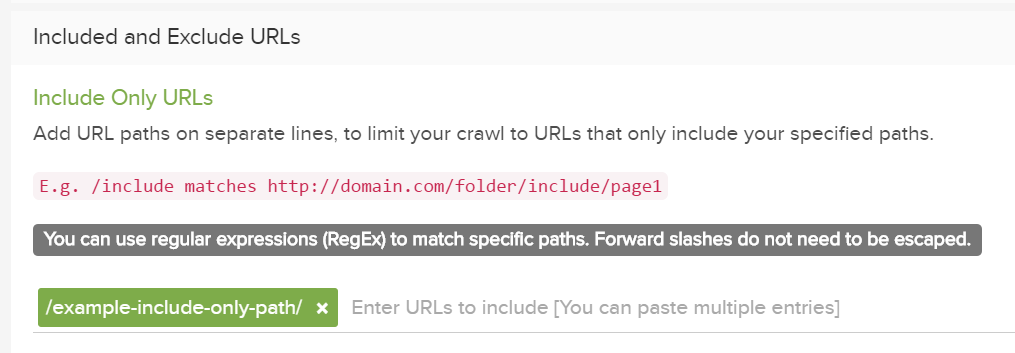
ただし、開始URLからのリンクが”Included のみ”設定で参照されているフォルダ内にない場合は、クロールの範囲外になります。
Lumarの問題の修正
この問題に対処する最善の方法は、開始URLを、そのセクション内の”URLへの内部リンクを持つフォルダ内のページ”に変更することです。