

In this section of our guide to robots.txt directives, we’ll go into more detail about the robots.txt text file and how it can be used to instruct the search engine web crawlers. This file is especially useful for managing crawl budget and making sure search engines are spending their time on your site efficiently and crawling only the important pages.
What is a robots txt file used for?
The robots.txt file is there to tell crawlers and robots which URLs they should not visit on your website. This is important to help them avoid crawling low-quality pages, or getting stuck in crawl traps where an infinite number of URLs could potentially be created, for example, a calendar section that creates a new URL for every day.
As Google explains in their robots.txt specifications guide, the file format should be plain text encoded in UTF-8. The file’s records (or lines) should be separated by CR, CR/LF or LF.
You should be mindful of the size of a robots.txt file, as search engines have their own maximum file size limits. The maximum size for Google is 500KB.

Where should the robots.txt exist?
The robots.txt should always exist on the root of the domain, for example:

This file is specific to the protocol and full domain, so the robots.txt on https://www.example.com does not impact the crawling of https://www.example.com or https://subdomain.example.com; these should have their own robots.txt files.
When should you use robots.txt rules?
In general, websites should try to utilize the robots.txt as little as possible to control crawling. Improving your website’s architecture and making it clean and accessible for crawlers is a much better solution. However, using robots.txt where necessary to prevent crawlers from accessing low-quality sections of the site is recommended if these problems cannot be fixed in the short term.
Google recommends only using robots.txt when server issues are being caused or for crawl efficiency issues, such as Googlebot spending a lot of time crawling a non-indexable section of a site, for example.
Some examples of pages that you may not want to be crawled are:
- Category pages with non-standard sorting as this generally creates duplication with the primary category page
- User-generated content that cannot be moderated
- Pages with sensitive information
- Internal search pages as there can be an infinite amount of these result pages which provides a poor user experience and wastes crawl budget
When shouldn’t you use robots.txt?
The robots.txt file is a useful tool when used correctly, however, there are instances where it isn’t the best solution. Here are some examples of when not to use robots.txt to control crawling:
1. Blocking Javascript/CSS
Search engines need to be able to access all resources on your site to correctly render pages, which is a necessary part of maintaining good rankings. JavaScript files that dramatically change the user experience but are disallowed from crawling by search engines may result in manual or algorithmic penalties.
For instance, if you serve an ad interstitial or redirect users with JavaScript that a search engine cannot access, this may be seen as cloaking and the rankings of your content may be adjusted accordingly.
2. Blocking URL parameters
You can use robots.txt to block URLs containing specific parameters, but this isn’t always the best course of action. It is better to handle these in Google Search console as there are more parameter-specific options there to communicate preferred crawling methods to Google.
You could also place the information in a URL fragment (/page#sort=price), as search engines do not crawl this. Additionally, if a URL parameter must be used, the links to it could contain the rel=nofollow attribute to prevent crawlers from trying to access it.
3. Blocking URLs with backlinks
Disallowing URLs within the robots.txt prevents link equity from passing through to the website. This means that if search engines are unable to follow links from other websites as the target URL is disallowed, your website will not gain the authority that those links are passing and as a result, you may not rank as well overall.
4. Getting indexed pages deindexed
Using Disallow doesn’t get pages deindexed, and even if the URL is blocked and search engines have never crawled the page, disallowed pages may still get indexed. This is because the crawling and indexing processes are largely separate.
5. Setting rules which ignore social network crawlers
Even if you don’t want search engines to crawl and index pages, you may want social networks to be able to access those pages so that a page snippet can be built. For example, Facebook will attempt to visit every page that gets posted on the network, so that they can serve a relevant snippet. Keep this in mind when setting robots.txt rules.
6. Blocking access from staging or dev sites
Using robots.txt to block an entire staging site isn’t the best practice. Google recommends noindexing the pages but allowing them to be crawled, but in general, it is better to render the site inaccessible from the outside world.
7. When you have nothing to block
Some websites with a very clean architecture have no need to block crawlers from any pages. In this situation, it’s perfectly acceptable not to have a robots.txt file, and return a 404 status when it’s requested.
Robots.txt syntax and formatting
Now that we’ve learned what robots.txt is and when it should and shouldn’t be used, let’s take a look at the standardized syntax and formatting rules that should be adhered to when writing a robots.txt file.
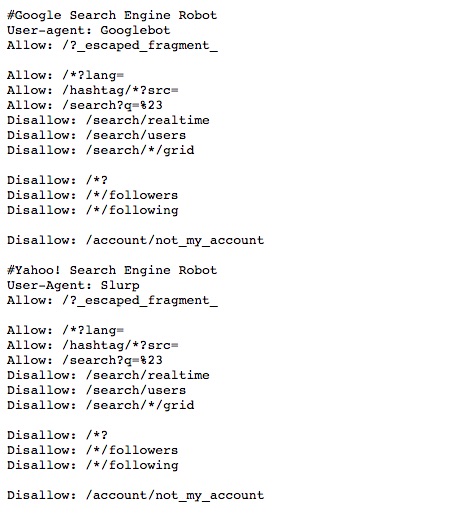
Comments
Comments are lines that are completely ignored by search engines and start with a #. They exist to allow you to write notes about what each line of your robots.txt does, why it exists, and when it was added. In general, it is advised to document the purpose of every line of your robots.txt file, so that it can be removed when it is no longer necessary and is not modified while it is still essential.
Specifying user-agent
A block of rules can be applied to specific user agents using the “User-agent” directive. For instance, if you wanted certain rules to apply to Google, Bing, and Yandex; but not Facebook and ad networks, this can be achieved by specifying a user agent token that a set of rules applies to.
Each crawler has its own user-agent token, which is used to select the matching blocks.
Crawlers will follow the most specific user agent rules set for them with the name separated by hyphens, and will then fall back to more generic rules if an exact match isn’t found. For example, Googlebot News will look for a match of ‘googlebot-news’, then ‘googlebot’, then ‘*’.
Here are some of the most common user agent tokens you’ll come across:
- * – The rules apply to every bot, unless there is a more specific set of rules
- Googlebot – All Google crawlers
- Googlebot-News – Crawler for Google News
- Googlebot-Image – Crawler for Google Images
- Mediapartners-Google – Google Adsense crawler
- Bingbot – Bing’s crawler
- Yandex – Yandex’s crawler
- Baiduspider – Baidu’s crawler
- Facebot – Facebook’s crawler
- Twitterbot – Twitter’s crawler
This list of user agent tokens is by no means exhaustive, so to learn more about some of the crawlers out there, take a look at the documentation published by Google, Bing, Yandex, Baidu, Facebook and Twitter.
The matching of a user agent token to a robots.txt block is not case sensitive. E.g. ‘googlebot’ will match Google’s user agent token ‘Googlebot’.
Pattern matching URLs
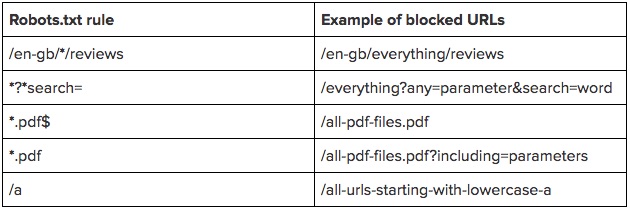
You might have a particular URL string you want to block from being crawled, as this is much more efficient than including a full list of complete URLs to be excluded in your robots.txt file.
To help you refine your URL paths, you can use the * and $ symbols. Here’s how they work:
- * – This is a wildcard and represents any amount of any character. It can be at the start or in the middle of a URL path, but isn’t required at the end. You can use multiple wildcards within a URL string, for example, “Disallow: */products?*sort=”. Rules with full paths should not start with a wildcard.
- $ – This character signifies the end of a URL string, so “Disallow: */dress$” will match only URLs ending in “/dress”, and not “/dress?parameter”.
It’s worth noting that robots.txt rules are case sensitive, meaning that if you disallow URLs with the parameter “search” (e.g. “Disallow: *?search=”), robots might still crawl URLs with different capitalisation, such as “?Search=anything”.
The directive rules match against URL paths only, and can’t include a protocol or hostname. A slash at the start of a directive matches against the start of the URL path. E.g. “Disallow: /starts” would match to www.example.com/starts.
Unless you add a start a directive match with a / or *, it will not match anything. E.g. “Disallow: starts” would never match anything.
To help visualize the ways different URLs rules work, we’ve put together some examples for you:
Robots.txt Sitemap Link
The sitemap directive in a robots.txt file tells search engines where to find the XML sitemap, which helps them to discover all the URLs on the website. To learn more about sitemaps, take a look at our guide on sitemap audits and advanced configuration.
When including sitemaps in a robots.txt file, you should use absolute URLs (i.e. https://www.example.com/sitemap.xml) instead of relative URLs (i.e. /sitemap.xml.) It’s also worth noting that sitemaps don’t have to sit on one root domain, they can also be hosted on an external domain.
Search engines will discover and may crawl the sitemaps listed in your robots.txt file, however, these sitemaps will not appear in Google Search Console or Bing Webmaster Tools without manual submission.
Robots.txt blocks
The “disallow” rule in the robots.txt file can be used in a number of ways for different user agents. In this section, we’ll cover some of the different ways you can format combinations of blocks.
It’s important to remember that directives in the robots.txt file are only instructions. Malicious crawlers will ignore your robots.txt file and crawl any part of your site that is public, so disallow should not be used in place of robust security measures.
Multiple user-agent blocks
You can match a block of rules to multiple user agents by listing them before a set of rules, for example, the following disallow rules will apply to both Googlebot and Bing in the following block of rules:
User-agent: googlebot
User-agent: bing
Disallow: /a
Spacing between blocks of directives
Google will ignore spaces between directives and blocks. In this first example, the second rule will be picked up, even though there is a space separating the two parts of the rule:
[code]
User-agent: *
Disallow: /disallowed/
Disallow: /test1/robots_excluded_blank_line
[/code]
In this second example, Googlebot-mobile would inherit the same rules as Bingbot:
[code]
User-agent: googlebot-mobile
User-agent: bing
Disallow: /test1/deepcrawl_excluded
[/code]
Separate blocks combined
Multiple blocks with the same user agent are combined. So in the example below, the top and bottom blocks would be combined and Googlebot would be disallowed from crawling “/b” and “/a”.
User-agent: googlebot
Disallow: /bUser-agent: bing
Disallow: /aUser-agent: googlebot
Disallow: /a
Robots.txt allow
The robots.txt “allow” rule explicitly gives permission for certain URLs to be crawled. While this is the default for all URLs, this rule can be used to overwrite a disallow rule. For example, if “/locations” is disallowed, you could allow the crawling of “/locations/london” by having the specific rule of “Allow: /locations/london”.
Robots.txt prioritization
When several allow and disallow rules apply to a URL, the longest matching rule is the one that is applied. Let’s look at what would happen for the URL “/home/search/shirts” with the following rules:
Disallow: /home
Allow: *search/*
Disallow: *shirts
In this case, the URL is allowed to be crawled because the Allow rule has 9 characters, whereas the disallow rule has only 7. If you need a specific URL path to be allowed or disallowed, you can utilize * to make the string longer. For example:
Disallow: *******************/shirts
When a URL matches both an allow rule and a disallow rule, but the rules are the same length, the disallow will be followed. For example, the URL “/search/shirts” will be disallowed in the following scenario:
Disallow: /search
Allow: *shirts
Robots.txt directives
Page level directives (which we’ll cover later on in this guide) are great tools, but the issue with them is that search engines must crawl a page before being able to read these instructions, which can consume crawl budget.
Robots.txt directives can help to reduce the strain on crawl budget because you can add directives directly into your robots.txt file rather than waiting for search engines to crawl pages before taking action on them. This solution is much quicker and easier to manage.
The following robots.txt directives work in the same way as the allow and disallow directives, in that you can specify wildcards (*) and use the $ symbol to denote the end of a URL string.
Robots.txt noIndex
Robots.txt noindex is a useful tool for managing search engine indexing without using up crawl budget. Disallowing a page in robots.txt doesn’t mean it is removed from the index, so the noindex directive is much more effective to use for this purpose.
Google doesn’t officially support robots.txt noindex, and you shouldn’t rely on it because although it works today, it may not do so tomorrow. This tool can be helpful though and should be used as a short-term fix in combination with other longer-term index controls, but not as a mission-critical directive. Take a look at the tests run by ohgm and Stone Temple which both prove that the feature works effectively.
Here’s an example of how you would use robots.txt noindex:
[code]
User-agent: *
NoIndex: /directory
NoIndex: /*?*sort=
[/code]
As well as noindex, Google currently unofficially obeys several other indexing directives when they’re placed within the robots.txt. It is important to note that not all search engines and crawlers support these directives, and the ones which do may stop supporting them at any time – you shouldn’t rely on these working consistently.
Common robots.txt issues
There are some key issues and considerations for the robots.txt file and the impact it can have on a site’s performance. We’ve taken the time to list some of the key points to consider with robots.txt as well as some of the most common issues which you can hopefully avoid.
- Have a fallback block of rules for all bots – Using blocks of rules for specific user agent strings without having a fallback block of rules for every other bot means that your website will eventually encounter a bot that does not have any rulesets to follow.
- It is important that robots.txt is kept up to date – A relatively common problem occurs when the robots.txt is set during the initial development phase of a website, but is not updated as the website grows, meaning that potentially useful pages are disallowed.
- Be aware of redirecting search engines through disallowed URLs – For example, /product > /disallowed > /category
- Case sensitivity can cause a lot of problems – Webmasters may expect a section of a website not to be crawled, but those pages may crawled because of alternate casings i.e. “Disallow: /admin” exists, but search engines crawl “/ADMIN”.
- Don’t disallow backlinked URLs – This prevents PageRank from flowing to your site from others that are linking to you.
- Crawl Delay can cause search issues – The “crawl-delay” directive forces crawlers to visit your website slower than they would have liked, meaning that your important pages may be crawled less often than is optimal. This directive is not obeyed by Google or Baidu, but is supported by Bing and Yandex.
- Make sure the robots.txt only returns a 5xx status code if the whole site is down – Returning a 5xx status code for /robots.txt indicates to search engines that the website is down for maintenance. This typically means that they will try to crawl the website again later.
- Robots.txt disallow overrides the parameter removal tool – Be mindful that your robots.txt rules may override parameter handling and any other indexation hints that you may have given to search engines.
- Sitelinks Search Box markup will work with internal search pages blocked – Internal search pages on a site do not need to be crawlable for the Sitelinks Search Box markup to work.
- Disallowing a migrated domain will impact the success of the migration – If you disallow a migrated domain, search engines won’t be able to follow any of the redirects from the old site to the new one, so the migration is unlikely to be a success.
Testing & Auditing Robots.txt
Considering just how harmful a robots.txt file can be if the directives within aren’t handled correctly, there are a few different ways you can test it to make sure it has been set up properly. Take a look at this guide on how to audit URLs blocked by robots.txt, as well as these examples:
- Use Lumar – The Disallowed Pages and Disallowed URLs (Uncrawled) reports in Lumar can show you which pages are being blocked from search engines by your robots.txt file.
- Use Google Search Console – With the GSC robots.txt tester tool you can see the latest cached version of a page, as well as using the Fetch and Render tool to see renders from the Googlebot user agent as well as the browser user agent. Things to note: GSC only works for Google User agents, and only single URLs can be tested.
- Try combining the insights from both tools by spot-checking disallowed URLs that Lumar has flagged within the GSC robots.txt tester tool to clarify the specific rules which are resulting in a disallow.
Monitoring robots.txt changes
When there are lots of people working on a site, and with the issues that can be caused if even one character is out of place in a robots.txt file, constantly monitoring your robots.txt is crucial. Here are some ways in which you can check for any issues:
- Check Google Search Console to see the current robots.txt which Google is using. Sometimes robots.txt can be delivered conditionally based on user agents, so this is the only method to see exactly what Google is seeing.
- Check the size of the robots.txt file if you have noticed significant changes to make sure it is under Google’s 500KB size limit.
- Go to the Google Search Console Index Status report in advanced mode to cross-check robots.txt changes with the number of disallowed and allowed URLs on your site.
- Schedule regular crawls with Lumar to see the number of disallowed pages on your site on an ongoing basis, so you can track changes.
Next: URL-level Robots Directives











