
Want to improve your technical SEO strategies in 2024? We’ve got you covered.
Lumar’s technical SEO experts are joined by Joshua Green, senior SEO manager at Clutch, for a discussion of the top tech SEO hacks and needle-moving tech SEO projects they’ve encountered over their decades of experience in the SEO space.
In this session, we’re covering:
- Flexible SEO crawl strategies
- Parity crawls
- Scaling technical SEO
- Internal linking projects
- Comprehensive tech SEO reporting
- Getting buy-in for technical SEO from developers & the C-suite
Watch the full webinar video above (including Q&A session), or read on for our top takeaways.
The benefits of building flexible SEO crawling strategies
Not all SEO crawl strategies are made equal. Chances are, you don’t need to crawl your entire website every time you want to get insights into your site’s health and performance. Generally, there will be key site sections or key pages that are most important to your SEO strategies. Building flexible, segmented website crawls can help SEOs get the key data they need, significantly faster, since you won’t have to wait for a full site crawl to complete. This can be especially useful for SEOs working on enterprise-scale websites that may potentially house millions of URLs.
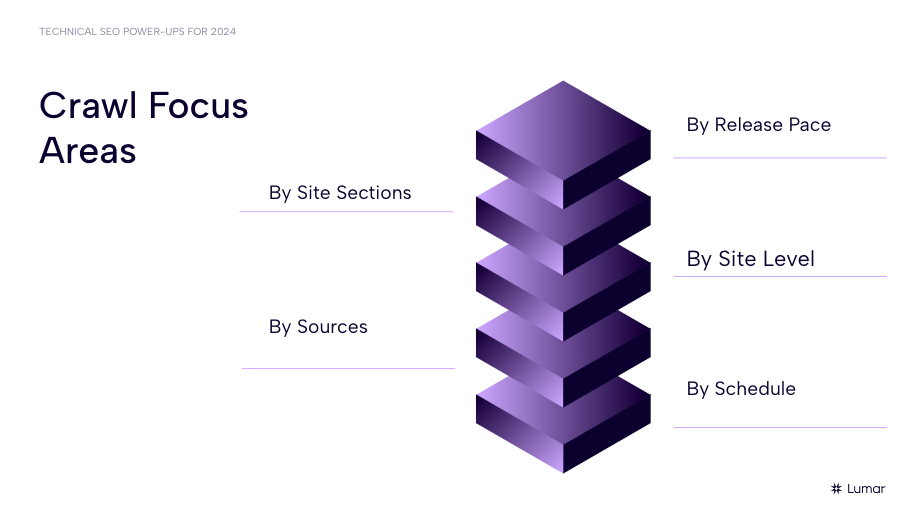
But what works best for one site and for one SEO team might be different for another. Matt Hill offers several different approaches to building out flexible crawl strategies. For instance, you may want to build your crawl strategies around:
- Site sections
- Site level
- Sources
- Release pace
- Schedule

Crawling only specific site sections
While it might occasionally be necessary to carry out a comprehensive crawl on your whole website (if, for instance, you’re doing it for the first time), moving forward, it can make more sense (and save significant time!) to focus your crawls on specific areas of your website. For example: crawling only your high-traffic pages, selected product categories, or other high-value sections.
“It makes much more sense to focus your crawls on sections of your site that you care most about — whether these are top category pages for an eCommerce environment, or if we know that the blog is a section of the site that is consistently updated, that might be a section of the site to focus on for regular crawls,” Matt Hill explains.
“Identifying which are the sections of the site that are touched most often and that really speak to your bottom line is going to be very critical to [building] your crawl strategy.”
When to limit crawl sources for efficiency
Another way to remove bloat in your crawls and narrow your focus on your most important insights is to hand-select which data sources you include in a given website crawl.
“With Lumar, for instance, we provide the opportunity to not just include a standard web crawl as part of your crawl audit, but also to pull together six other crawl sources, including backlink data, [Google] analytics data, log file data, et cetera” explains Hill.
While it’s certainly handy to have all of these data sources incorporated into one SEO crawler, you can always elect to pick and choose which data sources you need for any given crawl. In the case of backlink data, for example, if you already have a historical index of backlinks in place and don’t need to frequently review changes in this area, you can reserve that data source for your more comprehensive crawls and leave it off of your more focused or more frequent crawls.
Crawling your site based on release pace
If you’re working on a large, fast-moving, content-driven site like a major news publishing site or eCommerce site, you’ll likely want to focus on the sections of your site that are being updated most frequently.
If your site releases new content daily, you may want to limit your more regular crawls to focus on your most frequently updated website sections and exclude the parts of your site that are only updated quarterly or yearly.
Crawling based on site level
Another way to build leaner, faster, more agile crawls is to set your crawler to only look at pages that are at or above a specified ‘depth’ in your site structure. If your most important pages tend to be no more than 6 or 7 levels removed from your homepage, you can choose to only crawl pages within those depths.
Setting scheduled crawls
“You can also set a crawling strategy that ensures that you’re always having fresh data from your crawls,” explains Hill. Creating an automated crawl schedule helps make sure the information will be readily available when you need it, without needing to remember to manually run a crawl.
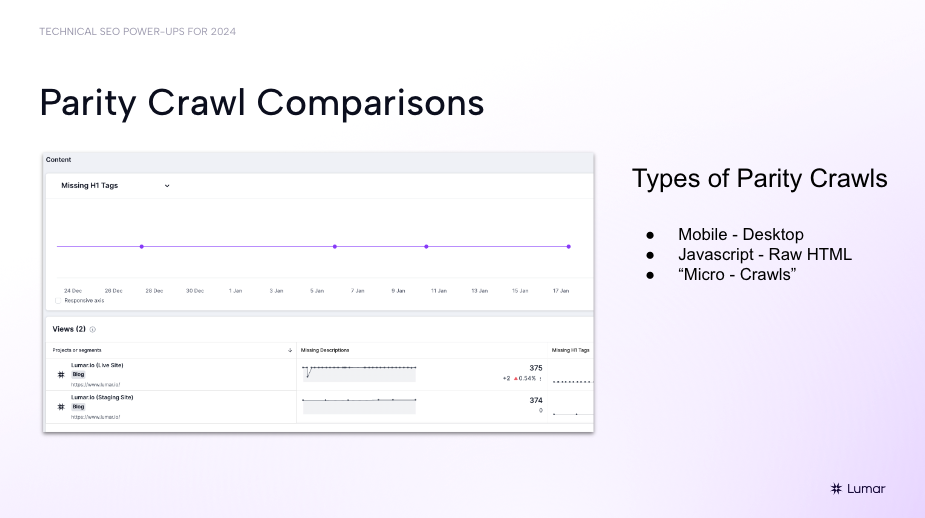
Parity crawls
Examples of parity crawls include mobile vs. desktop content, and pre-render vs. post-render content.
For example, crawling the desktop version of your site and also crawling the mobile version to investigate any differences can help you understand how the content is being rendered on users’ desktop vs. mobile devices. This can be done in the crawler by
“This can be done in a crawler like Lumar using a variety of different user agents, updating the viewport, to really see the nuances,” says Hill.
Hill also suggests running a crawl focusing on pre-rendered pages vs post-rendered pages to examine how search engine crawlers may experience the raw HTML on your JavaScript-heavy pages.
Running parity crawls for site migrations
Hill also points to the importance of what he terms micro-crawls: “Focusing on a comparison of site sections,” he explains. “But here, we’re thinking about a use case where we’re comparing a crawl in a staging environment (pre-production) versus a live environment.”
For site migrations, running a micro-crawl to compare your production site to your live site can help you track any changes between what was planned in staging and what has actually gone live.
Joshua Green gives a specific example of migrating a UK site to a new US site following a company acquisition.
“I was working on a [site] migration following an acquisition — the migration was from the UK site to a US-based site that was opening up a UK business line,” he explains, “The idea was that they were going to essentially migrate the entire old UK site onto the US site.”
By doing representative crawls of about 100 to 200 pages on both the old site and its new domain, he discovered that the marketing team had, just before migration, dynamically appended UTM codes to all of the page redirects — without setting canonicals correctly on the destination site. This caused many duplicate pages, but thankfully, having spotted this relatively early in the process through the parity crawls, they were able to resolve things quickly before taking too much of a traffic hit.
“That could have been a major, major issue having dozens, maybe even a couple hundred versions of each page,” Green says.
Running parity crawls to compare a canonical page against the 195 pages with canonical tags pointing to that page also helped Hill uncover potential crawl budget and page weight issues on another site.

Tools and tips for scaling technical SEO efforts with Lumar
When it comes to technical SEO scalability, Hill points to several Lumar platform features that can help SEOs operate effectively — and efficiently — on large-scale sites. These tools for SEO at scale include:
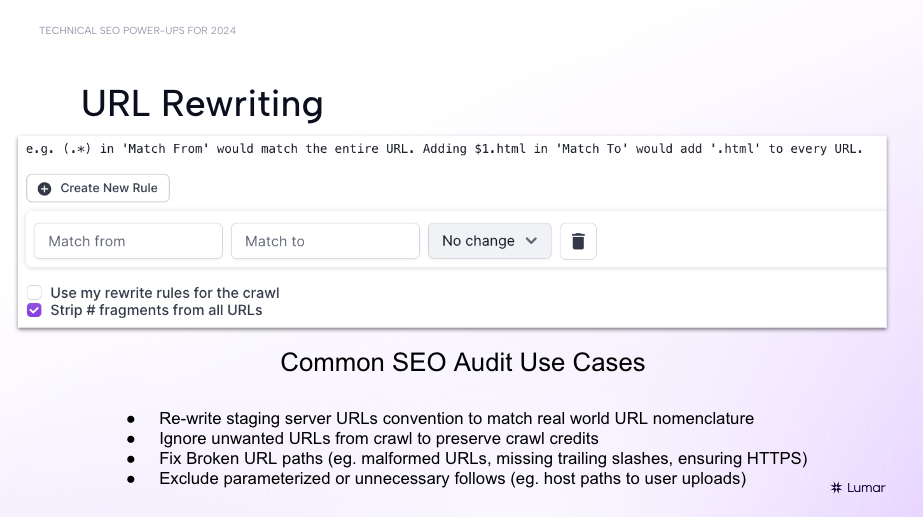
URL rewriting and URL modification tools in Lumar:
These URL writing/URL modification features can help you exclude unwanted URLs from crawls to preserve crawl credits, re-write staging site URLs to match real-world URL nomenclature, fix broken URL paths (for example, malformed URLs, missing trailing slashes, or ensuring HTTPS is in place), and strip out URL parameters at scale.
Render/pre-render comparison reports in Lumar:
Having some built-in comparison reports on your technical SEO platform can take the headache out of running parity crawls.
“We at Lumar really love this particular report: the render/prerender comparison. These charts represent just some of the different comparisons we can do in Lumar,” Hill explains.
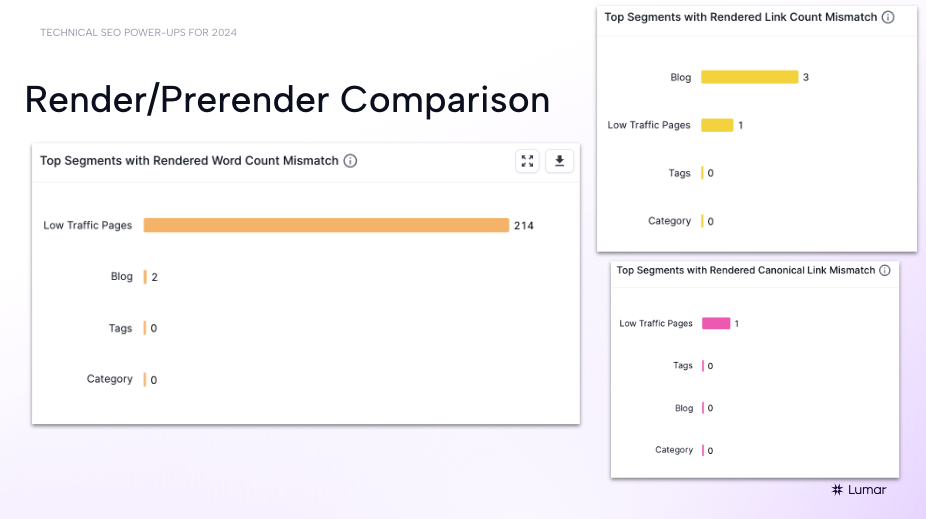
“One thing that is very important — and what Google would like to see in most cases —is that when the user is experiencing content from a desktop to a mobile environment, that content ideally should be as close as 1:1 as possible. But as developers, as SEOs, we all know that’s not always going to be the case, especially as we are changing screen sizes, changing the interactivity of how users engage with content on different devices — things are going to be moved around as part of the layout shift.”
“But with that, what types of changes [between the two versions] are we seeing that are going to potentially impact the relevancy of that page, such as maybe a decrease in word count or a decrease in the number of links that are on the page? Or even in some cases, when the canonical is served, maybe it’s only served in the rendered version and not served in the HTML version. Is there an instance where potentially some JavaScript is sitting above that attribute and it’s potentially breaking the page, not serving the canonical at all?”
“These have been some really interesting conversations that we’ve had with clients here at Lumar — about how this report has actually saved them in a lot of ways, alerting them to issues that they hadn’t really thought about previously.”
Page sampling in Lumar:
“One of the superpowers of Lumar is being able to see and parse data at scale very easily,” Hill says, “Page sampling is a great feature for this.”
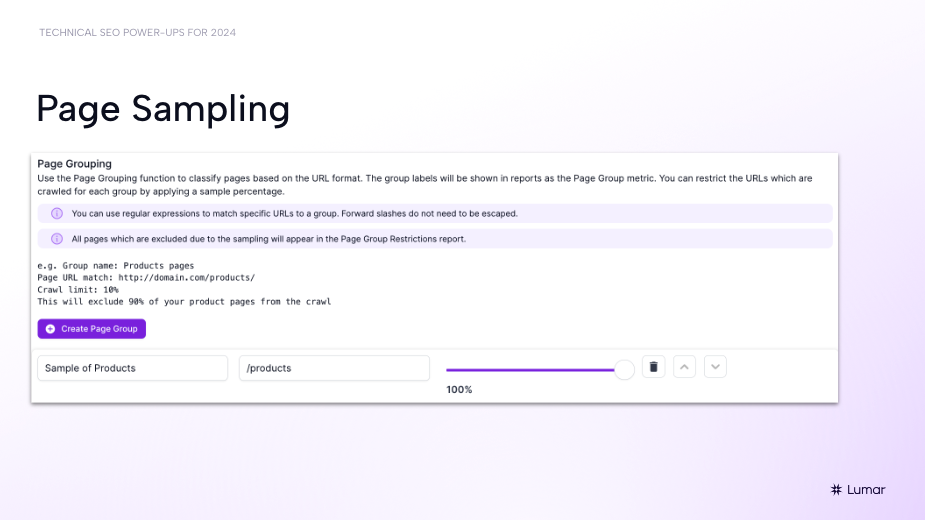
For example, on large e-commerce sites with faceted search or filtering options in place for users to browse product pages, you may have a lot of different URLs that are being generated for those various views of your product pages.
“I’m on e-commerce site regularly where it seems like the variations, the combinations of URLs that can be created by different filtering options on PDPs can be endless,” Hill says. “Dynamic URLs are a great thing for user experience but from a crawling perspective it can really bloat up your audit.”
If there are other site sections beyond just your product pages that you want to focus on in your technical SEO audit crawls, it may be important to just sample those filter-generated product URL sets rather than crawling every single variation. This can help preserve your crawl budget and speed up your crawl times when you’re working on large-scale sites.
“Using page sampling in Lumar, you can choose the rule that you want to create — whether it’s a site section or using regex to create the parameter — and then let the crawler know that you only want to focus on a certain percentage of those URLs to really get the most of out your crawl.
Conducting internal linking audits at scale
“As an SEO, I’ve spent a lot of time in SEO tools that plug into Excel or business intelligence tools; parsing data, shifting different data sets. While those tools are extremely powerful, it’s also important to note that Lumar wants to give you as much functionality as possible using our reports. Everything in our platform is GraphQL API-driven so it can be pushed into whatever platform you feel comfortable with to evaluate the data,” Hill explains.
“Data Explorer is a particularly powerful tool,” Hill says. “Because it allows you to do multiple-dimension viewing across any particular crawl and break site data out by things such as HTTP status code, [site] levels, all the different types of segmentation offerings that we have — and then also look at it against any metric that we have in the platform. I think this is particularly helpful for internal link analysis on the fly.”

Using Data Explorer with your Lumar crawl data (particularly the DeepRank metric) to run an internal linking audit at scale helps you understand where a lot of the link equity is being passed along.
[Side note: DeepRank is a measurement of internal link weight calculated in a similar way to Google’s basic PageRank algorithm. Each internal link is stored and, initially, given the same value. The links are then iterated a number of times, and the sum of all link values pointing to the page is used to calculate their respective DeepRank This process produces a value between 0 and 10.]
As an example, Hill looks at a news publication’s website and shows that even older content pages (articles from as far back as 2011) are still getting some traffic, accruing backlinks, and therefore could be better internally linked within the site structure to pass on some of that weight.

Hreflang analysis at scale for international SEO
Lumar also helps address scale issues for international SEOs dealing with hreflang analyses.
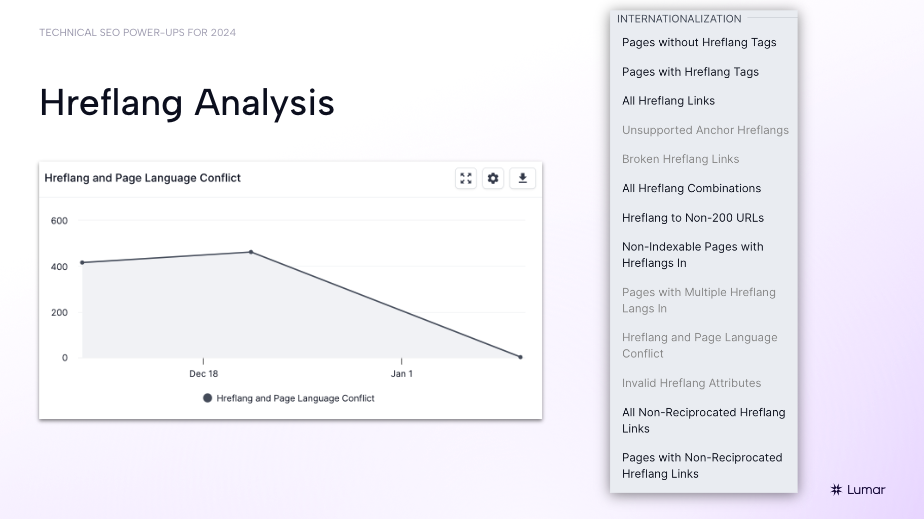
Green shares that he conducted an hreflang analysis on an international site migration project using Lumar and uncovered some key international SEO issues.
Following the launch of multiple international versions of the site, the team started seeing some traffic and ranking issues.
“Google was serving mismatched versions of the pages. A person in the US searching for lodging near Yosemite in California would possibly be getting the Australian version, the en-au version, or the UK version, instead of the en-us version,” he explains.
“We were seeing pages coming in and out of the index sort of frantically; sometimes we wouldn’t have any pages ranking at all,” he says, “Lumar was able to show me at scale where the problem was.”
While he had flagged the potential issue with the internationalized site versions earlier on, at first, he couldn’t get buy-in or resources to address the issue. But armed with concrete data about the hreflang SEO problems following the Lumar-powered audit, Green was able to get buy-in from the broader team and get things changed.
“It [gave me] that ability to show the engineers and the C-suite, which is where I was getting most of the push-back from, that there was an issue that needed fixing. And it needed to be fixed quickly or we were really going to start losing steam. … And if you’ve ever worked with corporate, Fortune 500-level businesses, you know that getting buy-in from C-suite and engineers is key. Lumar has helped me do that quite a few times.”
New Hreflang Validation Reports in Lumar
To help international SEOs working on large-scale websites, we have added 3 new reports to flag additional issues with hreflangs:
- Pages with Multiple Hreflang Links In: Pages with hreflang links in from other pages that have inconsistent language codes.
- Hreflang and Page Language Conflict: Hreflang links where the language code specified in the hreflang attribute does not match the identified language of the target page.
- Invalid Hreflang Attributes: Hreflang attributes where the language specified in the hreflang attribute is not an ISO 639-1 code or the country specified is not a valid ISO 3166-1 code.
See all the latest Lumar platform release notes here.
Getting buy-in for technical SEO with comprehensive reporting, connected SEO-dev workflow tools, & custom extractions
As Green illustrated, it can often be difficult to get buy-in for technical SEO — but it’s extremely important, particularly when working on large enterprise sites.
SEO is a team sport — you’ll need to build processes to align with your developers to ensure your fixes are being enacted. Having the right tools in place can make this a lot simpler.
Lumar’s comprehensive tech SEO reporting — and its tools to build connected SEO-developer workflows — can help SEOs get crucial buy-in and secure the necessary resources from engineers and business leadership.
Creating connected SEO-dev workflows
“SEO isn’t just something that happens retroactively,” Hill says, “We also want to be proactive around how issues are being flagged and building out the communication structure for that.”
“Lumar Protect allows us to take all that detailed reporting that we have and put it in the form of requirements documents — simple instructions for teams of engineers.”
Protect also enables SEOs to take the insights they’ve uncovered in their tech SEO audits and set them as simple thresholds that can be measured on pre-production sites to help ensure potential traffic-sapping changes don’t end up going on to the live site.
Building custom extractions that serve the broader web team
“Another great way to get SEOs and devs to collaborate is by creating opportunities to find additional proprietary things to test for on your site, outside of the standard SEO reporting,” says Hill.
He recommends that broader website teams use Lumar’s custom extraction capabilities to build out tests that might be specific to your business.
For example, in the pharmaceutical industry, you may want to audit your site to ensure that each and every medicine page includes an “important safety information” label.
“This is something that will not only serve SEOs and developers but also be a win for compliance teams.”
As another example, Hill suggests that e-commerce SEOs could use the custom extraction tools to check the inventory amounts on product description pages (PDPs).
“These are things that can be tested for and serve all stakeholders who work with the web property,” he says.
“Using these features is a great way, I think, to look at SEO in 2024. Focus on a more proactive strategy vs. just using the standard ‘crawl and check’ methodology. Because as we know, new releases are always going to happen; there are always going to be things that can go funky on a website. So the more that we can mitigate using tools like Lumar’s Protect is going to save so much time and effort, both pre-production and post-production.”

Don’t miss the next Lumar webinar!
Sign up for our newsletter below to get alerted about upcoming webinars, or give us a follow on LinkedIn or Twitter/X.
Want even more on-demand SEO webinars? Explore the full library of Lumar SEO webinar content.





