サイト全体をクロールする代わりに、Webサイトの特定のセクションを確認または分析することをお勧めします。
これは、新しいWebサイトチャネルを追加した後、スクリプトベースのURLとサブドメインを除外したり、Webサイトの特定のセクションでURLクレジットを使用したりするのに役立ちます。
また、特定の国のみを分析したい国際的なウェブサイトにも便利にご利用頂けます。
クロール設定のステップ4で、詳細設定にある包含ルールと除外ルールを組み合わせて使用して、クロールを任意のページセットに制限できます。
URLのみを含める(正の制限)
1つのパスのみをクロールするには、詳細設定の”URLのみを含めるフィールド”を使用します。
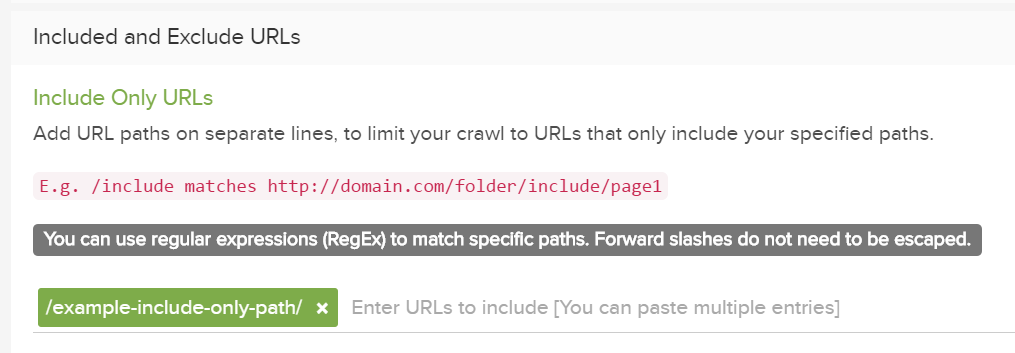
URLパスを個別の行に追加して、指定したパスのみを含むURLにクロールを制限します。
注:デフォルトでは、正規表現一致構文が使用されます。スラッシュをエスケープする必要はありません。
除外されたURL(負の制限)
詳細設定の”除外されたURL”フィールドを使用して、レポートに表示する必要のないページまたはチャネルを除外します。
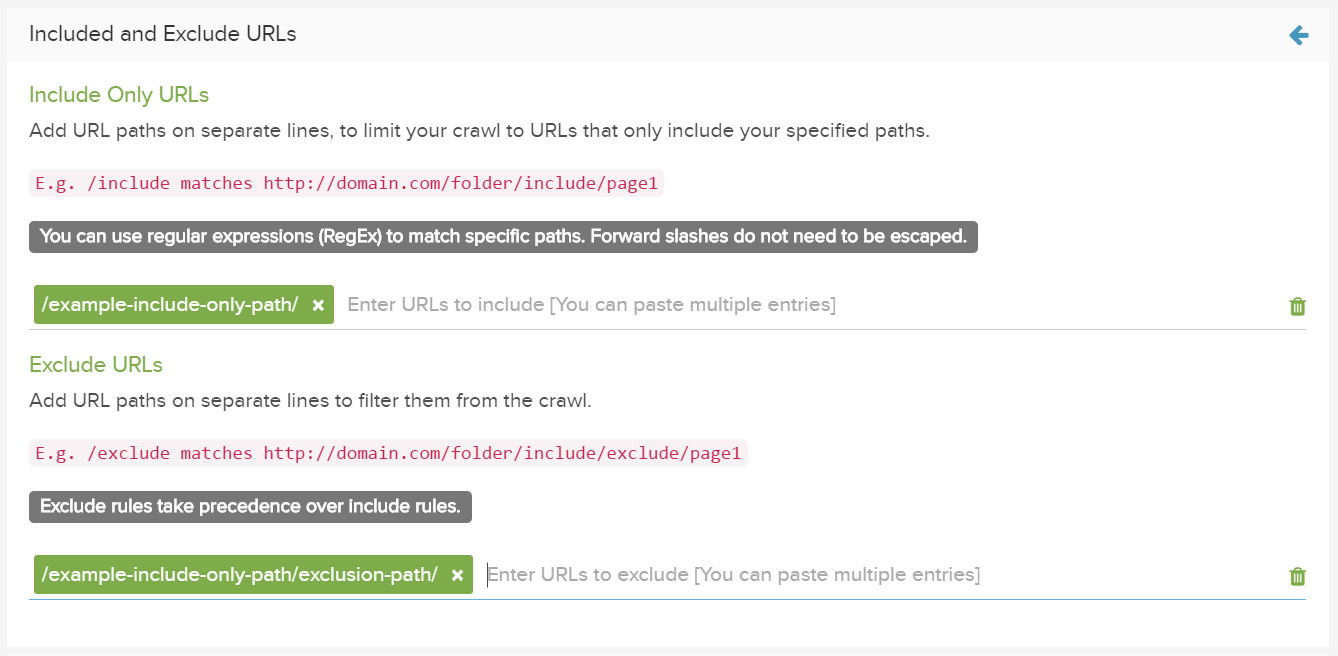
包含/除外フィルターは、ホスト名やプロトコルを含む完全なURLでも機能します。
例えば、HTTPSサイトがクロールされないようにする方法は次のとおりです。
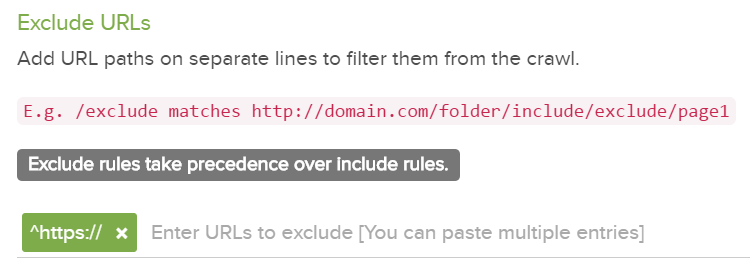
注:除外規則は、包含規則よりも優先されます。すべてのマッチングルールはRubyの正規表現を使用するため、スラッシュをエスケープする必要はありません。また、全てのパスはワイルドカードで自動的に開始および終了するため、追加する必要はありません。
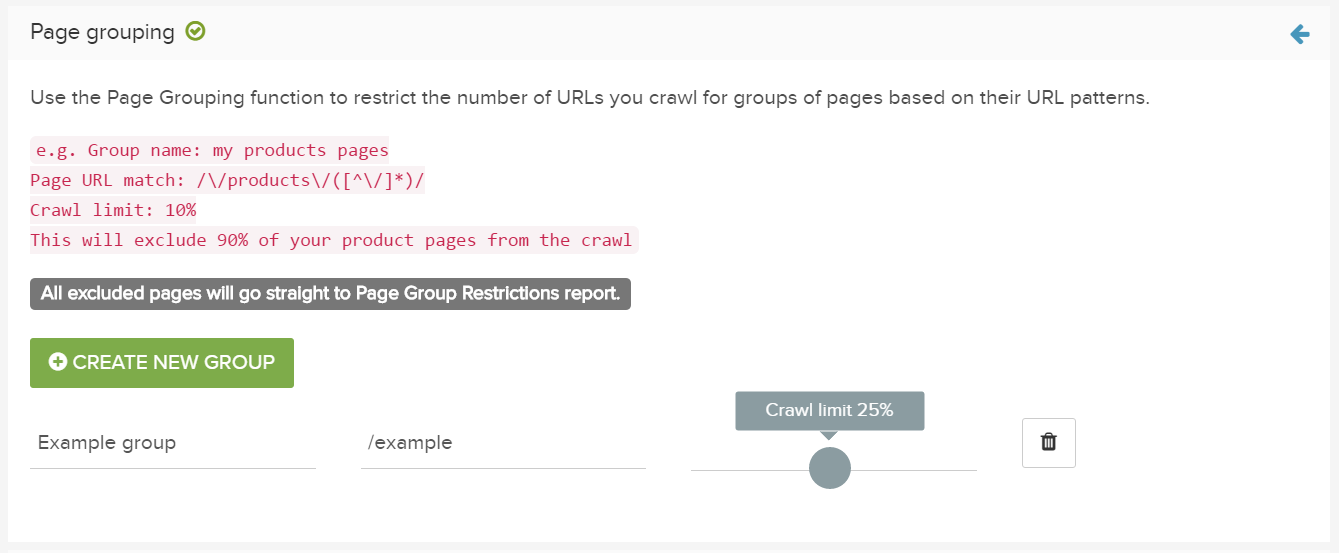
ページのグループ化
ページグループ化フィールドでは、URLパターンに基づいて、ページのグループに対してクロールされるURLの割合を制限することもできます。
クロールする名前、正規表現またはディレクトリ、および一致するURLの最大パーセンテージを追加します。
グループに一致するURLはすべてカウントされます。制限に達すると、新しいURLはクロールされませんが、ページグループの制限付きURLレポートには含まれます。
例: