ウェブサイトの頻繁かつターゲットを絞ったクロールを実行することは、ウェブサイトの技術的な健全性を改善し、オーガニック検索順位を改善する重要な役割です。このガイドでは、Lumarを使用してWebサイトを効率的かつ効果的にクロールする方法を学ぶことできます。Webサイトをクロールするための6つの手順は次の通りです。
ステップ1:URLソースの構成
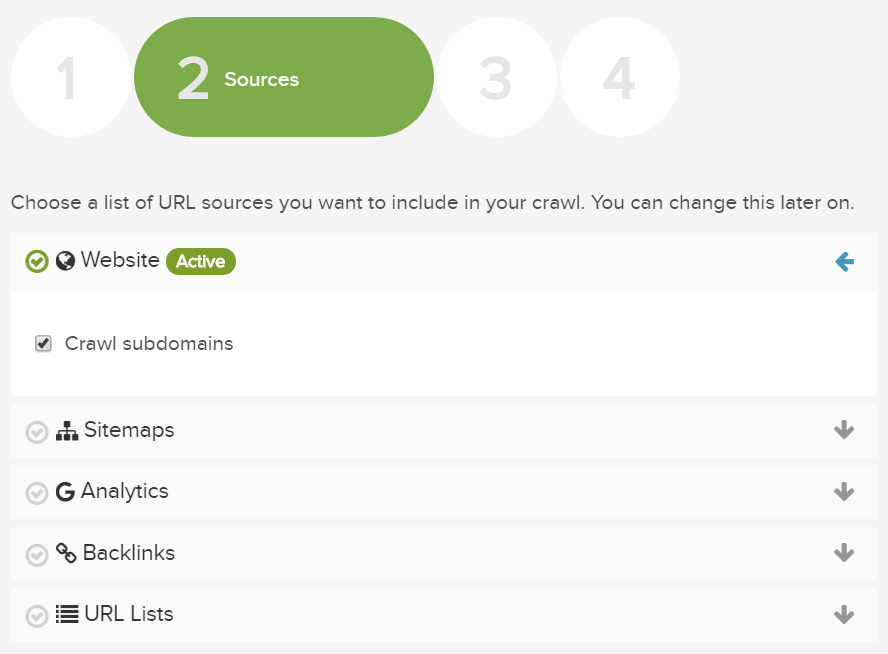
Lumarプロジェクトに含めることができるURLソースには6つのタイプがあります。各ソースを戦略的に含むことで効率的かつ包括的なクロールを行うことができます。
- Webクロール:リンクをより深いレベルに移動して、サイトのみをクロールします。
- サイトマップ:サイトマップのセット、およびそれらのサイトマップ内のURLをクロールします。これらのページのリンクは追跡もクロールもされません。
- 分析:分析ソースデータをアップロードし、URLをクロールして、リンクされていない可能性のあるサイト上の追加のランディングページを見つけます。分析データはさまざまなレポートでご利用頂けます。
- バックリンク:バックリンクのソースデータをアップロードし、URLをクロールして、サイト上のバックリンクを持つ追加のURLを見つけます。バックリンクデータはさまざまなレポートでご利用頂けます。
- URLリスト:URLの固定リストをクロールします。これらのページのリンクは追跡もクロールもされません。
- ログファイル:SplunkやLogz.ioのログファイルアナライザーツールからログファイルの概要データをアップロードする
理想としては、Webサイトは完全にクロールする必要があります(サイト上の全てのリンクされたURLを含む)。ただし、非常に大きなWebサイト、または多くのアーキテクチャ上の問題があるサイトは、すぐに完全にクロールできない場合があります。サイトの特定のセクションへのクロールを制限するか、特定のURLパターンを制限する必要のある場合があります(これを行う方法については後述します)。
ステップ2:ドメイン構造を理解する
クロールを開始する前に、サイトのドメイン構造をよりよくご理解頂くことをお勧めします:
ドメインを追加する際、そのドメインのwwwあり・なし設定や、http/https設定を確認してください。
サイトがサブドメインを使用しているかどうかを特定します。
サブドメインが不明な場合は、Lumarの”サブドメインのクロール”オプションをチェックすると、リンクされている場合は自動的に検出されます。
ステップ3:テストクロールを実行する
小さな「Webクロール」から始めて、サイトがクロールできないことを示す兆候を探します。
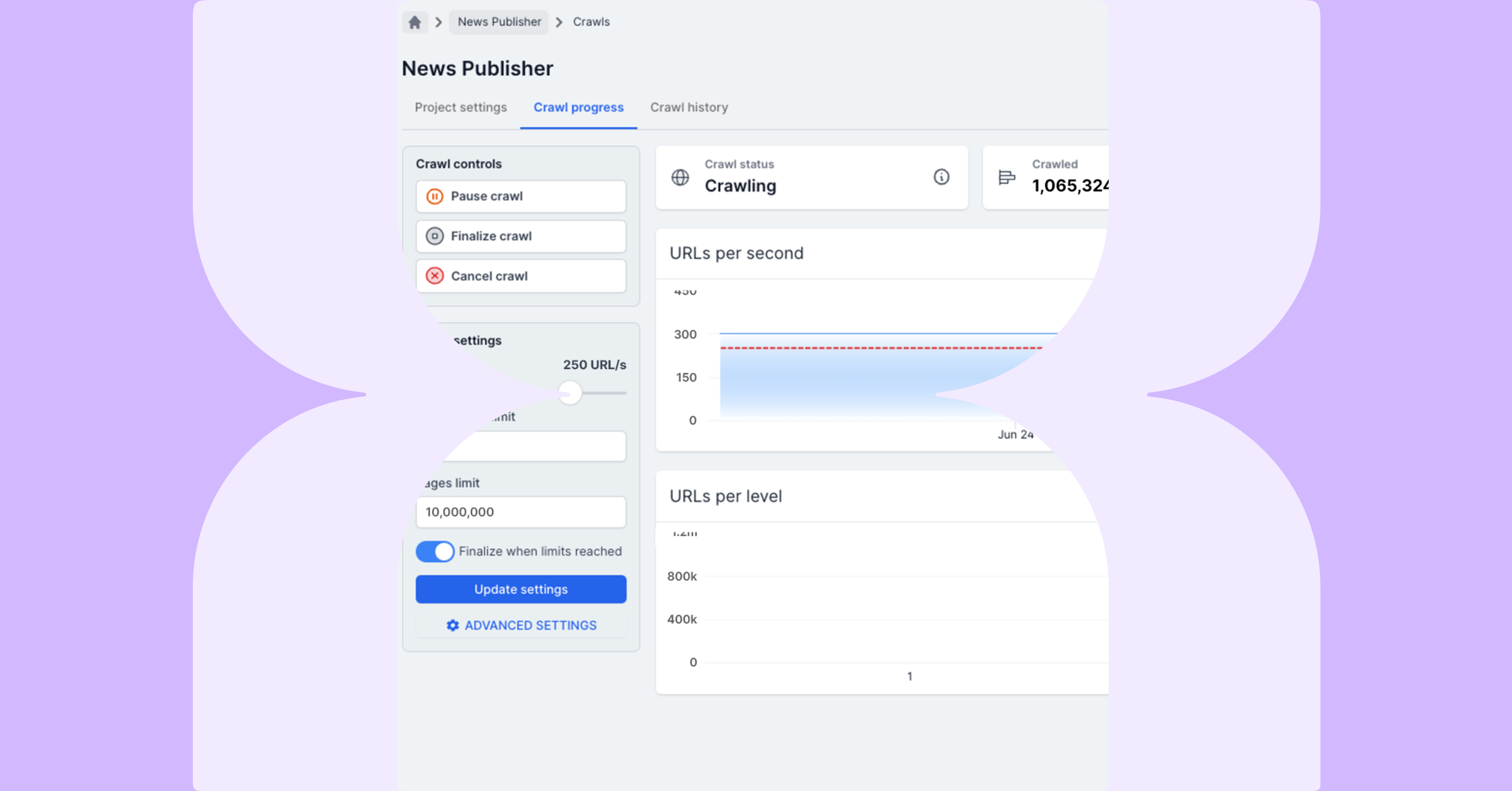
クロールを開始する前に、クロール制限を低い値に設定したことを確認してください。これにより、短時間で結果を確認することができるため、最初の確認を効率化できます。
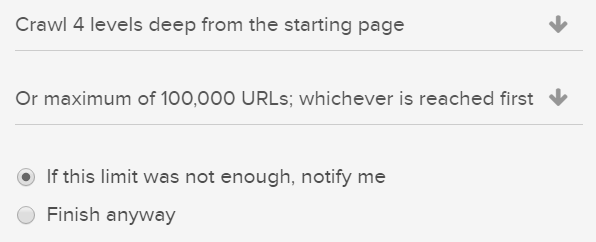
注目すべき問題は次の通りです:
- 正しいサブドメインではない401アクセス拒否URLが返されるなど、エラーコードを返す多数のURL- プロジェクト設定でベースドメインが正しいことを確認します。
- 見つかったURLの数が非常に少ない。
- 多数の失敗したURL (ステータスコード502, 504など)。
- 正規化された多数のURL。
- 多数の重複ページ。
- 各レベルで見つかったページ数の大幅な増加。
時間を節約し、明らかな問題をすぐに確認するために、クロール中にURLをダウンロードすることができます:
ステップ4:クロール制限を追加する
次に、除外できるものをすべて特定して、クロールのサイズを小さくします。制限を追加することで、重要ではないURLをクロールするための時間(またはクレジット)を削減します。詳細設定タブでは、次のすべての制限を追加できます。
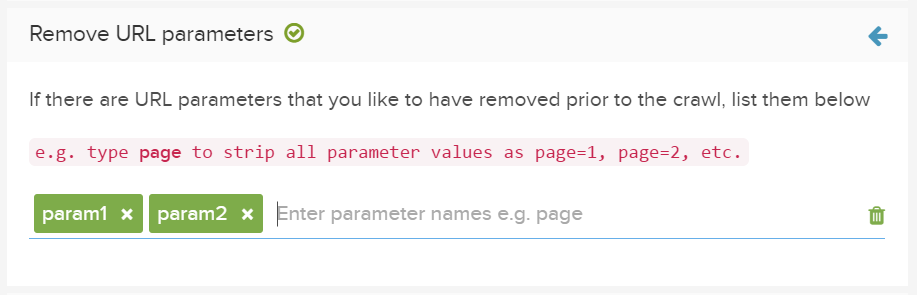
パラメータを削除
Google サーチコンソールなどのURLパラメータツールを使用して、検索エンジンのクロールからパラメータを除外した場合は、詳細設定下の「パラメータを削除」にこれらを入力してください。
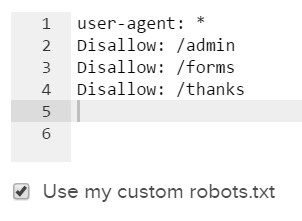
カスタムRobots.txt設定を追加
Lumarのロボットの上書き機能を使用することで、任意のrobots.txtファイルを使用して除外できる追加のURLを識別できます。これにより、新しいファイルをライブ環境に反映する影響をテストできます。
クロールを開始するときに、詳細設定でロボットファイルの代替バージョンをアップロードし、ロボットオーバーライドを使用を選択します:
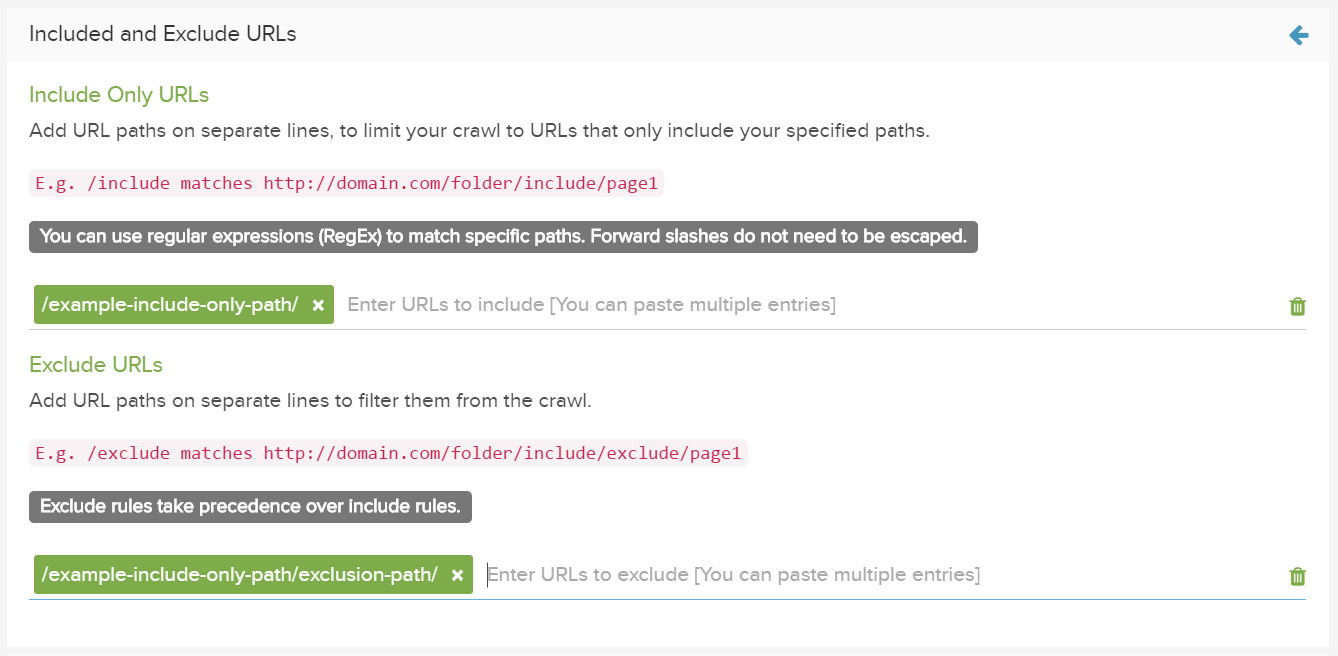
URLおよびURLパスのフィルター
詳細設定の下の、含める/除外する”URLフィールドを使用して、関心のある特定領域へのクロールを制限します。
ページのグループにクロール制限を追加する
詳細設定の下のページグループ化機能を使用し、URLパターンに基づいてページのグループに対しクロールされるURLの数を制限します。
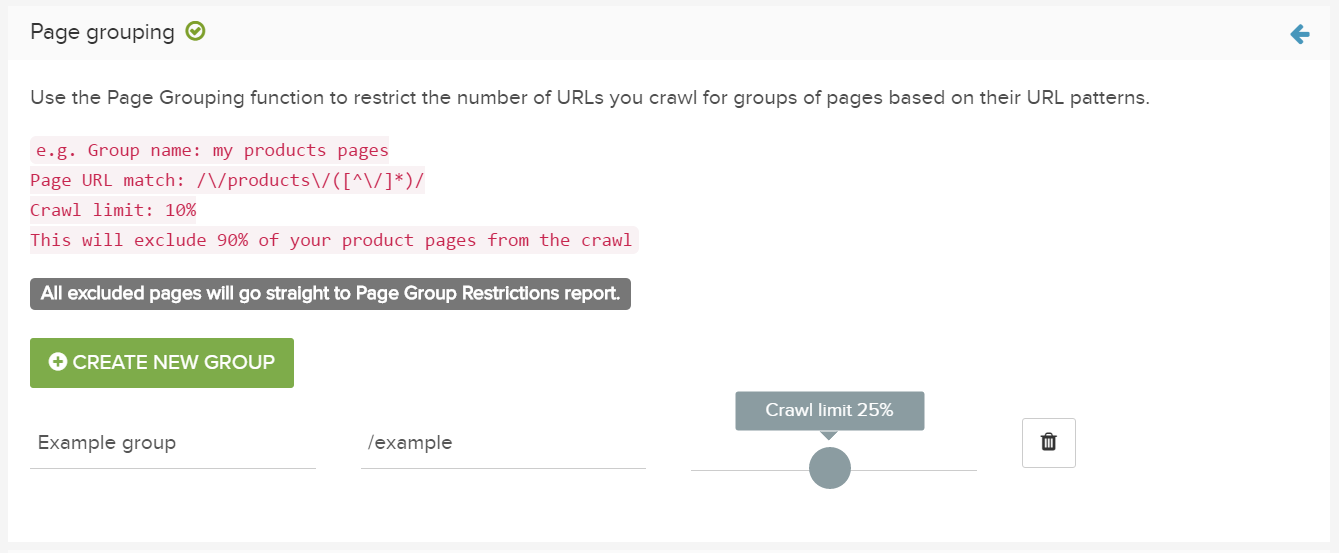
こちらで、名前を追加します。
ページURLの一致列で、正規表現を追加できます。
クロール制限列にクロールするURLの最大数を追加します。
指定されたパスに一致するURLがカウントされます。制限に達すると、さらに一致するすべてのURLがページグループの制限レポートに入り、クロールされなくなります。
ステップ5:変更内容をテストする
全体のクロールを実行する前に、テスト用のWebクロールを行い、設定が正しいかどうか確認してください。
ステップ6:クロールを実行する
より詳細なクロールを実行する前に、クロールの上限を増やしたかどうかご確認ください。
リンクされたURLをXMLサイトマップとGoogleアナリティクス、及びその他のデータで補完するために、できるだけ多くのURLソースでクロールを実行することが役立ちます。
基本ドメイン設定内でwwwのサブドメインを指定した場合、ブログやデフォルトなどのサブドメインはクロールされません。
サブドメインを含めるには、プロジェクト設定ブでクロールサブドメインを選択します。
クロールのスケジューリングを設定し、進行状況を追跡します。
便利なヒント
特定の要件の設定
テスト/サンドボックスサイトがある場合は、詳細設定でテストサイトのドメインと認証の詳細を追加して、比較クロールを実行できます。
テスト機能とライブ機能の詳細については、[テストWebサイトとライブWebサイトの比較に関するガイド]を参照してください。
エスケープフラグメントを利用してAjaxが使われているサイトをクロールするには、URL書き換え機能を使って全てのリンクされたURLをエスケープフラグメント形式に変換してください。
テスト機能の詳細については、[開発の変更点をライブで公開する前にテストする]をご覧ください。
クロール速度の変更
クロールの実行中にクローラーによって引き起こされるパフォーマンスの問題に注意してください。
接続エラーまたは複数の502や503のエラーが表示される場合、詳細設定にてクロールのスピードを下げることで解決できるかもしれません。

堅牢なホスティングソリューションがある場合は、サイトをより高速でクロールできる場合があります。
クロールレートは、サイトの負荷が減少する時間(たとえば午前4時)に増やすことができます。
詳細設定>クロール速度> 速度制限の追加 に進みます。
アウトバウンドリンクの分析
大量の外部リンクを持つサイトでは、ユーザーがリンク切れに誘導されないようにしたい場合があります。
これを確認するには、プロジェクト設定の下の外部リンクをクロールを選択し、レポート内の外部リンクの横にHTTPステータスコードを追加します。
アウトバウンドリンク監査の詳細を読んで、外部リンクの分析とクリーンアップについて学習します。
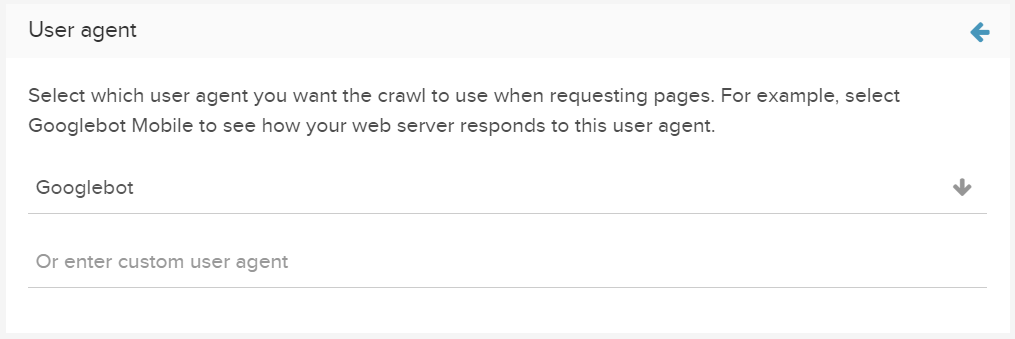
ユーザーエージェントの変更
詳細設定でユーザーエージェントを変更して、さまざまなクローラーの目(Facebook / Bingbotなど)でサイトを表示します。
カスタムユーザーエージェントを追加して、Webサイトの応答方法を決定します。
クロール後
クロール後にプロジェクト設定をリセットします。これにより、実際の設定を適用したままクロールを続行できます。
実験とクロールを重ねるほど、エキスパートクローラーに近づくことができます。
Lumarと一緒に旅を始めましょう
Lumarでのクロールにご興味がございましたら、お問い合わせください。