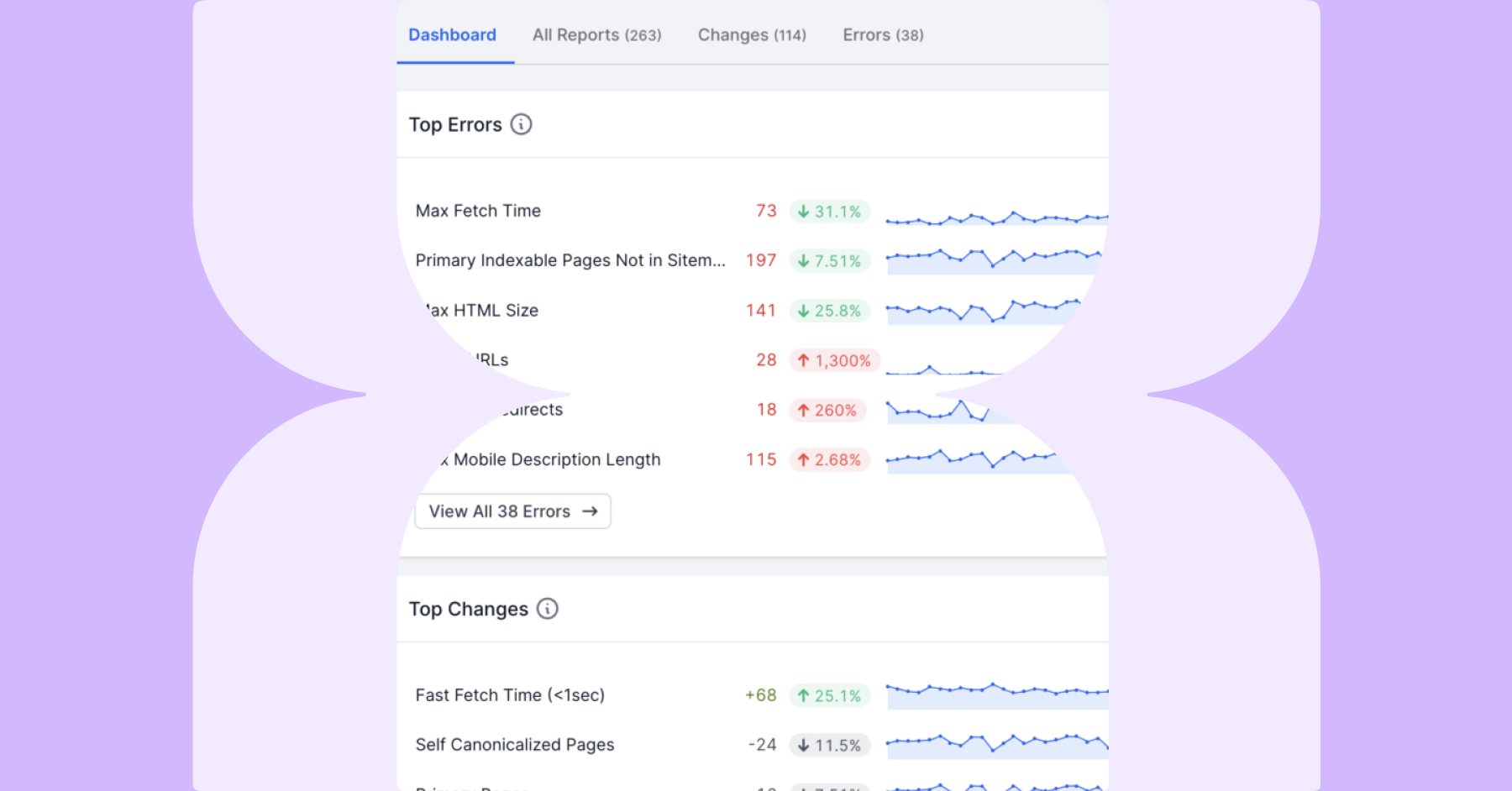

すでに新しいクローラーに施された改善点をご覧になった方も多いことでしょう。これら改善により当社のクローラーは現在のマーケットで最も解析速度の早いクローラーとなっただけでなく、Lumarは精度高くGoogleの動きを表現し、ウェブページから取得するデータの拡張性や柔軟性が飛躍的に向上しています。それではそれぞれの点を詳しく見ていきましょう。
クロールスピードの改善
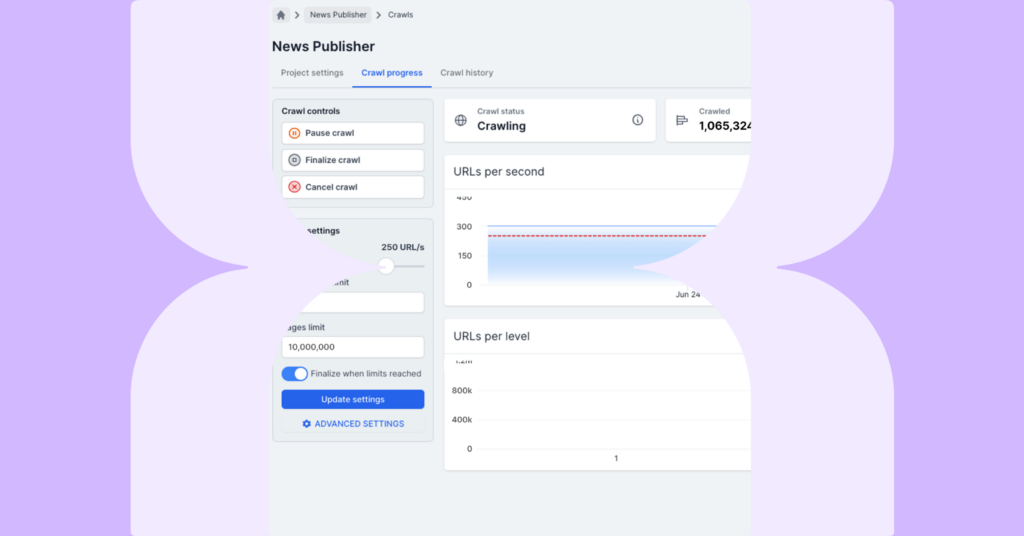
最新のサーバーレス技術を活用することで、我々はクロールスピードを技術的に最高の速度まで引き上げることに成功しました。フィールドテストでは、 レンダリングのないコンテンツのクロールでは秒速450ものURL、レンダリングのあるコンテンツについては秒速350URLもの速度を記録しました。クロールスピードが上がると、データの処理速度が向上し、できるだけ素早くインサイトを取得することが出来るようになります。
いくつかの注意点
この度の機能改善によって最速のスピードで効率的なクロールが可能となりましたが、注意しておくべき重要な点もいくつかあります。 最速のスピードでクロールができたとしても、サーバーがその速度を許容できない可能性があり、それによってUXやパフォーマンスを阻害してしまう可能性があります。こうした問題を避けるため、Lumarではアカウント毎にクロールの最高速度をしていますが、このスピードは個別に検討して上げていくことも可能です。しかしながら、次のような点には注意していただく必要があります。
- クロールスピードの変更をリクエスト頂く前に DevOpsチームにご相談いただき、お使いのインフラが処理できるクロールレートを把握してください。
- サイトへのトラフィックが少ない時間(例:午前1時〜5時の間等)にクロールをスケジュールしておくことを推奨しています。月間の閲覧数が5000万〜のサイトで秒速30URL以上のクロールスピードにしたい場合、可能な限りトラフィックの少ない時間帯に行ったほうが安全です。いずれにせよ、DevOpsチームにまずはご相談いただき最適なクロールレートを検討いただければと思います。
- 効率的なクロールを実行するためにクローラーのIPアドレス (52.5.118.182 または 52.86.188.211) をホワイトリストにしておくようにしてください。
精度の高いGoogleの動きの表現
Lumarでは業界を牽引するGoogleのレンダリング、解析エンジンに限りなく挙動を近づけています。これはお客様に以下のような様々な価値を提供することに繋がると考えています。
- LumarではDOMの作成とフルリクエスト、そしてJavaScriptレンダリングの有無に関わらず解析を行うためにChromiumを使っています。指標を抽出するための実際のHTMLはViewSourceではなくChrome内 (検証 > エレメント)に存在しています。レンダリング前のDOMのような要素をブラウザで確認するにはJSレンダリングを無効化しておく必要があります。
- Googleの検索結果に表示されている内容を複製したり、データを解釈しやすくしたりしているので、それぞれの文字は様々な形で保存、表示されることになります。したがって、h1_tag, page_title, url_to_titleなどを含む複数の指標で変化が見られます。
- Googleの挙動とできるだけ合致させるために、robots.txtにおけるnoindexのサポートは修了しました。robots.txtファイルでnoindex指定されているページはインデックスされているものとして検出されます。
- Googleが公開している大まかな上限に基づき Lumarではページごとのリンク数を5000に制限しています。この上限を超えるリンクはクロールされません。
データの改善
Googleの実際の動きを反映し、Lumarから得られるインサイトを最大限に発揮するため、データの質という観点でも次のような改善を施しました。
- word_countやcontent_sizeがbody要素のみから計算されることから指標の精度が大きく改善しています。レポートされるcontent_sizeの指標が僅かに少くなるため、(内容の)薄いページの数がこれまでのツールより増えて感じるかもしれません。重複コンテンツを定義するロジックにおいてコンテンツの扱いも少し変化したため、重複bodyコンテンツ、重複ページなどの指標でも変化があるかもしれません。他にも、 content_html_ratioやrendered_word_count_など、多少変化のある指標がいくつかあります。
- ホワイトスペースの違いによりユニークリンクが存在するリスクを削減するためアンカーテキストにあるホワイトスペースを削除しています。したがって、アンカーテキストの種類によっては、最初のクロールで多くの追加済・削除済ユニークリンクを目にするかもしれません。
- meta_title_length_pxという指標の算出方法が改善されました。 この指標に該当する結果に加え、最大タイトルのレポート結果がわずかに多く出てくるかもしれません。
- 最大タイトルのレポートと整合性を保つため、s や n, tなどの要素もmeta descriptionから抽出されはじき出されるようになります。 You may see differences in the meta_dexcriptionやmeta_description_lengthのような指標でも変化が見られるようになりますし、最大ディスクリプションレポートで表示されるページ数が少なくなります。
- 以前はa_locationのデータが提供されている場合には、300, 304, 305, 306などのステータスはリダイレクトとして扱われていましたが、これらはリダイレクトではないものとして扱われるようになるため、これまでのツールよりリダイレクト数は減少するケースが多くなります。
- Meta_noopdやmeta_noydir、noodp、noydirなどの指標の(解析における)価値を低く捉えるようになりました。これらの指標がLumarから消えるわけではありませんが、デフォルトではFALSEの値として捉えられることになります。
- すべての有効なフォールバック値はvalid_twitter_cardの指標計算に反映されるようになり、この指標でも変化が見られます。
- DeepRankの計算においてもHTMLと非HTMLページをともに考慮するようになったため、改善が見られます。
その他の改善点
加えて以下の改善点もあります。
- 構造化データの指標で非JSクロールが利用できるようになりました。
- JSレンダリングを有効化したままでリージョナルIPとカスタムピクセルのクロール(ステルスモードも含む)も可能になりました。
- AMPページに関する指標が新しく追加され、AMPページ指標レポートに関してより多くのレポートが表示されるようになりました。新しい指標には次のようなものがあります。
mobile_desktop_content_difference
mobile_desktop_content_mismatch
mobile_desktop_links_in_difference
mobile_desktop_links_out_difference
mobile_desktop_wordcount_difference
- 最大ページサイズの上限が削除され、タイムアウト期間内でChromiumが処理できるものであれば何でもレポートすることが可能になりました。これにより、新しいページ(そしてそれらのページからリンクされているページも)が新しく解析することができます。
- サポート対象ではないリソースについてもレポートが可能になりました。HTTPステータス、コンテンツのタイプやサイズを含む追加レポーティングです。加えて非HTTPページについてのレポーティングもできるようになりました。
- 対応できるリダイレクト数も10から15へと増えました。レポートで更に長いリダイレクトチェーンを確認できます(例:リダイレクトチェーンレポート)
- クロールの完了とレポート結果の表示までの間の時間を減らすため、処理スピードも改善しました。
- スタートURLのfound_atの指標が空白としてレポートされるようになりました。 これまでfound_atは該当クロールが検出された最初のURLを検出していました。
- 最後に、与えられたURLに対する実際のリダイレクトと合致させるために、redirects_in_countの指標も改善しました。
新しいクローラーについて、予めご理解いただきたい点は他にもいくつかあります。
- ウェブクロールにおいてURLがクロールされる順序が変わりました。 部分的にクロールが実行されるタイミングで、クロールが初めて実行される場合にはURLが変化する可能性があります。
- content_sizeは(容量を示す)バイトサイズではなく文字の長さで計測されるようになりました。これは、2バイトではなく1文字として計測されるようになることから、非UTF文字列に対して影響があります。
- meta refreshリダイレクトが以前はプライマリページとしてレポートされていたバグを修正しました。結果としてプライマリページ数が少なくなっています。
- クロールレートは実際に処理されたURL数を示すようになったことで、大量のURLにフェッチが同時に完了できるようになりました。これにより、更に多くのURL処理が可能となっています。設定値よりもクロールレートが高く表示されていても、実際のクロールレート設定としては上限を超えていないことになります。
- 不正なURLはリンクカウントに含まれなくなりました。したがってレポートにおけるlink_out_countの指標が少なく表示されるようになりました。
- Chromiumが解析できないURLを不正なURLとして捉えるようになっています。未クロールレポートの数に変化が生じています。
- 他のソースを必要とする一部のレポートの動作方法を変更しました(例:ログサマリーにないページ、リストにないページ、SERPsにない主要ページ、ボットヒットのないインデックス可能なページなど)。これらのレポートは、必要なソースが有効になっている場合にのみ入力されます。たとえば、「Pages not in Log Summary」レポートには、プロジェクトでログファイルソースを有効にしている場合のみ、URLが含まれます。