
Our latest Lumar (formerly Deepcrawl) webinar dives deep into how you can use custom extractions to get even better insights from your crawl data.
Custom Extractions are an advanced crawling technique that offer new ways to understand your own websites — and those of your competitors.
This session’s guest, Reuben Yau, has been working in SEO since 2000 and now serves as Vice President of SEO at Vizion Interactive. In conversation with Lumar’s Chris Spann, the two talk through what custom extractions are, how to use them to build custom data feeds, how to use them for competitor analysis, and suggest a few challenges to watch out for along the way.
It’s a jam-packed presentation. Read on for our key takeaways for the session, but, as always, be sure to check out the embedded video above for the full talk (as well as the fascinating Q&A!).
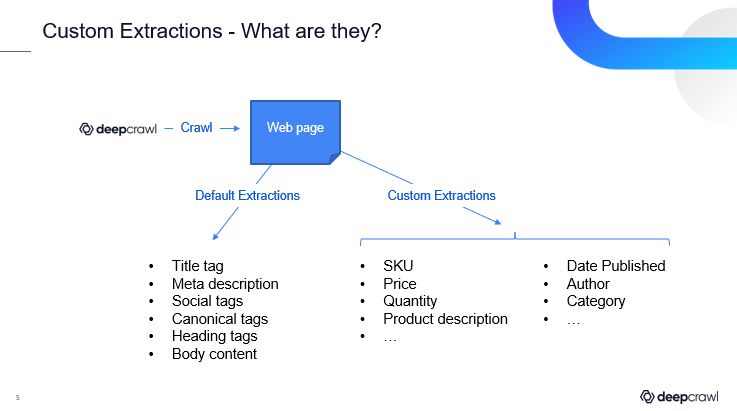
What are custom extractions?
If you are familiar with Lumar’s Analyze crawler already, you will no doubt recognize the many default extractions included in the platform. These are some of the most crucial extractions for SEO, such as title tags, meta descriptions, canonical tags, etc.
But Lumar’s platform also allows for custom extractions. This gives SEOs the option to pull out virtually any other type of page content or data available – including information that isn’t overtly search-centric but can help with competitor analysis and make our overall SEO and website health reports more robust.
As Yau points out, custom extractions are really only limited to the kind of content contained on the site in question. For example, on an eCommerce website, perhaps you want to pull out SKUs or prices. For content-led sites or blogs, perhaps you want to extract the dates on which posts were published or author names.
Custom extractions allow you to do all that and more.
Custom extractions for competitor analysis
Yau talks us through how custom extractions can be used to compare the pricing on our own sites with those of our competitors. Here’s how to do it within the Lumar (formerly Deepcrawl) platform:
First, we want to create a new project, then go to ‘Advanced Settings’ in step 4.
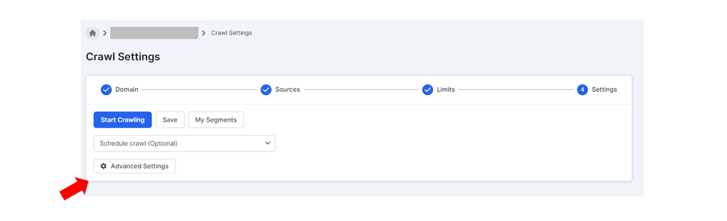
In Advanced Settings, click on ‘New Extraction Rule’. [You can create up to 30.]
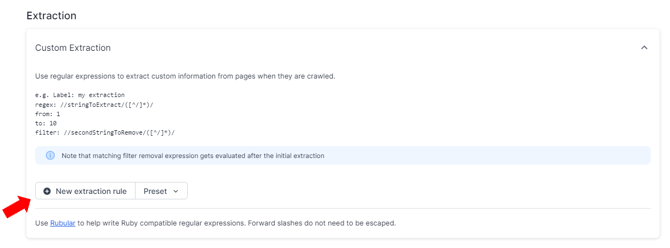
Viewing the source HTML in our example, we see the price is contained in a <span> tag:
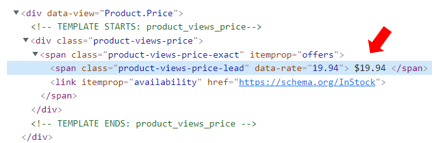
In the ‘New Extraction Rule’ tab we can add a label to make it easier to use later on (as opposed to ‘custom extraction 1’ etc.). We also need to add the regex pattern — i.e. the code used to help identify the price. [Tip: use Rubular to test your regex – it uses Ruby, like Lumar does, so it will provide the best consistency.]
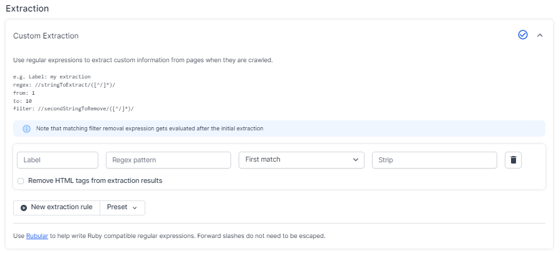
This tab also gives us the option to pull out just the first match (in our case, there is only a single price on each page crawled). And we can also choose to strip out any additional code/text from the crawl if we don’t want it to be included in our results.
Once you’ve added all the custom extractions you want, simply run the crawl. When it’s finished, go to the ‘Extraction’ menu, then ‘Overview’, and ‘Extract Report’.
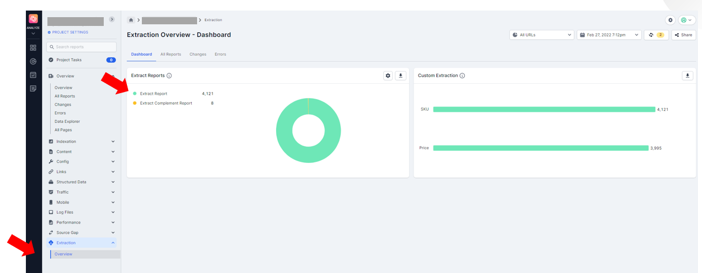
Click on the extractions, select the fields/columns you want to show and export as a CSV.
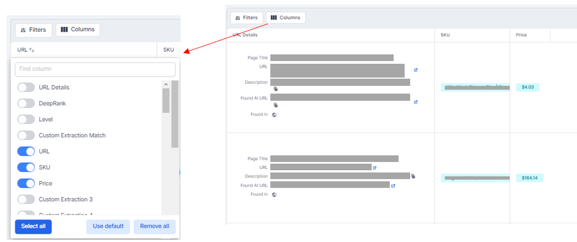
From there, we can import the CSV into an Excel file and do the same for the competitor crawls across separate tabs.
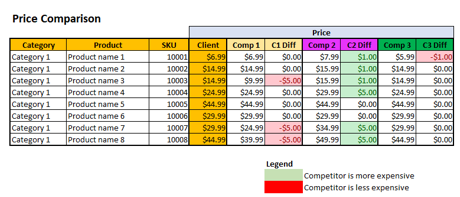
Yau notes how we can then use the VLOOKUP function on SKUs to pull pricing for all competitors into a single view. We can use different calculations and conditional formatting to highlight price differences.
Building custom data feeds
Yau also shows us how to build a data feed to submit to a 3rd party (e.g. Google Merchant Center) for a new website.
Traditionally, in order to do this, we might have to contact our developers and request a database report. But with Lumar, we can do it ourselves. Here’s how:
- Identify the required fields you need to capture, based on the feed’s requirements.
- Build custom extraction rules into a new crawl project.
- Extract the necessary fields.
- Export to a CSV.
- Transform and add extra fields as necessary.
- Upload to the data feed provider.
Boost SEO reporting with custom extractions
Custom extractions are also great for boosting our SEO reports. As an example, Yau shows us how to analyze content performance to get meaningful insights for a new content-focused site/blog by augmenting Google Analytics data with our own customized Lumar data.
Google Analytics is a powerful tool in its own right, but how do we best decide what kind of content to continue producing? Alternatively, how might we justify ceasing the production of certain types of content?
Yau notes that in order to work this out, we need to ask more in-depth questions (and get more detailed data!). For example…
- Which are the best-performing content categories on a site?
- Which authors produce the best-performing content?
- How many posts are published per month?
Sometimes we can get some of this information on Google Analytics, within the URLs (e.g. dates, categories, etc.), but other times a method like custom extractions will be needed to get the information we’re really looking for.

There are also other details we can extract that might help shape our future content campaigns, such as tags, or how many comments certain types of posts are getting.
As Yau details, the process is similar to how we used custom extractions in our competitor analysis example. It goes something like this:
- Set up project.
- Inspect the HTML to see how its structured.
- Build custom extraction rules for the information you’re looking for.
- Run the crawl.
- Export to CSV.
In this example, we want to pull out traffic numbers by blog post and by month in a custom Google Analytics report. We can then export that report to CSV and combine the GA and Lumar custom extraction in one Excel file. Here we can create a pivot table, use VLOOKUP to combine the two data sets, add sparklines, and filter/sort as needed.
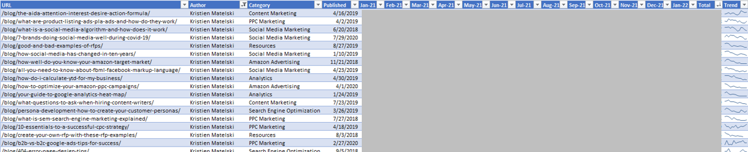
Then we can identify the posts that are performing the best, which ones may be declining, and observe commonalities by author, category, etc.
Challenges and pitfalls in custom extractions
Yau highlights the following crawl issues as potential issues that SEOs need to be aware of when performing custom extractions:
- Avoid needless crawling by crawling from a list, setting a starting URL, or using an XML sitemap.
- Some sites will block crawlers that they don’t recognize; use authentication for owned/client sites— and be polite on other sites.
- Beware of honeypots – some sites may deliberately feed you bad data to try and throw you off.
He also notes the following potential HTML issues:
- Take extra care when working with Javascript/SPA (Single-page application) sites – they can be more difficult to crawl and extract.
- Beware of ‘load more’ functionality instead of pagination – crawlers typically can’t click the button to load more.
- Site redesigns/updates can break the custom extraction rules quite easily if CSS or HTML changes.
- Be aware of site downtime – you may need to recrawl if it fails.
- Site maintenance – when is the database updated?
- Be careful when trying to automate custom extractions. Yau suggests automating the crawling to gather the data then verifying it before importing and going further.
But if SEOs are aware of these potential issues, custom extractions are a powerful way to get the most from your crawls and ensure your sites are performing as well as they can be—for both users and search engines.
—
Interested in working with Reuben Yau? Consider booking a coffee break (bonus: free coffee!) with his team.
Ready to get started with your own custom extractions in Lumar Analytics Hub? Schedule a demo anytime.


