

Chapter 1: What is JavaScript?
JavaScript code by itself doesn’t always mean that much. It needs to be processed and rendered before output code can be displayed and the requested page can be shown to the client, such as the user’s browser or the search engine crawler. Can you tell what this example website is about by looking at this code alone?

No? Well, neither can a search engine or browser unless JavaScript is executed. This is why rendering is needed to run scripts like the one above and populate a page’s HTML with content so it can be read, understood and used for indexing.
As opposed to content in the HTML, JavaScript-powered content takes a little more preparation before it is meaningful to the client requesting it, and this happens through the process of rendering.

Source: Bartosz Góralewicz, SMX
JavaScript-powered content needs to be rendered before it can output meaningful code and be displayed for the client.
These are the different steps involved in the JavaScript rendering process:

Source: Google Developers
1. JavaScript: Typically JavaScript is used to handle work that will result in visual changes.
2. Style calculations: This is the process of figuring out which CSS rules apply to which elements. They are applied and the final styles for each element are calculated.
3. Layout: Once the browser knows which rules apply to an element it can begin to calculate how much space it takes up and where it is on screen.
4. Paint: Painting is the process of filling in pixels. It involves drawing out text, colors, images, borders, and shadows, essentially every visual part of the elements.
5. Compositing: Since the parts of the page were drawn into potentially multiple layers they need to be drawn to the screen in the correct order so that the page renders correctly.
How search engines render JavaScript
It’s important to bear in mind that most search engines can’t render at all, and those that do have their own rendering limitations. This means that if your website relies on JavaScript to power its content and navigation, search engines could end up seeing a blank screen with nothing of value to crawl or index.
Content and links served via JavaScript run the risk of not being seen by search engines, as they either have rendering limitations, or can’t render at all.
One of the biggest struggles which search engines (and SEOs) have with JavaScript is that it often breaks our working model of what a “page” is. We’re used to a world where content lives in HTML code, on a webpage, which is represented by a URL; and for the most part, pages are generally consistent in form and behaviour. This model sits at the very heart of how Google crawls, processes, and evaluates content.
With JavaScript, that paradigm shatters. We lose the connection between URLs, pages and content, as the browser fluidly changes based on user interaction. We move into a world of “states” and “views”, which don’t neatly fit our model. This makes it hard for search engines to understand what a “page” is, nevermind the challenges of accessing, evaluating and associating the value of content with a URL.
Until search engines have a way to handle this new world, it’s imperative that SEO practitioners understand how JavaScript websites work, and can wrangle them into a format which Google can consume and understand. In most cases, that’s as simple (and as complex) as ensuring that the website behaves like a “normal” site when JavaScript isn’t enabled.
Make no mistake, JavaScript websites are the future. Consumers expect and demand the kinds of rich experiences which only apps can deliver. But if we don’t step in, steer best practice and level-up the development community, the web as we know it will break.
We’ve put together the latest updates on how the main search engines are currently equipped for rendering, as well as some key considerations for each one.
Google is one of the few search engines that currently renders JavaScript, and provides a lot of documentation and resources on JavaScript best practice for search. This means we’re able to build a pretty clear picture of what we need to do to get our websites indexed in Google’s SERPs (Search Engine Results Pages).
How Google renders JavaScript
When Google renders, it generates markup from templates and data from a database or an API. This markup is then sent to the client to update the DOM and paint pixels to the screen. The key step in this process is to get the fully generated markup though, because this is what’s readable for Googlebot.
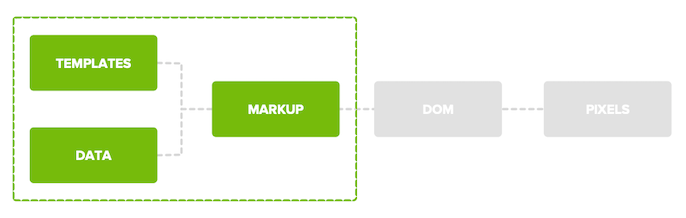
Source: Martin Splitt, AngularUP Conference
To carry out this process, Googlebot uses a headless browser for its web rendering service (WRS). A headless browser is essentially a browser without the visual elements, which outputs rendered code rather than a visually rendered page. Google’s WRS is based on Chrome 41 which was launched in 2015, and is limited by the features of the Chrome version it is using.
The most recent version at the time of writing is Chrome 72, so there is a gap between the latest browser functionalities and how Googlebot is able to render content. To put this in perspective, since Chrome 41 was released, 892 new Chrome features have been added.
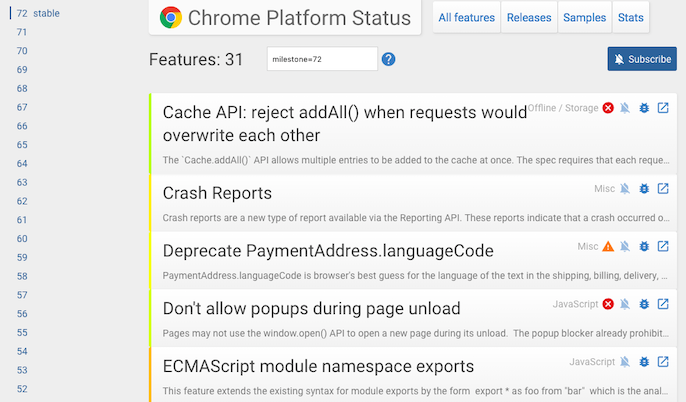
Source: Chrome Platform Status
The last time I checked my calendar, it was 2019. I wish search engines were perfect at rendering JavaScript, but unfortunately, that’s not the case. The key is to know search engines’ limitations and how to deal with them.
Google’s Web Rendering Service uses a 4-year old browser for rendering. You can’t change that but you should ensure that Google can access your content by using proper tools, like the URL Inspection Tool, Chrome 41, Mobile-friendly Test and Rich Results Test. In addition, make sure Google has indexed your content by using the “site” command.
If something is wrong, you can analyze what errors Google gets while rendering. Maybe you forgot about polyfills or transpiling to ES6? Sit with your developer and start talking about the issue. If you can’t find anything that helps, you may consider moving to hybrid rendering or dynamic rendering.

How Google’s rendering process impacts search
Google has a two-wave indexing process, which means that there are no guarantees on when pages will actually be rendered. The crawling and indexing process is usually very quick for sites that don’t rely on JavaScript, however, Google can’t crawl, render and index all in one go due to the scale of the internet and the processing power that would be required to do so.
The internet is gigantic, that’s the problem. We see over 160 trillion documents on the web daily, so Googlebot is very busy. Computing resources, even in the cloud age, are pretty tricky to come by. This process takes a lot of time, especially if your pages are really large, we have to render a lot of images, or we have to process a lot of megabytes of JavaScript.

After a page has initially been crawled, Googlebot will find all pages with JavaScript on them that need to be rendered, and will then add them to a queue to be rendered at a later date when enough resources become available.
We pretty much try to render them all. With regards to “non-critical” it’s more a matter of which of the embedded scripts really need to be run. Eg, Analytics doesn’t change anything on the page, so why use it for rendering?
— ???? John ???? (@JohnMu) February 27, 2019
A page will only be added to the index in the second wave after it has been rendered.
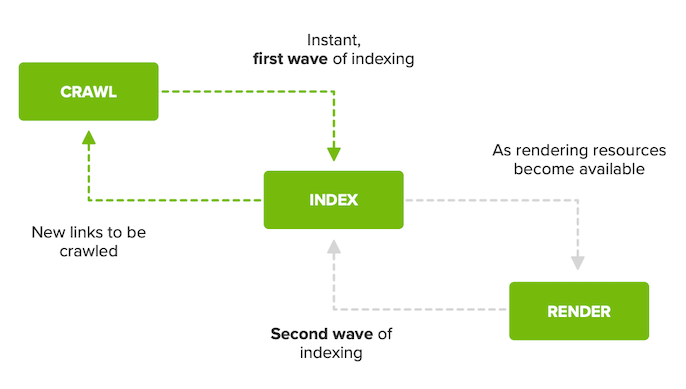
Source: Google I/O 2018
When resources do become available, there isn’t a specific way of prioritising the pages that will be rendered first. Google’s John Mueller explained that any prioritisation is done in the same way as for regular crawling and indexing.
Google doesn’t have a separate way of prioritising pages for rendering.
-John Mueller, Google Webmaster Hangout
What is the gap between the first and second wave of indexing then? According to Google’s Tom Greenaway and Martin Splitt during Chrome Dev Summit 2018, it could take “minutes, an hour, a day or up to a week” for Google to render content after a page has been crawled.
If your website gets stuck between these two waves of indexing, any new content you add or any changes you make to your website won’t be seen or indexed for an undetermined amount of time. This will have the biggest impact on sites that rely on fresh search results, such as ecommerce or news sites.
Ecommerce websites should avoid serving product page content via JavaScript.
-John Mueller, Google Webmaster Hangout
News sites should avoid content that requires JavaScript to load.
-John Mueller, Google Webmaster Hangout
Sites that rely on content freshness should avoid serving content via JavaScript, as Google’s indexing of rendered pages is delayed.
The team at Google are aware that this isn’t an ideal situation for website owners and are working on updating their rendering services. At Chrome Dev Summit 2018, Martin Splitt announced that Google will be updating its WRS so that it stays up to date with Chrome’s release schedule, meaning that the WRS will always use the latest version of Chrome.
Bearing all of this in mind, you can start to see that Google needs some additional help to render your modern JavaScript websites and applications. We’ll go over some of the things you can do later on in this guide.
Bing
Bing’s crawler allegedly does render JavaScript, but is limited in being able to process the latest browser features and render at scale, which sounds like a similar situation to Google’s.
In general, Bing does not have crawling and indexing issues with web sites using JavaScript, but occasionally Bingbot encounters websites heavily relying on JavaScript to render their content, especially as in the past few years. Some of these sites require far more than one HTTP request per web page to render the whole page, meaning that it is difficult for Bingbot, like other search engines, to process at scale on every page of every large website.
Therefore, in order to increase the predictability of crawling and indexing of websites relying heavily on JavaScript by Bing, we recommend dynamic rendering as a great alternative. Dynamic rendering is about detecting search engines bot by parsing the HTTP request user agent, prerendering the content on the server-side and outputting static HTML, helping to minimize the number of HTTP requests needed per web page and ensure we get the best and most complete version of your web pages every time Bingbot visits your site.
When it comes to rendering content specifically for search engine crawlers, we inevitably get asked whether this is considered cloaking… and there is nothing scarier for the SEO community than getting penalized for cloaking. The good news is that as long as you make a good faith effort to return the same content to all visitors, with the only difference being that the content is rendered on the server for bots and on the client for real users, this is acceptable and not considered cloaking.
Even though Bing can render in some capacity, it isn’t able to extract and follow URLs that are contained within JavaScript.
Don’t bury links to content inside JavaScript.
Yahoo
Yahoo cannot currently render. It is recommended to make sure that content isn’t ‘hidden’ behind JavaScript, as the search engine won’t be able to render JavaScript to find any content within it. Only content that is served within the HTML will be picked up.
Unhide content that’s behind JavaScript. Content that’s available only through JavaScript should be presented to non-JavaScript user agents and crawlers with noscript HTML elements.
Yandex
Yandex’s documentation explains that the search engine doesn’t render JavaScript and can’t index any content that is generated by it. If you want your site to appear in Yandex, make sure your key content is returned in the HTML upon the initial request for the page.
Make sure that the pages return the full content to the robot. If they use JavaScript code, the robot will not be able to index the content generated by the script. The content you want to include in the search should be available in the HTML code immediately after requesting the page, without using JavaScript code. To do this, use HTML copies.
The other search engines
DuckDuckGo, Baidu, AOL and Ask are much less open about their rendering capabilities. The only way to find this out currently is to run tests ourselves, but luckily Bartosz Góralewicz has done some of this work already.
In 2017, Bartosz ran some experiments using a test site that used different JavaScript frameworks to serve content and analysed which search engines were able to render and index the content. We can never make definitive conclusions based on the indexing of test sites alone, but the results showed that only Google and, surprisingly, Ask were able to index rendered content.
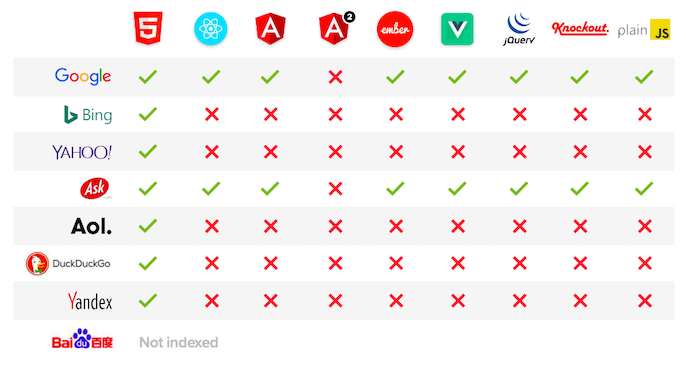
Source: Moz
Bing, Yahoo, AOL, DuckDuckGo, and Yandex are completely JavaScript-blind and won’t see your content if it isn’t in the HTML.

Take a look at the full article covering the experiment and results to learn more about Bartosz’s conclusions.
How social media platforms render JavaScript
It’s important to know that social media and sharing platforms generally can’t render JavaScript.
Facebook and Twitter’s’ crawlers can’t render JavaScript.
-Martin Splitt, Google Webmaster Hangout
If you rely on JavaScript to serve content that would feed into Open Graph tags, Twitter Cards or even meta descriptions that would show when you share an article on Slack, for example, this content wouldn’t be able to be shown.
How browsers render JavaScript
When a user tries to access a page that uses JavaScript, their browser will firstly receive HTML, CSS and JavaScript in packets of data. The code from these packets is then parsed and mapped out to create the DOM, which defines the structure of the page. This structure is combined with instructions from the CSS about the styling of the different elements on the page, which creates the render tree. This is what the browser uses to layout the page and start painting pixels to the screen.
JavaScript causes an issue for browser rendering because it has the potential to modify the page. This means that rendering has to be paused each time a new script is found and the structuring and styling of the page is put on hold to keep up with any changes that JavaScript might make to the page.
JavaScript causes the browser to stop and start the process of rendering and loading the page, which can have a big impact on site speed.
To learn more about how browsers render JavaScript, this guide explains the process in more detail.
The most commonly used browsers are:
- Chrome
- Safari
- Firefox
- Samsung Internet
- Opera
- Edge

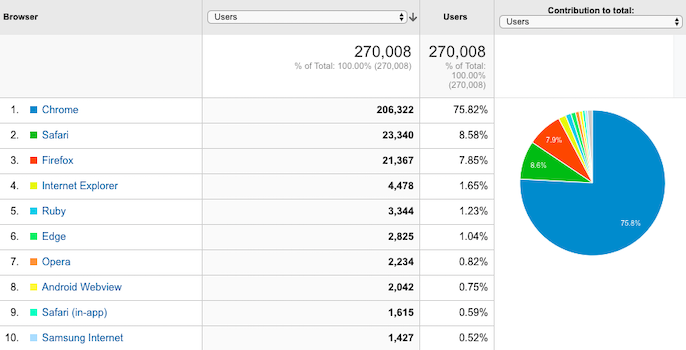
Each browser has its own rendering environment and can have its own unique challenges. This is why it’s crucial to test how your website loads across different browsers. Find out the main browsers that are used by people visiting your website, and test how those render as a priority. You can find this information in the Audience section of Google Analytics under ‘Technology’.
Chapter 3: The Different JavaScript Rendering Methods