While parameters are a dream for analytics boffins or developers, their tendency to create hundreds of thousands of URLs out of a few pages mean they can be a headache for SEOs.
The key is to understand how to handle them, whether that’s with clever design, disallow directives, canonical tags, Google/Bing tools or stripping them out.
In this post we’ll first go throuhogh some simple rules for designing your parameters, before going through how to take back control and soothe that headache…
Designing parameters: making filtering easier
Paths vs. Query Strings
Parameters can be included as URL paths or added to the end of the URL as a query string in ?name=value format.
Example of a parameter in the URL path:
- https://example.com/dresses/blue/
Example of a parameter in a query string:
- https://example.com?category=dresses&category=blue
Including in the URL path creates nicer URLs, but makes stripping and filtering more complicated. URL path parameters are also not supported by Google and Bing’s URL handling tools.
Generally, it’s best to include any parameters that you don’t want to be indexed in search results (tracking parameters, for example) as query strings, and use URL paths for parameters that generate indexable pages. This makes it easier to generate clean canonical URLs that don’t include any query strings.
Provided query strings are canonicalized to a primary version, there should be no issues concerning duplicate content.
Using # over ? in query strings
Google completely ignores everything in the URL after a hash, so using them strategically is a common technique for ensuring that parameters are ignored by all search engines.
For sites using AJAX content, Google provides a method for ensuring that anything after the hash is crawlable, which involves adding #! instead of just #:
Original:
- example.com/document#resource_1
With crawlable hashbang fragment:
- example.com/document#!resource_1
Which will mean Google will request the following URL from the server, allowing it to be crawled.
- example.com/document?_escaped_fragment_=resource_1
More information on AJAX content and hashbangs is available in the following guides:
- Google Developers: Make your AJAX application crawlable
- Search Console Help: Guide to AJAX Crawling for webmasters and developers
- Search Engine Land: Google May Be Crawling AJAX Now – How To Best Take Advantage Of It
- DeepCrawl Guide: How to Crawl AJAX Escaped Fragment Websites
Designing parameters: avoiding duplication
Ordering and naming
Make sure your parameters appear in a consistent order, using a consistent naming structure, to avoid duplication.
Example one: inconsistent order/name:
- com/women/dresses/blue.html
- com/dresses/blue.html
- com/women/red/dresses.html
Example two: consistent order/name:
- com/women/dresses/red.html
- com/women/dresses/blue.html
SessionIDs
Some are automatically stripped (eg. Google Analytics utm_ query strings) but don’t rely on this. Avoid including ‘id’ in the name of any query string that you DO want indexed, as Google might misinterpret them.
Pagination
You should use the same parameter in every page in a paginated set; nothing else should change in the URL. Avoid duplicating page one of a paginated set with a URL with and without a page=1.
Query strings actually make it easier for Google to discover a set of paginated URLs, as they can all have a consistent base URL path, with a single changing query string.
- html?category=a§ion=b&page=1
- html?category=a§ion=b&page=2
- html?category=a§ion=b&page=3
Repetition
Avoid using multiple parameters with the same parameter name and a different value.
- ?colour=blue&colour=red&colour=green
User session parameters
Any parameters that are unique to a user session shouldn’t be included in the URL. If they are required, they should be disallowed, which may require some planning for the URL format.
Options for handling parameters
Canonical tags
The meta canonical attribute is recognized by all search engines, but is not so good for crawl efficiency as search engines have to crawl the URL first in order to see the canonical tag.
Disallowing
Blocking parameters means search engines won’t crawl them, which increases crawl efficiency, but means search engines can’t consolidate authority signals like backlinks (simply because they can’t see the pages).
Preventing search engines from crawling a page also means indexable pages (facets/facet combinations in ecommerce sites, for example) won’t get crawled and might not appear in search results. If they do appear (because they are linked elsewhere, for example) they probably won’t appear how you want them to, since search engines won’t be able to look at the page in order to get the meta title and description.
For more information on how disallowed pages can be indexed, see our post on noindex, disallow and nofollow .
John Mueller discussed this in a recent Google Webmaster hangout; he initially recommended against disallowing parameters, but then admitted there are occasions when crawling efficiency is more important than consolidating authority signals.
Google Search Console / Bing Tools
Using Google Search Console’s URL Parameter tool and Bing’s Ignore URL Parameters tool means search engines will ignore the URLs with the parameters completely. They shouldn’t try to crawl them at all, but they can access them if needed, meaning this method is better for crawl efficiency and doesn’t come with the same drawbacks as disallowing.
Stripping
Stripping the parameters from your URLs solves all problems when it comes to SEO, but also removes any possibility of using them for your advantage in other areas of the site (analytics, for example).
Tools for parameter management
Google Search Console
Specify how you want Google to treat your parameters in your Search Console account under Crawl > URL Parameters > Add Parameter.
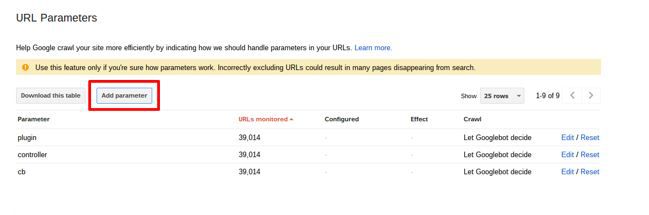
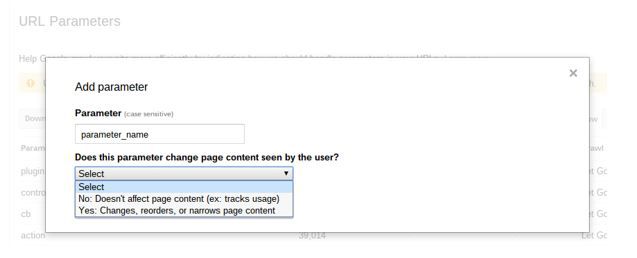
Google call this feature a ‘helpful hint’ for how they should crawl URLs. It’s not as strong as a no index or a disallow (these are ‘directives’, not ‘hints’) as it only tells Google how to treat the URLs with the parameters, rather than blocking/deindexing them completely. Still, it’s very useful for controlling parameters, where disallowing and/or noindexing are too restrictive.
Bear in mind that this tool only supports query structures using key values, eg:
- com?category=dresses&category=blue
Not those with plus signs, paths, or another type of encoding:
- com/dresses+blue.html
- com/dresses/blue/
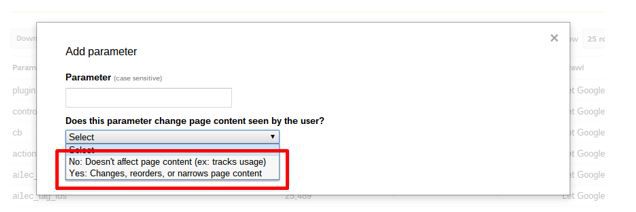
Once you’ve added your parameter name (eg. utm_source or instance_id) you will see two options for telling Google whether your parameter changes the content as seen by the user:
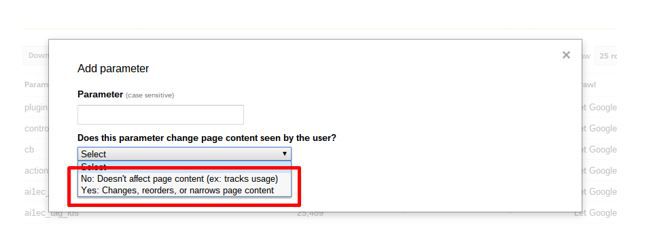
To stop your parameters being indexed as separate pages and to avoid duplicate content issues, there are two very similar options for this tool:
- No, doesn’t affect page content
- Yes the parameter does affect page content, but No URLs with this parameter should be crawled.
The ‘No’ option
Selecting the ‘No’ option here tells Google that the content will not be changed depending on whether the user sees a page with a URL with/without the parameter added.
With this option applied, Google will just pick the version of the URL that it thinks is primary and should only index that version. You might still see multiple versions show up for a site: search, though.
This option is useful when applied to parameters like tracking applied to navigation or referrers, that don’t affect the user but that are useful for tracking how people use your site.
The ‘Yes’ + ‘No URLs’ option
Selecting the ‘Yes’ option tells Google that, if the user views a page with this parameter added to its URL, the content will look/be different to a user compared to a URL without the parameter.
Using ‘Yes’ with the No URLs option tells Google that, while the content is different for each of these parameters, each version still shouldn’t be indexed as a separate page.
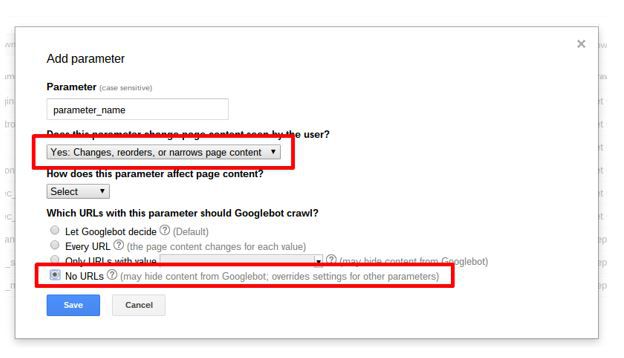
This is useful when dealing with things like search facets that you don’t want indexed.
Google’s John Mueller discussed this in a Webmaster Central hangout in April 2015, and stated that the Yes option means that Google will not crawl any of your URLs that have this parameter applied, and won’t try to select a primary version to index:
If you do a general site: query to check whether your changes are reflected in search results, bear in mind that the changes might not appear for a couple of months. For site: queries with other queries attached (eg. site: example.com inurl:https) the versions that are not indexed could still appear. John Mueller also discussed this in the Webmaster Central hangout above.
For more information on using the Search Console URL Parameters tool, including other options for the ‘Yes’ option, see the Google Support post on categorizing parameters, and watch Maile Ohye’s advanced tutorial below:
Bing Webmaster Tools
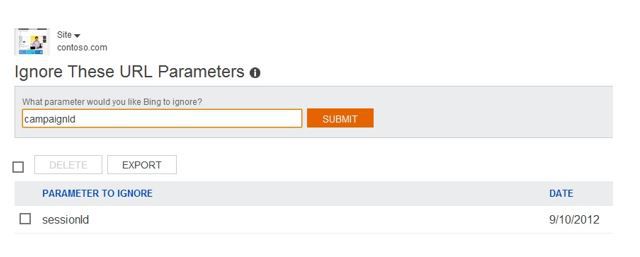
To exclude parameters in a similar way for Bing, simply add the parameter name in Configure My Site > Ignore URL Parameters.
Note that there are no advanced options for identifying whether a parameter will change the content on the page: Bing state that ‘you should only add a parameter to ignore if you are sure that the URL parameter is not needed for your content to be shown correctly’.
Google Analytics
Google views URLs with different parameters as separate pages, and Google Analytics reflects this, showing you pageviews for each different parameter.
This can be very useful if that’s what you intended but if not you can remove the parameters from your reports and consolidate pageviews into the figures for the primary URL in Admin > View Settings > Exclude URL Query Parameters:
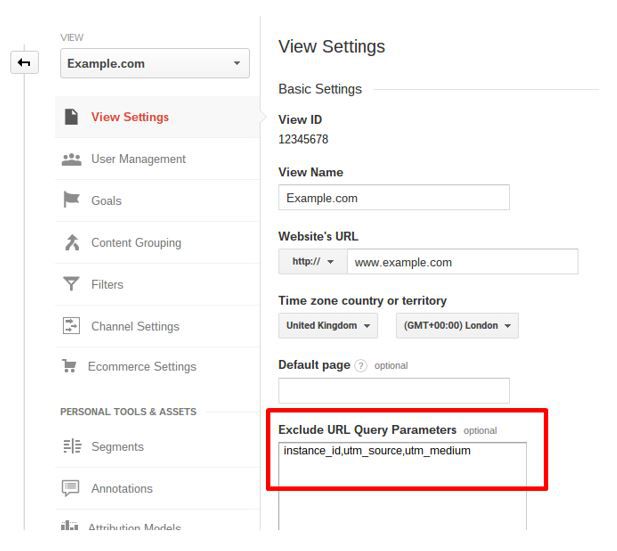
Note that this method is irreversible, meaning your data will be changed and any errors will be permanent. To avoid affecting your current data, it’s recommended that you create a new profile to do this.
DeepCrawl
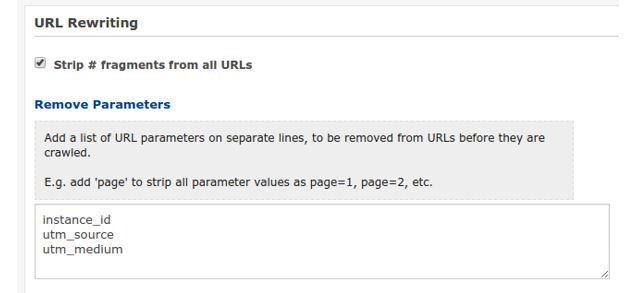
Mimic and check your Search Console URL Parameter set-up for your crawl by adding your blocked parameters in the Remove Parameters field under Advanced Settings > URL Rewriting; they will be stripped from the URLs before they are crawled. This will ensure that the report reflects how Googlebot will behave, providing you have Googlebot set as your User Agent.