

BrightonSEO April 2019 was another resounding success. We all enjoyed a strong line-up of speakers and excellent talks across the different tracks, free beer and mini golf in the DeepCrawl beer garden, an actual iron throne, and so much more. There really was something for everyone!
Also, this happened at @brightonseo #BrightonSEO #got #GameofThrones pic.twitter.com/l3sUhsCPhE
— Alizée Baudez (@AlizeeBaudez) April 14, 2019

I’ve written up the key takeaways from the talks I attended during the conference, which were:
- Polly Pospelova – How to Get a 100% Lighthouse Performance Score
- Chris Simmance – How to Trim JS, CSS & External Stuff to Slim Down & Speed Up Your Site
- Areej AbuAli – Restructuring Websites to Improve Indexability
- Nils de Moor – Living on the Edge: Elevating Your SEO Toolkit to the CDN
- Mike Osolinksi – CLI Automation: Using the Command Line to Automate Repetitive Tasks
- Tom Pool – How to Use Chrome Puppeteer to Fake Googlebot & Monitor Your Site
- Matthew Brown – The Circle of Trust: SEO Data
- George Karapalidis – Why Data Science Analysis is Better Than YOUR Analysis
Polly Pospelova – How to Get a 100% Lighthouse Performance Score
Talk Summary
Polly Pospelova, Head of Search at Delete, explained how a hackathon resulted in the Delete website achieving a 100% performance score in Lighthouse, and laid out the steps and processes that helped achieve this.
Key Takeaways
Even the biggest brands struggle to score well within Google’s Lighthouse testing tool because the criteria for performance and speed is always changing, making it very difficult to optimise websites accordingly.
The Delete website used to score 56 for performance in Lighthouse, so their team decided to hold a hackathon to see if this score could be increased to 100.
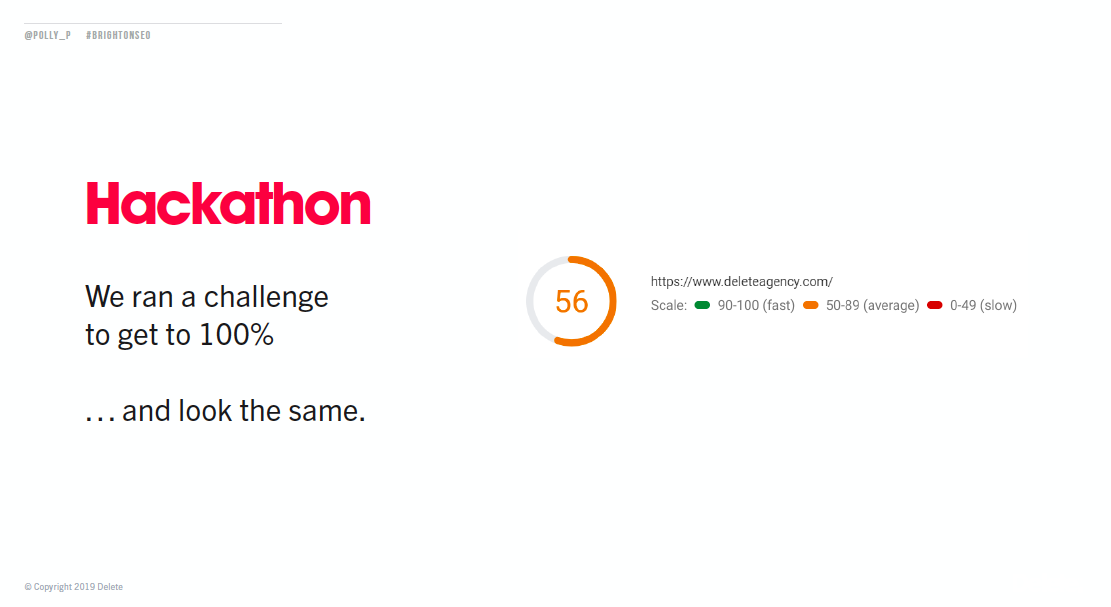
The hackathon went ahead, and the objective was achieved. The Delete website scored 100 across the board in Lighthouse.
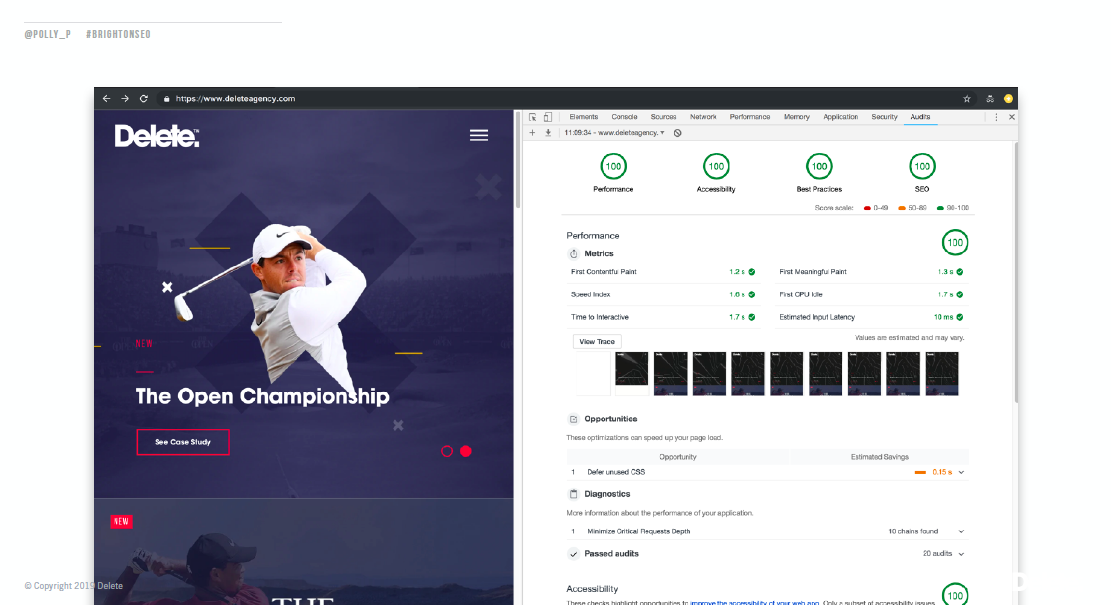
Let’s take a look at what was done to achieve these results and what implementations had the biggest impact.
Implementing HTTP/2
With HTTP/1, only 6 requests can be processed at the same time. With HTTP/2 however, all of the requests can be sent to the server in one go. This is especially effective for sites with a large number of resources such as fonts and styling.

Optimising images
Offscreen images were deferred until after critical resources had been processed and lazy-loaded to increase Time to Interactive, as not all images on a page are needed immediately for the user. This reduces the number of images that need to be loaded immediately, meaning a faster initial load time.
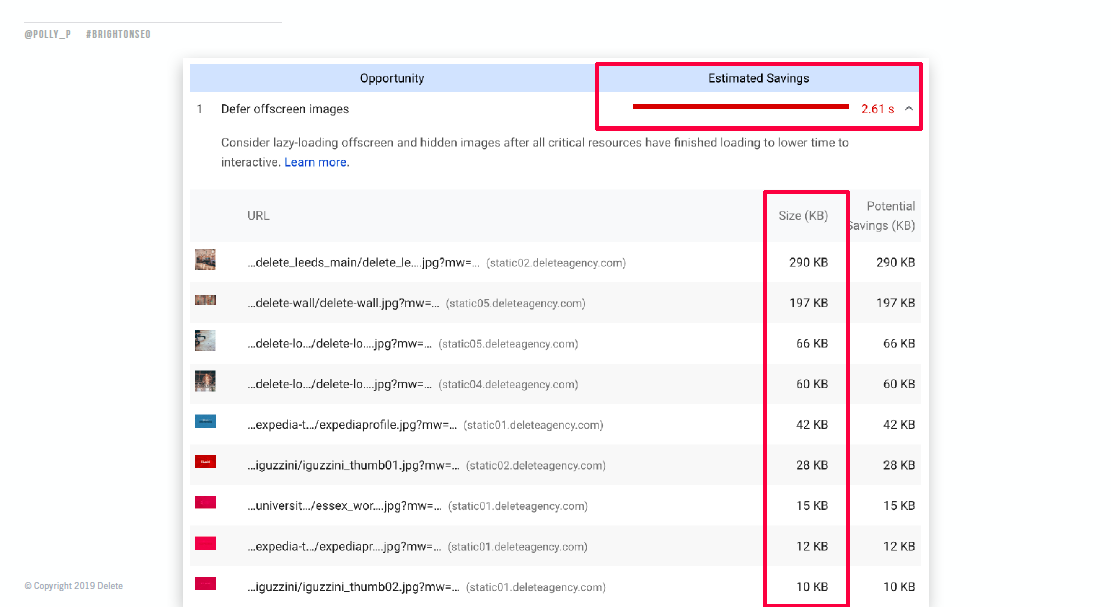
Images were also served in next-gen formats such as WebP instead of JPG or PNG, as the newer formats have better compression rates, meaning faster download times.
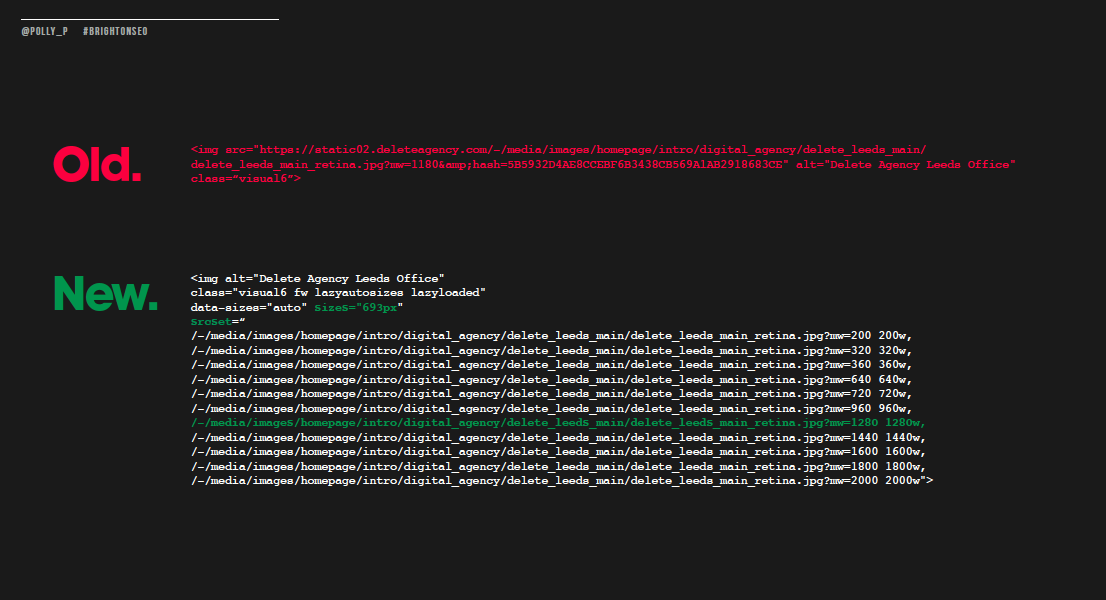
Adaptive image sizes were also implemented so that huge images weren’t being served regardless of the dimensions required. This means that the image with the dimensions most closely fitting target layout size will be selected, meaning the image will have a smaller file size than the full size one.
Splitting up critical vs non-critical code
Critical resources were served inline in the HTML, and non-critical resources were loaded in the background. The browser is blocked from rendering content until it has loaded all of the resources, so it’s important to make sure non-critical resources aren’t adding to this delay and that the browser is only waiting for the most critical resources before painting pixels to the screen.

For subsequent loads and repeat visits, if the browser already has a resource cached then it will be skipped for inlining.
Load only what you needed
Break up code into smaller files and specify the most important code and resources to be processed as a priority. Not all code on a page will be necessary. Here’s how this process was automated:
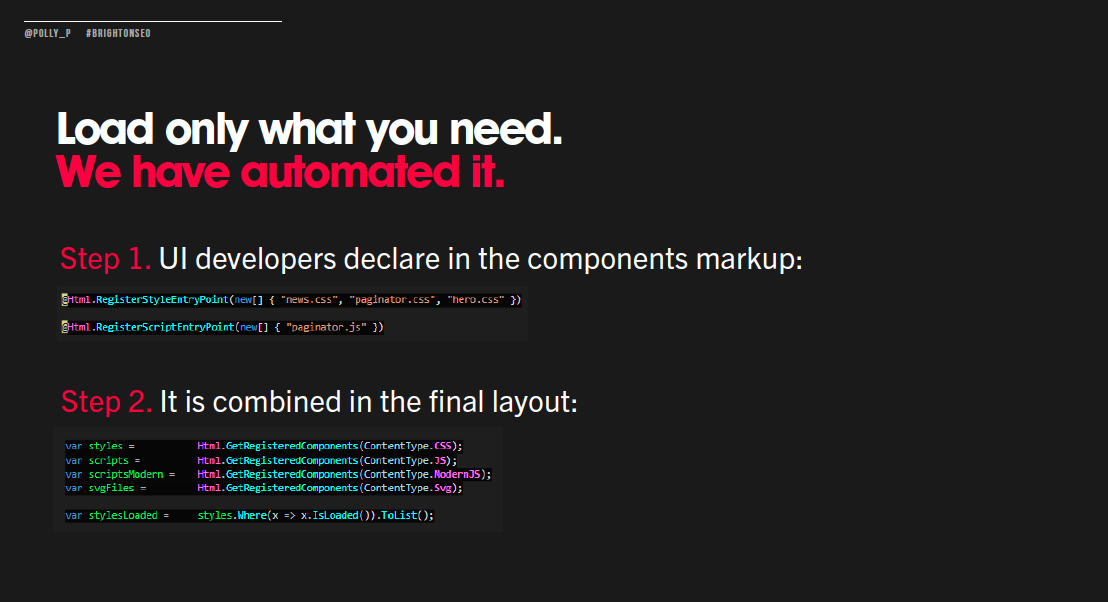
It’s crucial for SEOs to work more closely with developers and learn from them to be able to implement the latest performance fixes. This is especially important as what performs well today won’t perform well in the future. Continuing analysis and optimisation is a must.
Chris Simmance – How to Trim JS, CSS & External Stuff to Slim Down & Speed Up Your Site
Talk Summary
Chris Simmance, Chairman of Under2, talked about how to identify and trim down assets to reduce code bloat and improve overall site speed and performance.
You can find the link to Chris’ slides here.
Key Takeaways
The web is already under a lot of strain, and this is only going to get worse as the number of both people and bots online is going to keep increasing.
The main contributors to website bloat
These are some of the elements that contribute the most to the overall size of websites:
- Uncompressed, heavy media (such as images and fonts).
- 3rd party tools and APIs.
- Excessive plugins and widgets.
Look at the total page size and number of requests on a page to get an idea of how bloated it is.
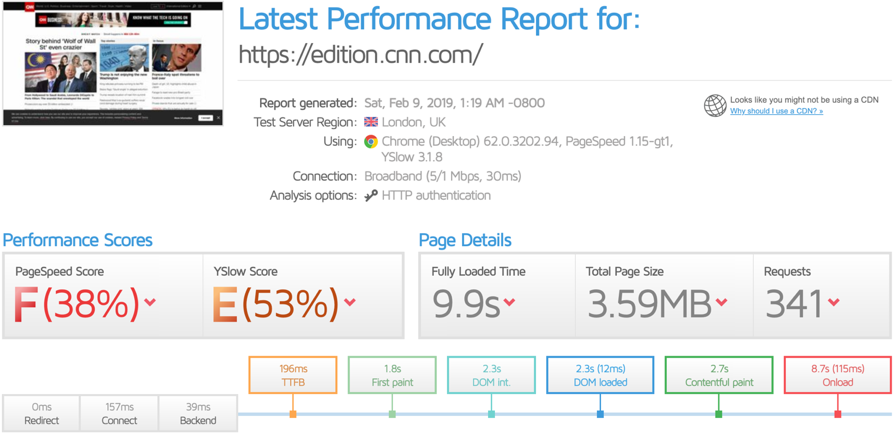
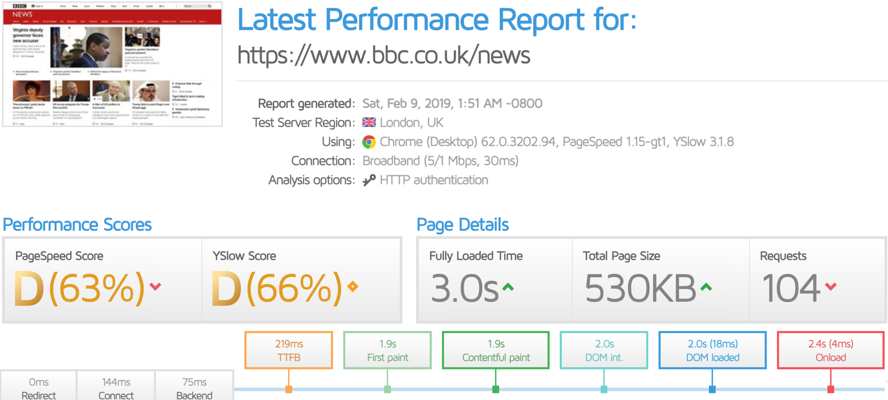
How to trim down & optimise large assets
Here are some tips on how to reduce the sizes of the assets on your site:
- Find unused, unnecessary code to remove.
- Minify code and use shorter selectors and naming conventions.
- Prioritise code that is necessary for loading above-the-fold content.
- Avoid using ads and trackers wherever possible.
- Use Babel to minify and refactor JavaScript.
- Use Base64 encoding to include images without an HTTP request.
- Use TinyPNG, Compressor.io and ImageOptim for image compression.
- Use progressive JPEG images which show the whole image but only with incremental bits of data, so it focuses in more detail during loading. This means an image is always on the screen rather than gradually filling in from top to bottom, which can improve the perception of load time for users.


The problem with fake minimalism
Some websites give the impression of minimalism through their design, but they are actually very resource-heavy in the back end.
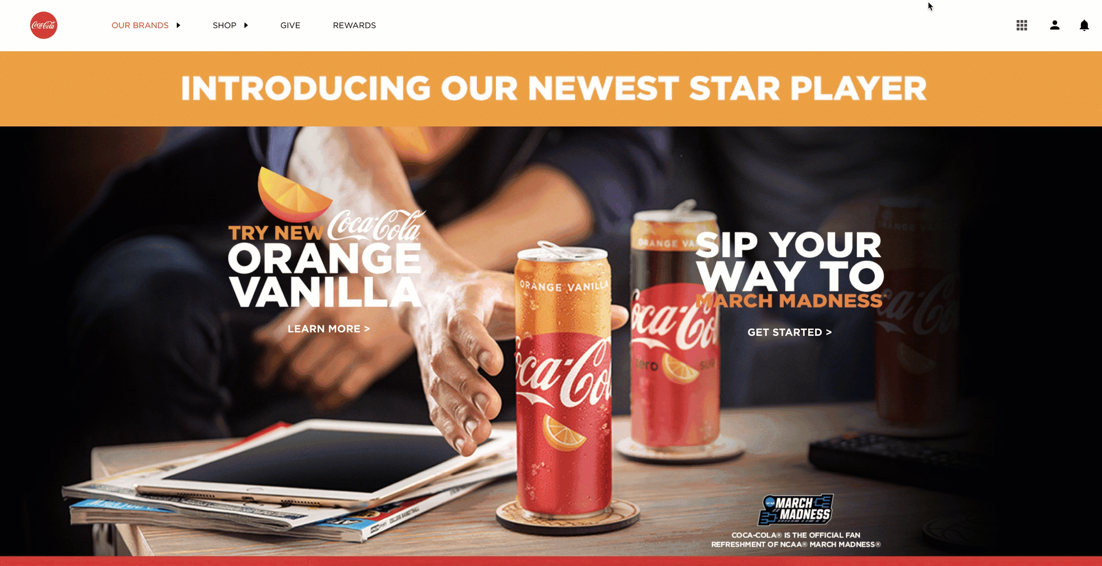
The Coca Cola homepage, for example, simply shows a header, an image and a footer, however, the page has over 4,500 lines of code which is a significantly large number for such a seemingly small page.

The web is full of overly large resources, so we all need to think more carefully about the way we build and maintain websites so we’re not unnecessarily contributing to the strain it’s already under.
Areej AbuAli – Restructuring Websites to Improve Indexability
Talk Summary
Areej AbuAli, Head of SEO at Verve Search, shared her learnings from a case study with a client of hers that struggled with crawlability and indexability, and what she did to try and turn performance around.
Key Takeaways
The main purpose of Areej’s talk was to explain the methodology she came up with to tackle crawling and indexing problems that she had encountered with a job aggregator client. She shared her experiences with this particular client over an 18 month period.
Areej’s talk was refreshingly honest and she even said that it isn’t a successful case study (YET). Arguably, we can all learn a lot more from what went wrong than what went fantastically well, so let’s start sharing more case studies like this, please!
The site’s main issues: Round 1
From an initial audit focusing on links, technical SEO and content, these are the main issues that were identified:
- The size of the site made it difficult to crawl.
- It was being significantly out-performed by competitors.
- 72% of backlinks came from 3 referring domains.
- A lot of duplicate content.
- Thin content.
- No sitemaps.
- Incorrectly implemented canonical tags.
- Poor internal linking structure.
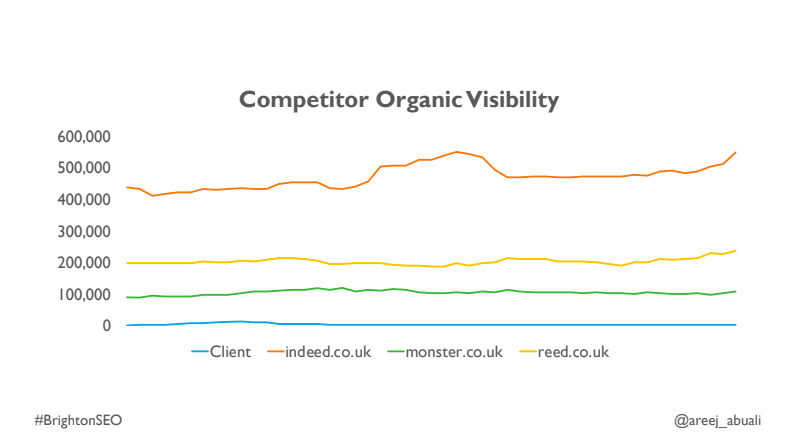
The site’s main issues: Round 2
Areej also put together some supplementary findings on top of the initial findings, also known as:

The main supplementary finding was that every single internal search could create a page that is crawlable and indexable. This was creating a potentially infinite number of indexable URLs.
This meant that Googlebot and other search engine crawlers were wasting a significant amount of crawl budget trying to access all of these pages, as there were no robots directives in place.
The fixes that were put forward
To overcome these challenges, it was important to go back to the basics and fix the fundamentals and the technical SEO aspects first, before working on creative campaigns. The main goal was to reduce the number of unnecessary pages from being crawled and indexed and to improve crawl budget.
Here’s the strategy Areej put together:
- 6 months focused on technical SEO alone.
- Implement robots directives.
- Use search volume data to identify which pages are valuable to be indexed.
- Implement a more comprehensive header and footer navigation.
- Provid a more useful breakdown of the filter system on jobs pages.
- Create sitemaps and segment them by category, e.g. job results sitemap, blog sitemap, etc.
- Auto-generate optimised H1s, meta titles and meta descriptions.
Consolidating and maintaining infinite search pages
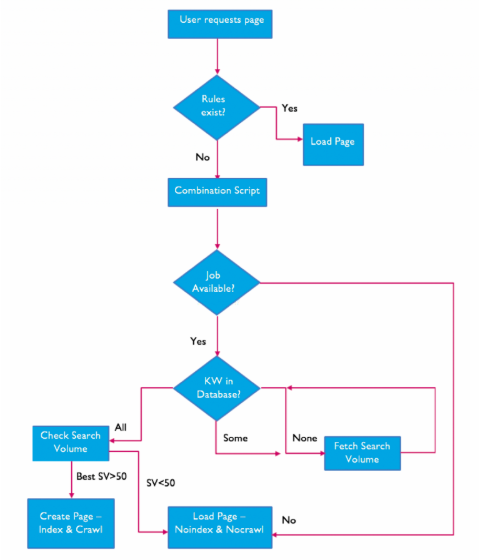
A keyword combination script was created to combine similar keyword variations to be consolidated and target one page, e.g. the same keyword strings with different word ordering. The aim of this was to reduce the number of pages being created.
If the keyword combination for the search page with the highest monthly search volume is over 50, then a new page is created and set to be crawled and indexed. If the search volume for the page is less than 50 then the page is still created for the user to view, but it is blocked from being crawled and indexed.
To get this keyword data, Areej recommends using the Keyword Tool API.
Here’s the overall framework that was set up to help maintain the search pages being created:
Why traffic still declined
Traffic still continued to decline as many of the suggested fixes weren’t implemented by the client. This caused Areej to go and do a mini audit, also known as:

The client had implemented canonical tags but was only relying on these tags to restrict search engine crawling. This is a mistake as canonical tags are a signal for search engine crawlers, not a directive.
The internal linking fixes had not been implemented meaning there were pages being indexed that weren’t in sitemaps, as well as pages in the sitemaps that weren’t being indexed. URLs with campaign parameters were being linked to internally and were, therefore, being crawled and indexed.
Canonical tags can never be used as an alternative fix for internal linking issues.
What happened next?
Areej put an end to back-and-forth email chains and:
- Set up a face-to-face meeting.
- Each unresolved issue was discussed in detail.
- Tasks were re-prioritised and estimated completion dates were added.
Some final thoughts: focus on one main recommendation that is most important, then you can move onto other smaller recommendations, rather than sending everything across at once for implementation.
Nils de Moor – Living on the Edge: Elevating Your SEO Toolkit to the CDN
Talk Summary
Nils de Moor, CTO & Co-founder of WooRank, explained the benefits of utilising a CDN to implement SEO on the edge, as well as how ‘Edge SEO’ works.
Key Takeaways
Both interest in and usage of CDNs and serverless computing continues to rise. This is because CDNs can provide significant benefits for SEOs and provides more opportunities for speeding up websites and implementing fixes.
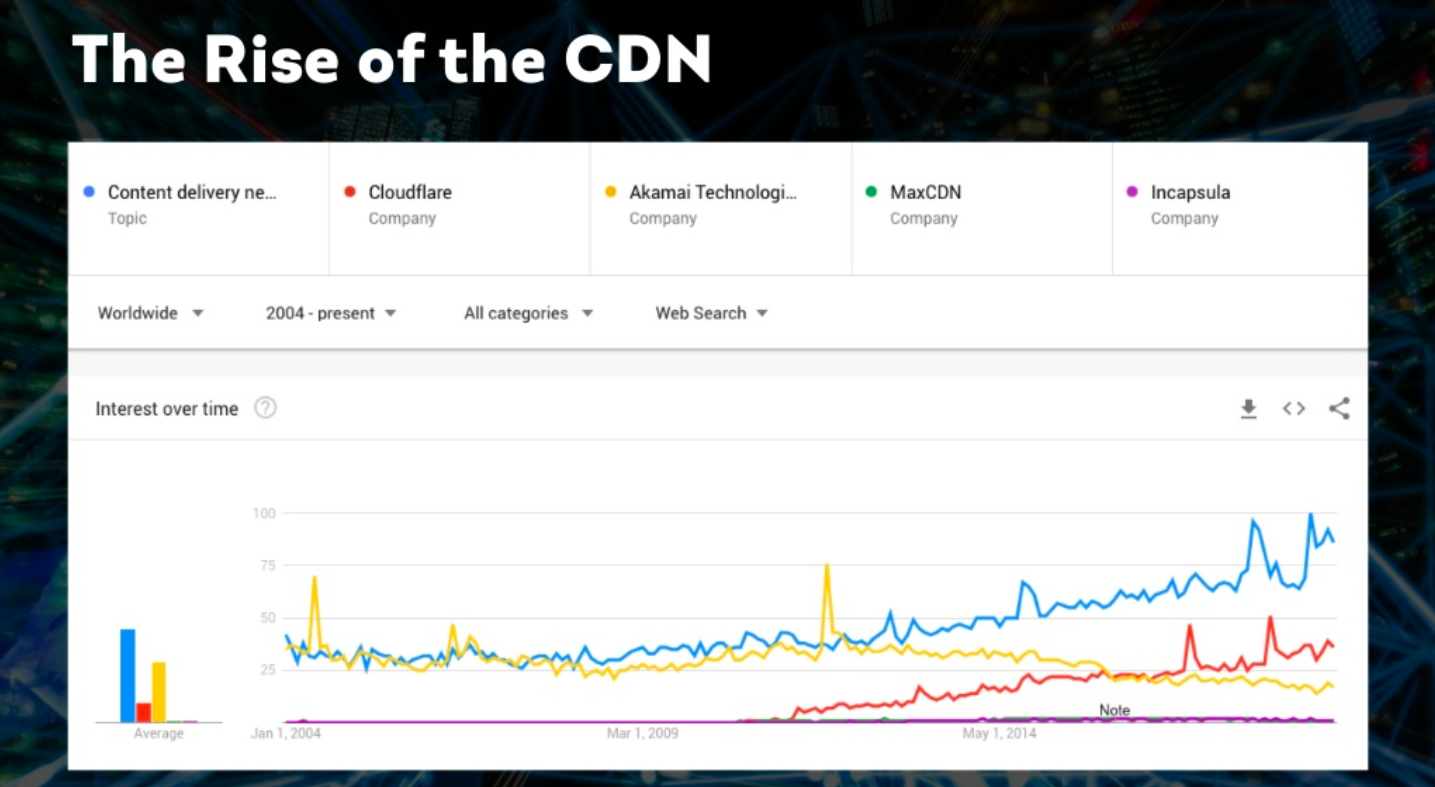
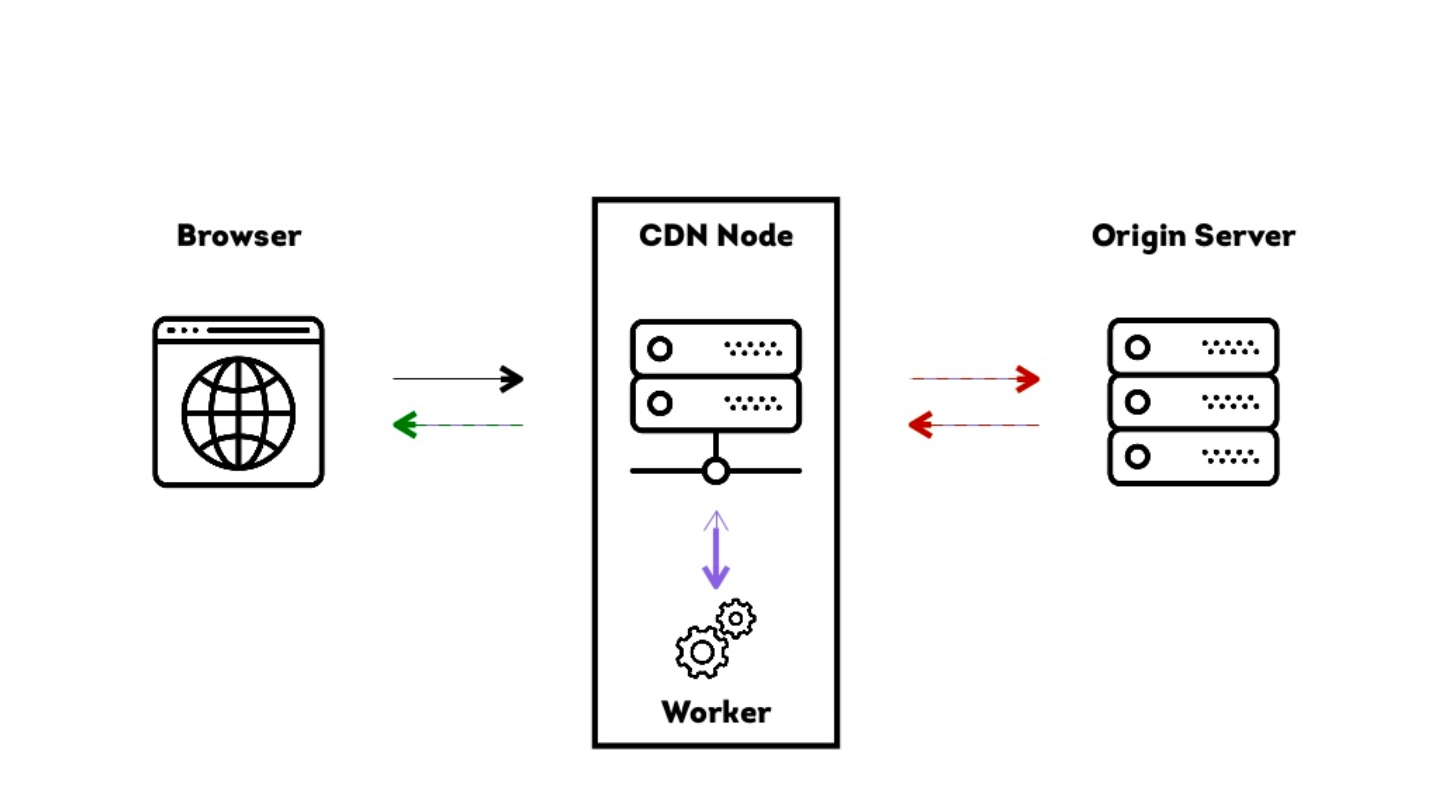
How CDNs work
A CDN works as an intermediary between a browser and the server, meaning that requests from the user can go through the CDN rather than the server. There are three main actors involved in the implementation of a CDN:
- The user’s browser.
- The CDN node.
- The origin server.
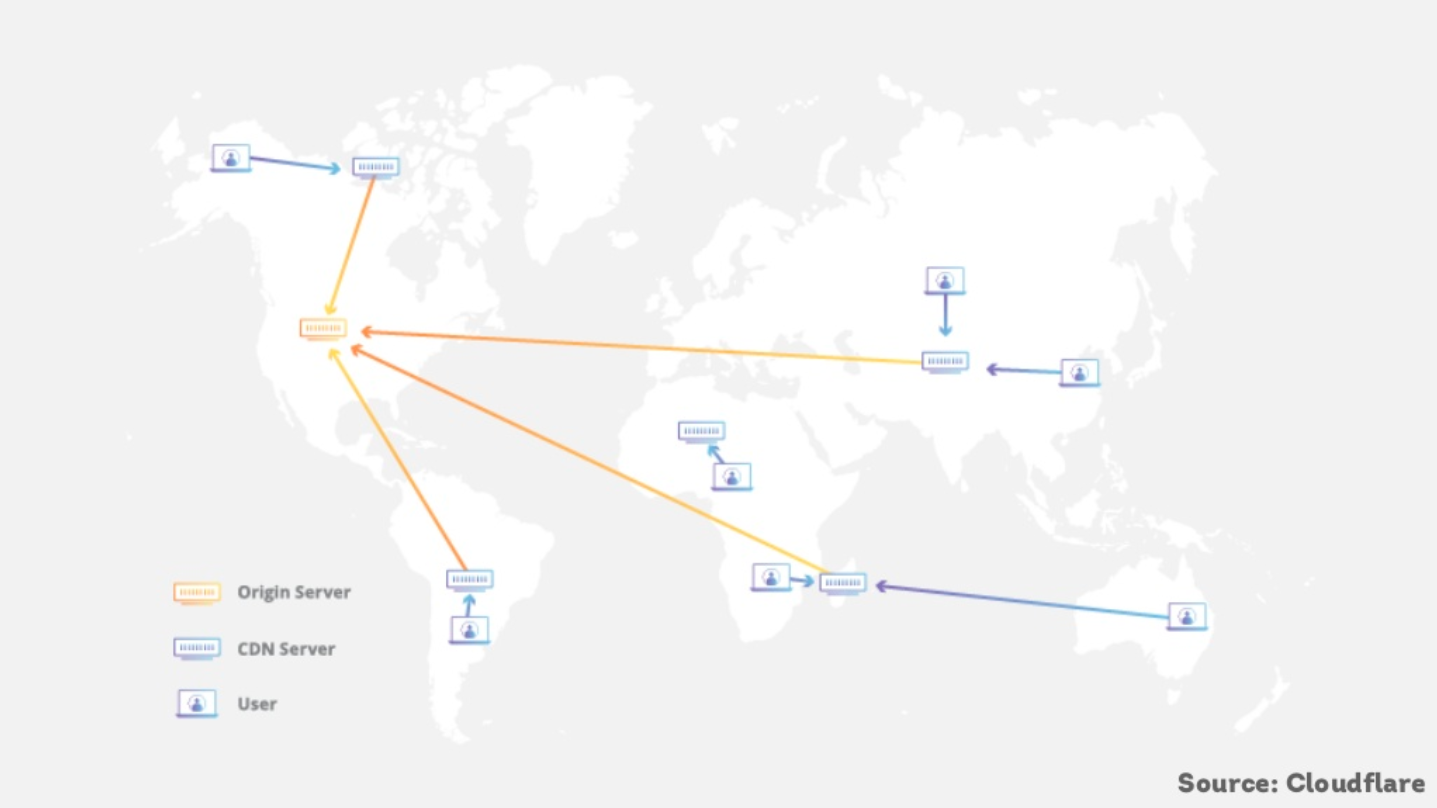
A CDN node can be used to tap into what’s being pushed between the origin server and browser and run arbitrary code to make changes. This means that you can send code to the browser that doesn’t have to exist on the origin server.
The benefits of using a CDN
Here are the main benefits of utilising a CDN:
- Speed: Content is brought closer to the user’s location, meaning requests are received faster.
- Cost: Data doesn’t travel as far and less bandwidth is used.
- Reliability: Files are de-duplicated globally, and you also don’t have to rely on data centres.
- Security: SSL certification out of the box and DDoS mitigation.
The benefits of Edge SEO
The concept of edge computing already existed, however, the term ‘Edge SEO’ has been more recently coined by Dan Taylor of SALT.agency.
Here are some of the main benefits of Edge SEO:
- Performance improvements: You don’t have to keep managing multiple servers.
- Getting around platform restrictions: Certain CMSs don’t allow you to make certain changes on the server, but Edge SEO helps you get around this.
- Improved release management: Saves you having to wait for fixes to be implemented after being recommended.
What you can implement with Edge SEO Using a CDN
These are just a few examples of what you can implement on the edge by using a CDN node:
- Send requests to block certain bots from crawling your website.
- Modify hreflang tags.
- Edit robots.txt files.
- Implement redirects.
- Add security headers.
- Implement A/B testing.
- Access server logs.
Your Edge SEO toolbox
These are the tools Nils recommends for implementing Edge SEO for your website:
- Lambda@Edge (from AWS)
- Cloudflare Workers
- Serverless
- Sloth
Things to watch out for when using CDN nodes to implement changes
Despite all of the benefits of Edge SEO and using CDN nodes to modify the code being sent to browsers, there are some downsides to be mindful of.
- Debugging becomes harder as the code on the server and in the CDN node can interfere with each other.
- Having these two sets of code also increases the risk of them breaking one another.
- There is a risk of sensitive data being passed on by the CDN node.
- Edge SEO can be seen as “doing SEO without having to talk to developers,” and this is a dangerous way of thinking.
Make sure you keep up a good line of communication with your development teams to ensure nothing gets broken in the process of implementing SEO on the edge!
If you want to learn more about this topic, make sure you read the recap of our webinar on Edge SEO with Dan Taylor.
Mike Osolinksi – CLI Automation: Using the Command Line to Automate Repetitive Tasks
Talk Summary
Mike Osolinski, Technical SEO Strategist at Edit, explained what the command line is, how it can be used to make the day-today-life of SEOs easier by automating a variety of different tasks.
Key Takeaways
What is the command line?
The command line is a command language interpreter that helps us work more efficiently. Command line examples include Terminal, Command Prompt, Bash and Cygwin.

It can be a powerful addition to your workflow as it allows you to quickly write ad-hoc scripts, gives you access to libraries of pre-built scripts and has the capability to chain different scripts together for automated solutions.
All you need to do to get started is open the command line and enter a prompt.
What you can do with the command line
These are a few examples of what you can do by using the command line:
- Merge files.
- Rename files in bulk.
- Run Lighthouse reports.
- Optimise images by running the ‘jpegoptim’ command.
- Extract information from server log files, such as entries from particular user agents like Googlebot.
Using Powershell
Powershell is a scripting language that comes with an integrated scripting environment with a command line library panel. With this, you can use ‘cmndlets’ (Powershell scripts) to perform single functions, such as importing or exporting CSV files or consuming REST APIs.
 There is so much potential for what can be done using the command line; these examples are just the tip of the iceberg. The most repetitive tasks are the perfect candidates for automation, so start thinking about what those are and how you can save yourself more time by using the command line to speed them up.
There is so much potential for what can be done using the command line; these examples are just the tip of the iceberg. The most repetitive tasks are the perfect candidates for automation, so start thinking about what those are and how you can save yourself more time by using the command line to speed them up.
Tom Pool – How to Use Chrome Puppeteer to Fake Googlebot & Monitor Your Site
Talk Summary
Tom Pool, Technical SEO Manager at Blue Array, explained what Chrome Puppeteer is and how it can be used to emulate and monitor websites and help make SEO’s lives easier.
Key Takeaways
Tom’s exploration of Chrome Puppeteer was inspired by a talk by Eric Bidelman at Google I/O 2018, entitled ‘The Power of Headless Chrome.’ By listening to this talk, Tom realised that he may be able to use the concepts raised within it to help with his every day job.
What is Headless Chrome?
Headless Chrome is essentially the Chrome browser but with no interface. It runs in the background without the traditional browser window which users are used to seeing.
What can Headless Chrome be used for?
These are just a few examples of what Headless Chrome can be used to do:
- Scrape websites.
- Generate screenshots of websites.
- Compare rendered and unrendered code for JavaScript websites.
- Crawl SPAs (Single Page Applications).
- Automate web page checks.
- Emulate user behaviour.
- Test the capacity of a website and how much it can handle.
How to use Headless Chrome
These are the elements you need to be able to run Headless Chrome:
- Chrome Puppeteer: A Node library with an API that allows you to control Headless Chrome.
- The command line: Headless Chrome needs to be run through the command line. To learn more about what the command line is and how it can be used, make sure you look at the slides from Tom’s BrightonSEO talk from April 2018.
- NPM: A JavaScript language package manager.
- Node.js: A JavaScript run-time environment.
Tip: use Homebrew for help with installing some of this software on Mac.
Using Headless Chrome & Puppeteer to fake Googlebot
Once everything is installed and set up, you can use the command line to add in Googlebot’s user agent (note that this isn’t just ‘Googlebot’, you’ll find a list of its full user agent strings here) and its viewport size, which is 1024×1024.


These commands can be used to get an idea of what Googlebot will have seen when accessing your pages and whether or not server-side rendered content is available as expected.
It’s important to note that Puppeteer is not backwards compatible and does not show how the page will have actually appeared for Google which uses Chrome 41 for rendering, which is an older version of Chrome launched back in 2015.
Using Headless Chrome & Puppeteer for website monitoring
You can also write a script to detect changes on your website. The way this works is that the current code of a page will be pulled through to a txt file, then when the page is run again that updated code will be pulled into a different txt file. Then the two txt files can be compared.
Rather than having to manually run pages daily, you can run a cron job to have this process happen automatically.
These are some of the different elements of your site that you can monitor using Headless Chrome and Puppeteer:
- Page title changes.
- Meta description changes.
- Word count increases/decreases.
- Robots directives.
- Canonical tags.
Make sure you take a look at Tom’s code examples to start using Headless Chrome and Puppeteer for your website.
These use cases still only barely scratch the surface of what’s possible with this technology. We look forward to seeing what SEOs can further do with it in the future!
Matthew Brown – The Circle of Trust: SEO Data
Talk Summary
Matthew Brown, Managing Director at MJBLabs, talked about the difficulties of getting accurate, trustworthy data as an SEO, and how to use this data to better optimise for the search engines visiting our websites.
Key Takeaways
It’s challenging to be an SEO because the data we have available is often noisy and we often misuse it. We’re also in the dark with regards to the inner workings of search engines like Google, as its signals and algorithms become more and more sophisticated.
Using log file data
Server logs never lie. They are a window into what search engines are consuming on your website, and you are what Googlebot eats. With log files you can see exactly which pages are being accessed by search engines and where crawl budget is being wasted on unnecessary pages.
Keep Googlebot in check and restrict crawling so that only the most important pages are being processed.
To get enough valuable data, make sure you’re looking at a broad view of server logs in terms of numbers of requests and across a significant date range.
Using Google Search Console data
The XML sitemap data in Google Search Console is one of the most useful features of the tool. Use it to monitor your sitemaps on an ongoing basis and keep track of whether or not your most important pages are being served to search engines.
Googlebot habits to find & break
These are some examples of Googlebot activity to watch out for and correct if you see it happening for your site:
- Encountering across 5xx errors and 404 errors.
- Accessing JavaScript files that don’t need to be rendered such as tracking scripts.
- Crawling links with UTM tracking parameters.
Optimisation tips for improved search engine crawling
Here are some tips for improving the quality of pages that are being sent to search engines for crawling, as well as increasing the frequency of crawling for these pages.
- Overlay log file data, traffic data and backlink data for your pages and make sure that pages with backlinks and traffic are being crawled most frequently.
- Noindex pages you want to crawled, wait until they’re definitely not being crawled and indexed anymore, and then block them in robots.txt.
- Internal search pages often have link value so block them with care and selectively block the ones that don’t bring in any incoming links or traffic.
- Make sure Googlebot is crawling the smallest number of pages per keyword, segment or market and consolidate pages for crawling where possible.
- Segment your pages into multiple XML sitemaps so you can get more granular data on indexing rates.
George Karapalidis – Why Data Science Analysis is Better Than YOUR Analysis
Talk Summary
George Karapalidis, Data Scientist at Vertical Leap, explained how SEOs have a lot to gain from learning more about the way data scientists think and work.
Key Takeaways
What SEOs can learn from data scientists
SEO and SEM is evolving, so we need to embrace the mindset of a data scientist by finding the right data and getting the most out of it. The more you dig into the data, the more effective the solution you’ll find.
Data can be used to figure out what has happened in the past, why it happened, how you can make things happen in the future, as well as where the company is heading. However, you always need to question every objective you’re given as much as possible to gather as much information as possible from the start, as this is what a data scientist would do.
The most important things to explore in your data
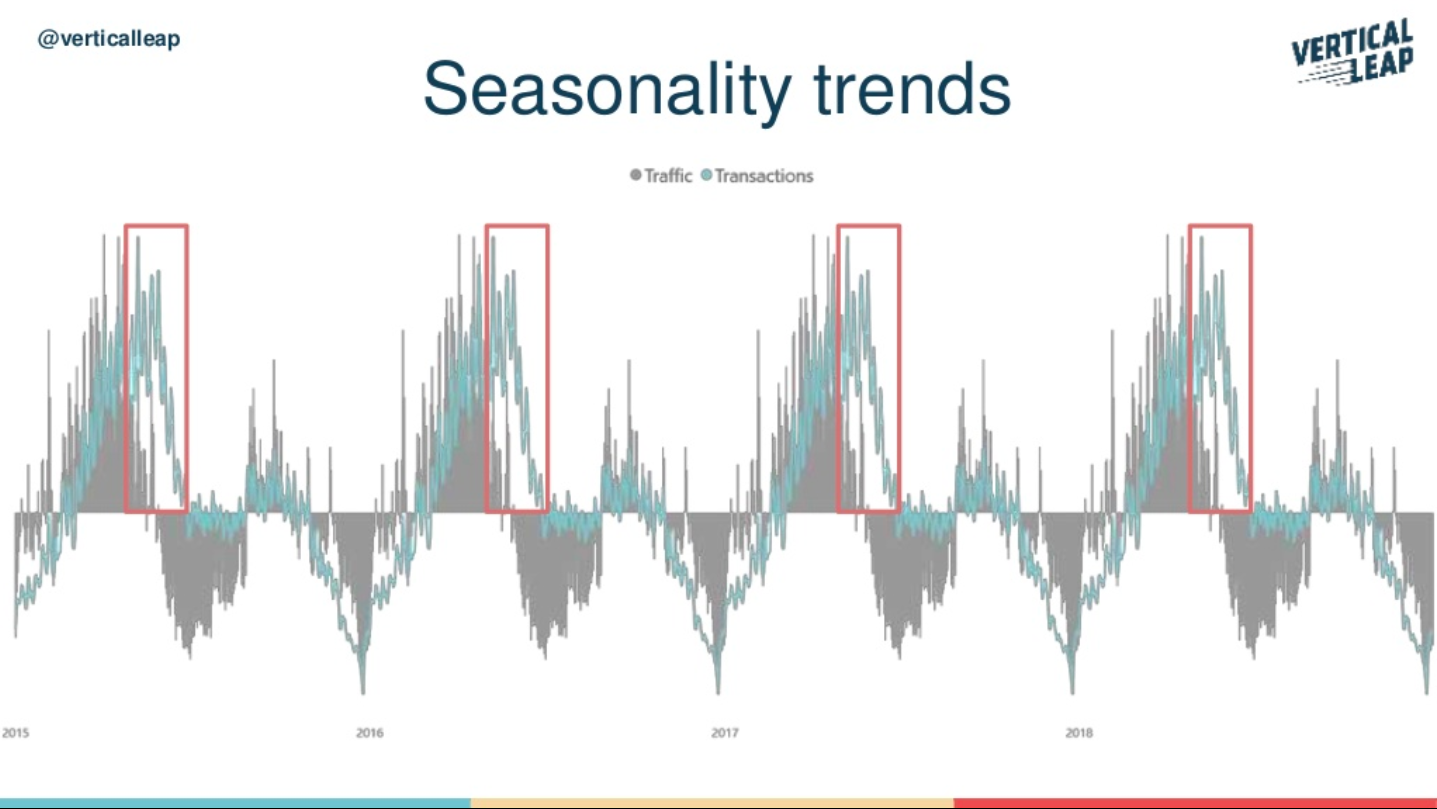
These are the aspects you should focus on most within your exploratory data analysis:
- Where is your traffic coming from? It may not be viable to include traffic from all regions that don’t produce quality visits that convert.
- What are the correlations between the different datasets? Examine whether or not traffic increases, but conversion rates stay the same, for example. If you aren’t seeing correlations, make sure your data is clean.
- Where are there gaps in the data? Split out your data within a time series and include positives and negatives, as this will show gaps and opportunities.
George highly recommends using Power BI to help you with your data manipulation.
Tips for making the most out of your data
- Exponential Smoothing: Applies a higher weight to more recent observations. You can do this in Excel once you import data and search ‘forecast’.
- ARIMA (Autoregressive Integrated Moving Average): This works well for non-stationary datasets. You can do this in Azure Maching Learning and then import the data into Excel.
- MAPE (Mean Absolute Percentage Error): When forecasting, make sure you find the data with the lowest MAPE.
- Use Prophet: This is a forecasting tool that combines time series analysis and predictive analysis.
Make sure you’re only using valuable data, identify important events that influence change in your data, and be flexible with your data models.
The BrightonSEO April 2019 Event Recap Continues
There were so many great talks during BrightonSEO that we couldn’t cover them all in one recap post. You can find part 2 of our BrightonSEO April 2019 event recap here.
During the keynote session this time, we were treated to a live Q&A session with Google’s John Mueller where Hannah Smith from Verve Search asked him the questions we all wanted answers to, such as: What caused Google’s deindexing issue? And why weren’t we told about rel=next and rel=prev being removed sooner? We watched intently and took notes, so make sure you read our recap of the Q&A with John which will be published later this week.
Featured image credit: Marie Turner



